Downloaded 54 times














![KMeansEx: KMeans with MLListener
case class KMeansCoreStats (iteration: Int, centers: Array[Vector], cost: Double )
private def runAlgorithm(data: RDD[VectorWithNorm]): KMeansModel = {
...
while (!stopIteration &&
iteration < maxIterations && !activeRuns.isEmpty) {
...
if (listenerEnabled()) {
sendMessage(KMeansCoreStats(…))
}
...
}
}](https://image.slidesharecdn.com/june29500goprochenv2-160711212709/85/Real-Time-Machine-Learning-Visualization-with-Spark-22-320.jpg)
![KMeans ML Listener
class KMeansListener(columnNames: List[String],
data : RDD[Vector],
logger : MessageLogger) extends MLListener{
var sampleDataOpt : Option[Array[Vector]]= None
override def onMessage(message : => Any): Unit = {
message match {
case coreStats :KMeansCoreStats =>
if (sampleDataOpt.isEmpty)
sampleDataOpt = Some(data.takeSample(withReplacement = false, num=100))
//use the KMeans model of the current iteration to predict sample cluster indexes
val kMeansModel = new KMeansModel(coreStats.centers)
val cluster=sampleDataOpt.get.map(vector => (vector.toArray, kMeansModel.predict(vector)))
val msg = KMeansStats(…)
logger.sendBroadCastMessage(MLConstants.KMEANS_CENTER, msg)
case _ =>
println(" message lost")
}](https://image.slidesharecdn.com/june29500goprochenv2-160711212709/85/Real-Time-Machine-Learning-Visualization-with-Spark-23-320.jpg)
![KMeans Spark Job Setup
Val appCtxOpt : Option[ApplicationContext] = …
val kMeans = new KMeansExt().setK(numClusters)
.setEpsilon(epsilon)
.setMaxIterations(maxIterations)
.enableListener(enableVisualization)
.addListener(
new KMeansListener(...))
appCtxOpt.foreach(_.addTaskObserver(new MLTaskObserver(kMeans,logger)))
kMeans.run(vectors)](https://image.slidesharecdn.com/june29500goprochenv2-160711212709/85/Real-Time-Machine-Learning-Visualization-with-Spark-24-320.jpg)

![Logistic Regression MLListener
class LogisticRegression(…) extends MLListenerSupport {
def train(data: RDD[(Double, Vector)]): LogisticRegressionModel= {
// initialization code
val (rawWeights, loss) = OWLQN.runOWLQN( …)
generateLORModel(…)
}
}](https://image.slidesharecdn.com/june29500goprochenv2-160711212709/85/Real-Time-Machine-Learning-Visualization-with-Spark-26-320.jpg)
![Logistic Regression MLListener
object OWLQN extends Logging {
def runOWLQN(/*args*/,mlSupport:Option[MLListenerSupport]):(Vector,
Array[Double]) = {
val costFun=new CostFun(data, mlSupport, IterationState(), /*other
args */)
val states : Iterator[lbfgs.State] =
lbfgs.iterations(
new CachedDiffFunction(costFun), initialWeights.toBreeze.toDenseVector
)
…
}](https://image.slidesharecdn.com/june29500goprochenv2-160711212709/85/Real-Time-Machine-Learning-Visualization-with-Spark-27-320.jpg)
![Logistic Regression MLListener
In Cost function :
override def calculate(weights: BDV[Double]): (Double, BDV[Double]) = {
val shouldStop = mlSupport.exists(_.stopIteration)
if (!shouldStop) {
…
mlSupport.filter(_.listenerEnabled()).map { s=>
s.sendMessage( (iState.iteration, w, loss))
}
…
}
else {
…
}
}](https://image.slidesharecdn.com/june29500goprochenv2-160711212709/85/Real-Time-Machine-Learning-Visualization-with-Spark-28-320.jpg)





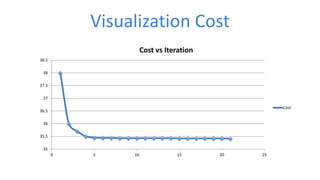
![Use Plot.ly to render graph
function showCost(dataParsed) {
var costTrace = { … };
var data = [ costTrace ];
var costLayout = {
xaxis: {…},
yaxis: {…},
title: …
};
Plotly.newPlot('cost', data, costLayout);
}](https://image.slidesharecdn.com/june29500goprochenv2-160711212709/85/Real-Time-Machine-Learning-Visualization-with-Spark-39-320.jpg)



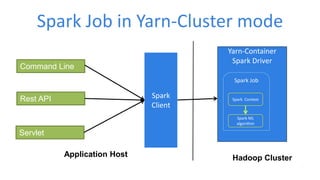
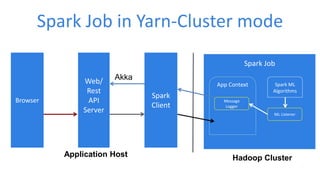
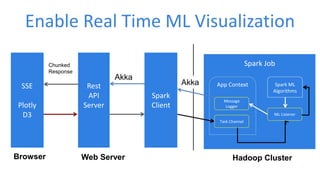
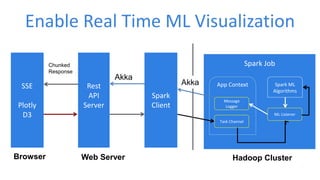
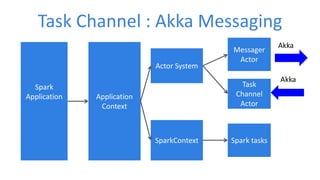
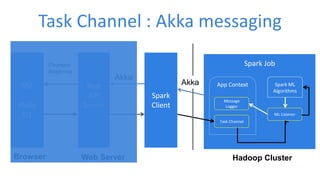
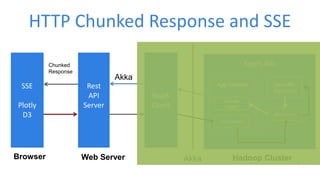
This document discusses enabling real-time machine learning visualization with Spark. It presents a callback interface for Spark ML algorithms to send messages during training and a task channel to deliver messages from the Spark driver to a client. The messages are pushed to a browser using server-sent events and HTTP chunked responses. This allows visualizing training metrics, determining early stopping, and monitoring algorithm convergence in real time.











































































































