Downloaded 236 times








![17 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Apache Zeppelin: Authorization
Note level authorization
Grant Permissions (Owner, Reader, Writer)
to users/groups on Notes
LDAP Group integration
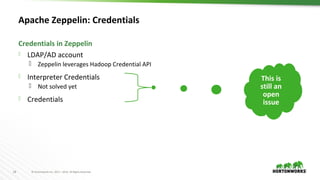
Zeppelin UI Authorization
Allow only admins to configure interpreter
Configured in shiro.ini
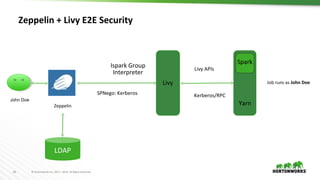
For Spark with Zeppelin > Livy > Spark
– Identity Propagation Jobs run as End-User
For Hive with Zeppelin > JDBC interpreter
Shell Interpreter
– Runs as end-user
Authorization in Zeppelin Authorization at Data Level
[urls]
/api/interpreter/** = authc, roles[admin]
/api/configurations/** = authc, roles[admin]
/api/credential/** = authc, roles[admin]](https://image.slidesharecdn.com/sparkzeppelininproduction-vinayshukla-171201212915/85/Running-Apache-Spark-Apache-Zeppelin-in-Production-17-320.jpg)
![19 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Apache Zeppelin: AD Authentication
1. /etc/zeppelin/conf/shiro.ini
[urls]
/api/version = anon
/** = authc
Configure Zeppelin to Authenticate users
Zeppelin leverages
Apache Shiro for
authentication/authoriza
tion](https://image.slidesharecdn.com/sparkzeppelininproduction-vinayshukla-171201212915/85/Running-Apache-Spark-Apache-Zeppelin-in-Production-19-320.jpg)








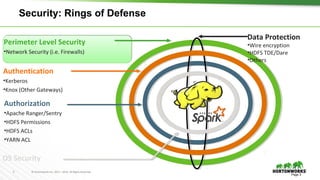
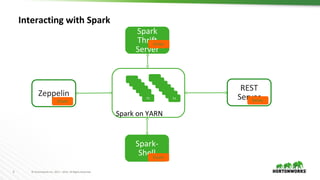
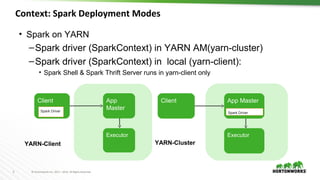
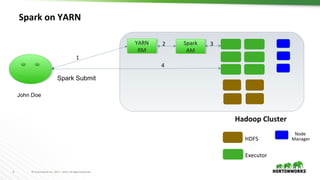
This document discusses running Apache Spark and Apache Zeppelin in production. It begins by introducing the author and their background. It then covers security best practices for Spark deployments, including authentication using Kerberos, authorization using Ranger/Sentry, encryption, and audit logging. Different Spark deployment modes like Spark on YARN are explained. The document also discusses optimizing Spark performance by tuning executor size and multi-tenancy. Finally, it covers security features for Apache Zeppelin like authentication, authorization, and credential management.























































































