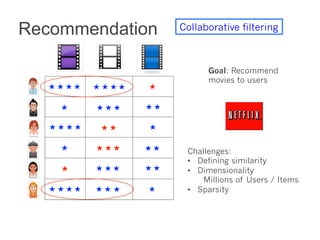
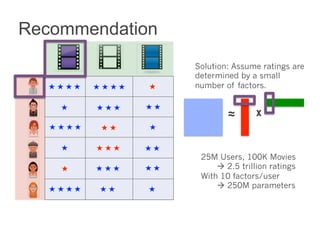
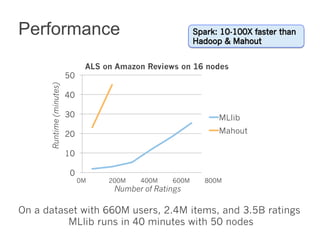
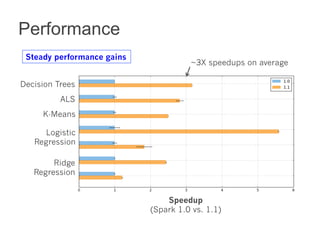
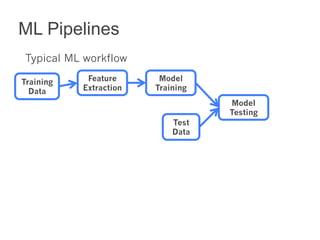
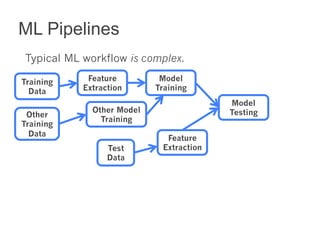
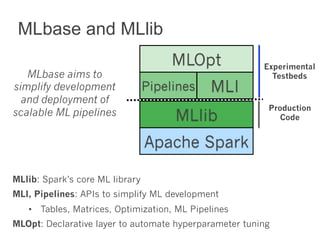
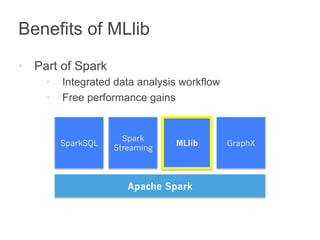
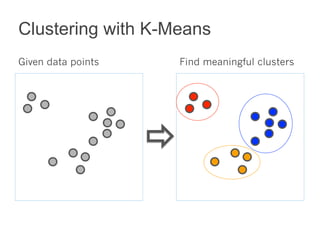
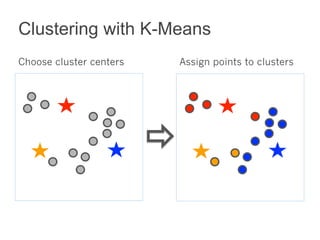
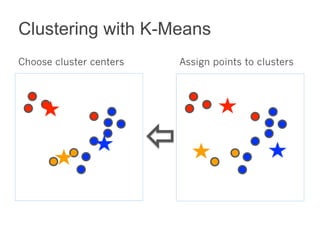
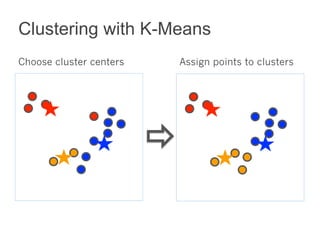
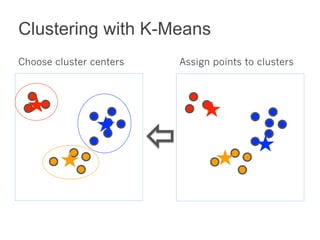
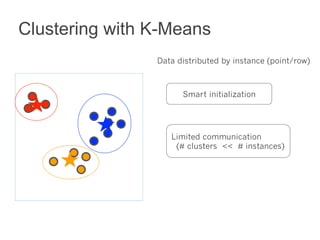
This document summarizes the history and ongoing development of MLlib, Spark's machine learning library. MLlib was initially developed by the MLbase team in 2013 and has since grown significantly with over 80 contributors. It provides algorithms for classification, regression, clustering, collaborative filtering, and linear algebra/optimization. Recent improvements include new algorithms like random forests, pipelines for simplified ML workflows, and continued performance gains.









![K-Means: Python
# Load and parse data.
data = sc.textFile("kmeans_data.txt")
parsedData = data.map(lambda line:
array([float(x) for x in line.split(' ‘)])).cache()
# Cluster data into 5 classes using KMeans.
clusters = KMeans.train(parsedData, k = 5, maxIterations = 20)
# Evaluate clustering error.
def error(point):
center = clusters.centers[clusters.predict(point)]
return sqrt(sum([x**2 for x in (point - center)]))
cost = parsedData.map(lambda point: error(point))
.reduce(lambda x, y: x + y)
print("Sum of squared error = " + str(cost))](https://image.slidesharecdn.com/xjuvc7sws36gxswu0kts-signature-9f1097b540f1c004e6501073d62b3a70af4704a05c67c402ba256f1c4f6d4951-poli-141121183156-conversion-gate02/85/MLlib-Spark-s-Machine-Learning-Library-17-320.jpg)