Download as PDF, PPTX


![7
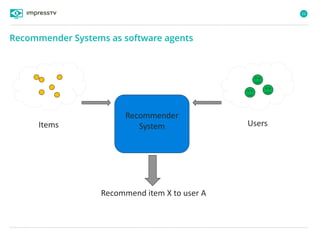
„Recommender Systems (RS) are software agents that elicit the interests and
preferences of individual consumers […] and make recommendations
accordingly. They have the potential to support and improve the quality of the
decisions consumers make while searching for and selecting products online.„ 1
What are Recommender Systems?
1 Xiao, Bo, and Izak Benbasat, 2007, E-commerce product recommendation agents: Use, characteristics, and
impact, Mis Quarterly 31, 137-209.
Recommender Systems](https://image.slidesharecdn.com/introduction-to-recommender-systems-david-zibriczky-20141204-pub-160219114326/85/An-introduction-to-Recommender-Systems-7-320.jpg)
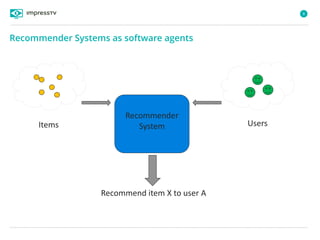
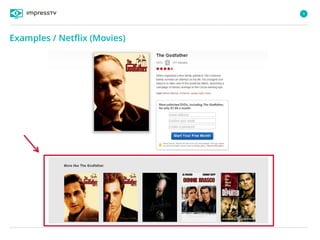
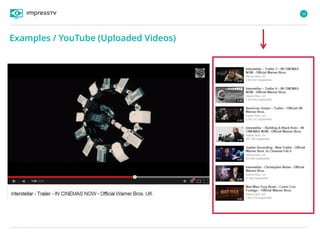
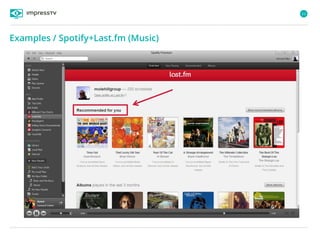
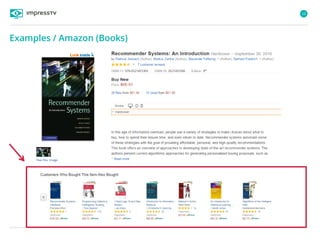
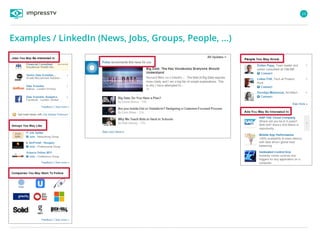
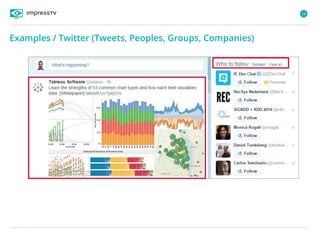
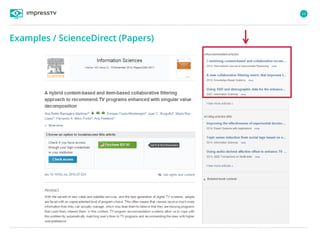
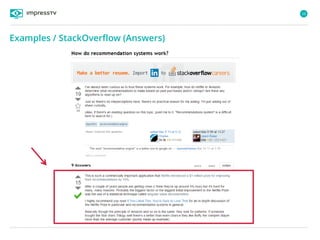
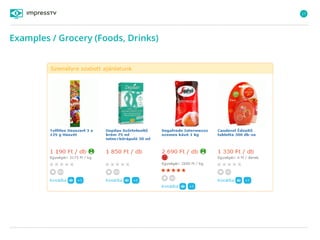




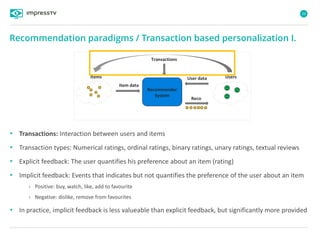
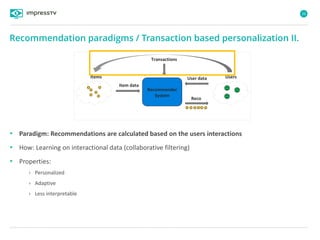
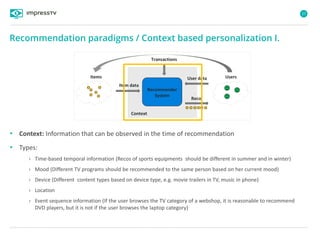
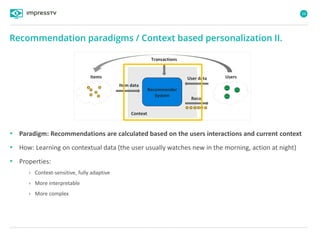
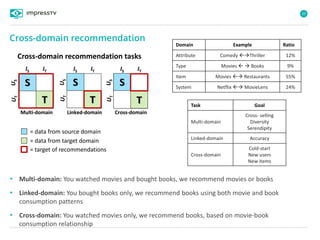
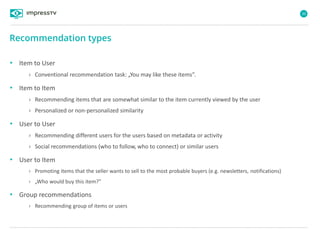
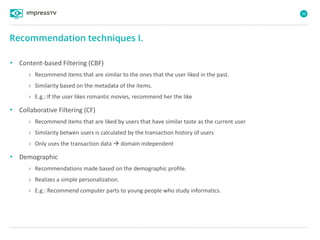



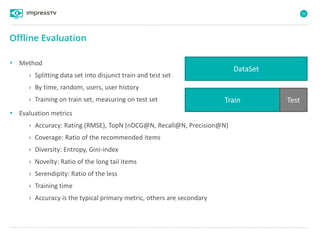


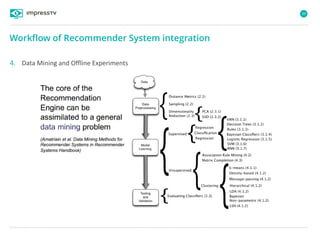


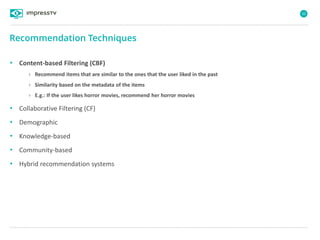
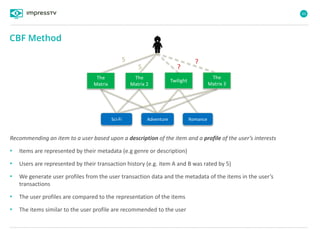


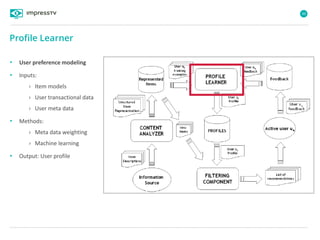

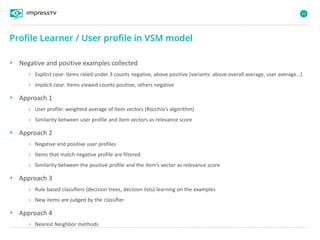


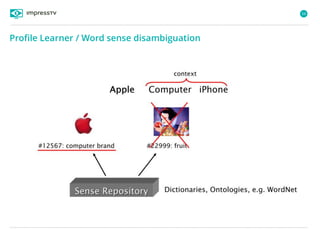
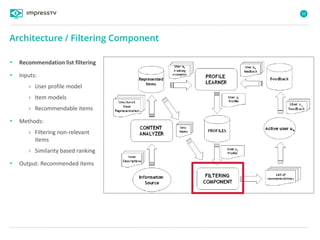





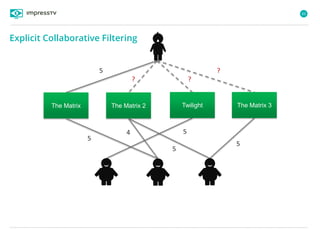
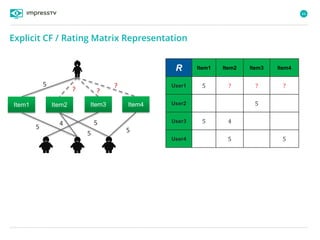

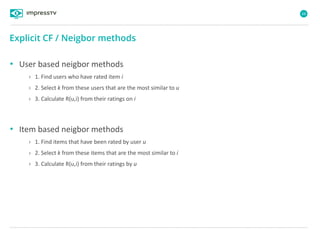



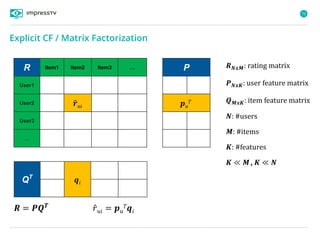

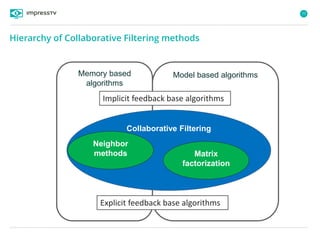

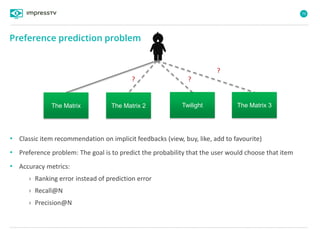
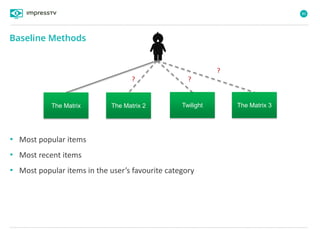
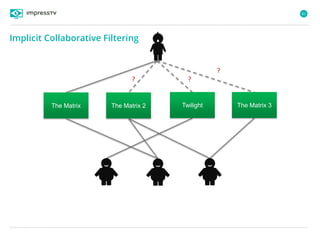
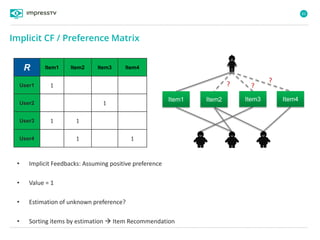


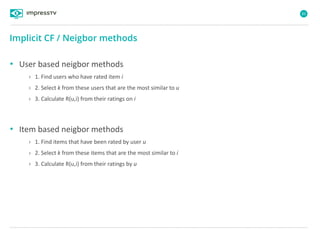


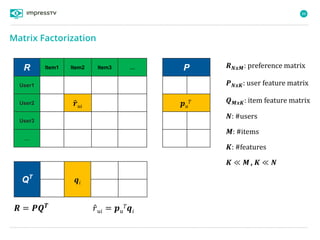
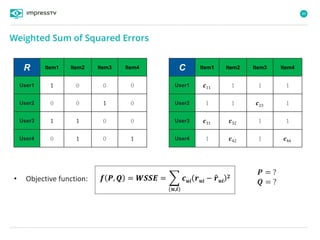
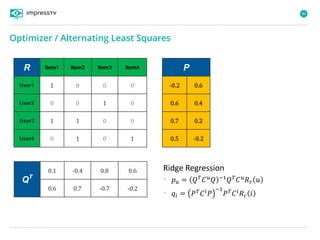
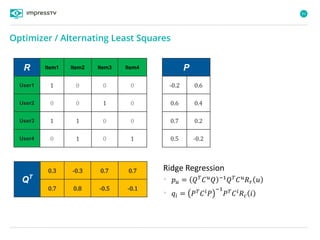
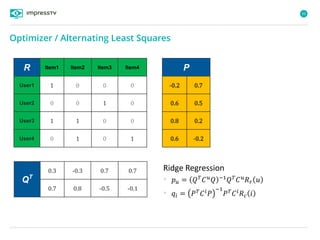


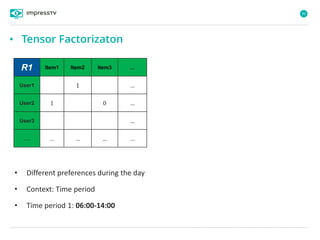

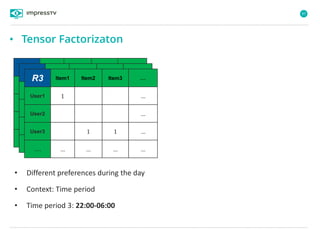



Recommender systems are software agents that analyze a user's preferences through transactions and provide personalized recommendations accordingly. There are several recommendation paradigms including non-personalized rules, personalized rules based on user data, and transaction-based collaborative filtering that learns from user interactions. Context-based recommender systems also consider additional information like time, location, or device to provide adaptive recommendations. Common techniques used in recommender systems include content-based filtering that recommends similar items, collaborative filtering that finds users with similar tastes, and demographic-based recommendations.



































![[livecast] Personalization on the Web](https://cdn.slidesharecdn.com/ss_thumbnails/livecastpersonalizingweb1-110203105405-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)










