Download to read offline



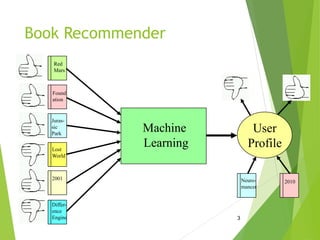






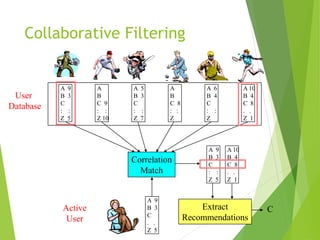















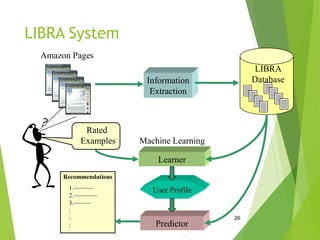







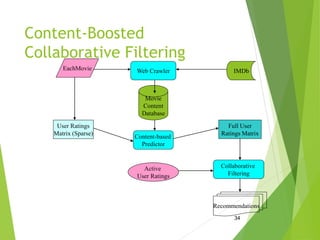


Recommender systems aim to recommend items like books, movies, or products to users based on their preferences. There are two main approaches: collaborative filtering, which recommends items liked by similar users, and content-based filtering, which recommends items similar to those a user has liked based on item attributes. Both have strengths and weaknesses, so hybrid systems combining the approaches can provide the best recommendations.




































![[系列活動] 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/merged-161217165734-thumbnail.jpg?width=640&height=640&fit=bounds)






























