Download as PDF, PPTX








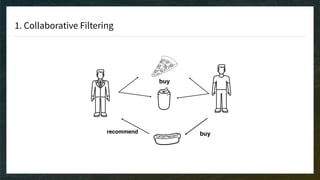




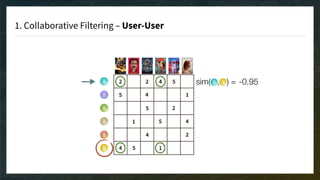


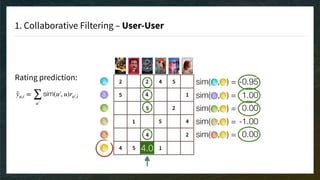




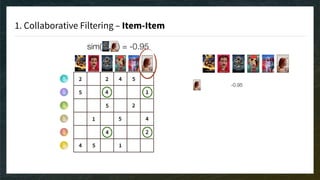
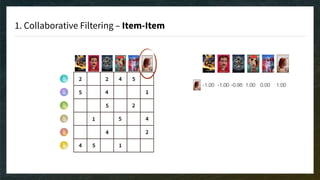











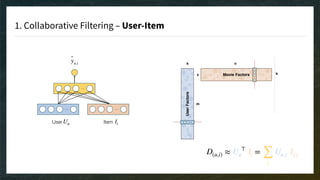










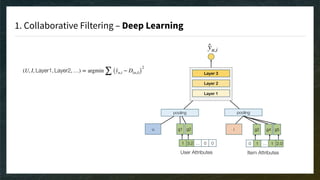


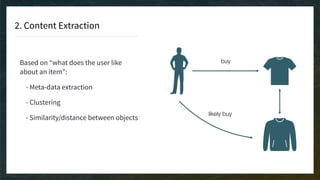







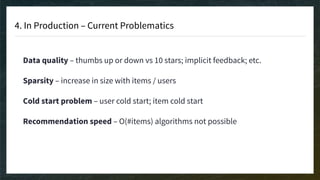

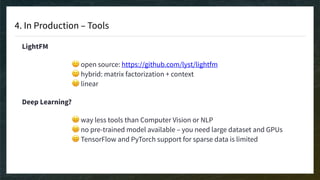

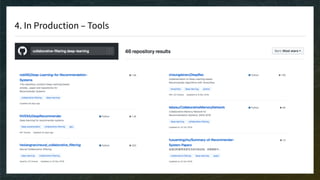



The document discusses recommendation engines, emphasizing the importance of addressing choice overload through collaborative filtering, content-based, and hybrid models. It highlights the challenges faced by collaborative filtering methods, such as sparsity and scalability, while proposing solutions to improve recommendation quality and performance. Additionally, it touches on current problems in production, including data quality, cold starts, and recommendation speed, along with potential tools to enhance these systems.



































































