Downloaded 77 times
















![© 2017 MapR Technologies
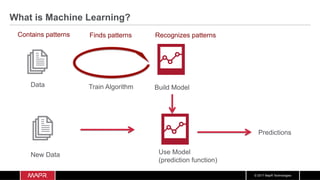
Spark Distributed Datasets
Dataset
W
Executor
P4
W
Executor
P1 P3
W
Executor
P2
partitioned
Partition 1
8213034705, 95,
2.927373,
jake7870, 0……
Partition 2
8213034705,
115, 2.943484,
Davidbresler2,
1….
Partition 3
8213034705,
100, 2.951285,
gladimacowgirl,
58…
Partition 4
8213034705,
117, 2.998947,
daysrus, 95….
• Read only collection of typed objects
Dataset[T]
• Partitioned across a cluster
• Operated on in parallel
• in memory can be Cached](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-40-320.jpg)
![© 2017 MapR Technologies
Example loading a Dataset
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count Worker
Worker
Worker
Driver
Block 1
Block 2
Block 3](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-41-320.jpg)
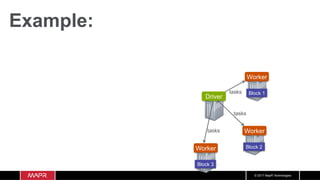


![© 2017 MapR Technologies
Example:
Worker
Worker
Worker
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
results
results
results
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
res9: Long = 829275](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-45-320.jpg)
![© 2017 MapR Technologies
Example
Worker
Worker
Worker
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-46-320.jpg)
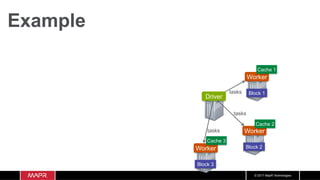
![© 2017 MapR Technologies
Example: Log Mining
Worker
Worker
Worker
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
Driver
Process
from
Cache
Process
from
Cache
Process
from
Cache
Cached, does
not have to read
from file again
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-48-320.jpg)
![© 2017 MapR Technologies
Example:
Worker
Worker
Worker
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
Driver
results
results
results
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-49-320.jpg)
![© 2017 MapR Technologies
Example:
Worker
Worker
Worker
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
Driver
Cache your data è Faster Results
val df: Dataset[Uber] = spark.read.option("inferSchema",
"false").schema(schema).csv(“data/uber.csv").as[Uber]
df.cache
df.count
df.show](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-50-320.jpg)





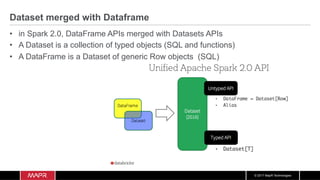

![© 2017 MapR Technologies
Dataset
Load data
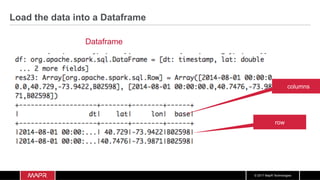
Load the data into a Dataset
case class Uber(dt: String, lat: Double, lon: Double, base: String) extends Serializable
val schema = StructType(Array(
StructField("dt", TimestampType, true),
StructField("lat", DoubleType, true),
StructField("lon", DoubleType, true),
StructField("base", StringType, true)
))
val df = spark.read.option("inferSchema", "false").schema(schema)
.csv("/user/user01/data/uber.csv") .as[Uber]
df.show](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-61-320.jpg)
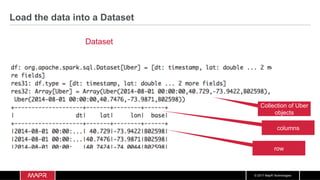



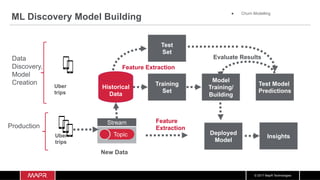
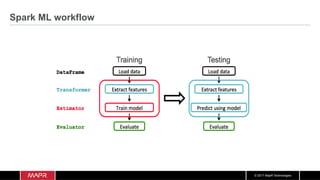
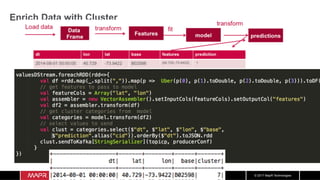
![© 2017 MapR Technologies
Data
Frame
Load data transform
Estimator
model.clusterCenters.foreach(println)
[40.76930621976264,-73.96034885367698]
[40.67562793272868,-73.79810579052476]
[40.68848772848041,-73.9634449047477]
[40.78957777777776,-73.14270740740741]
[40.32418330308531,-74.18665245009073]
[40.732808848486286,-74.00150153727878]
[40.75396549974632,-73.57692359208531]
[40.901700842900674,-73.868760398198]
Clusters from fitted model
DataFrame +
Features
fit fitted
model
input](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-68-320.jpg)





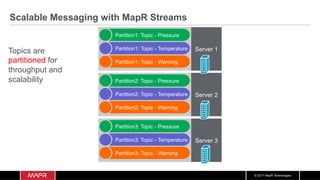
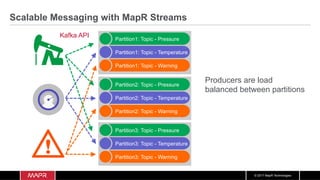
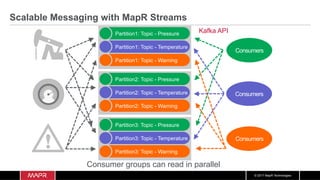
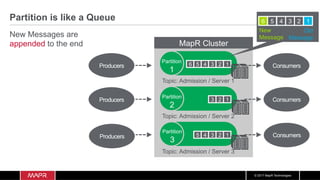



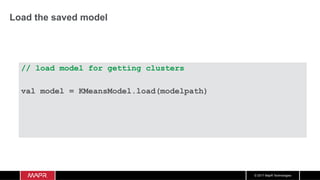
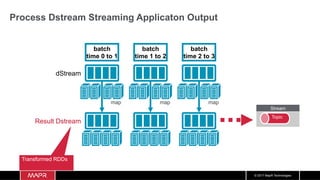
![© 2017 MapR Technologies
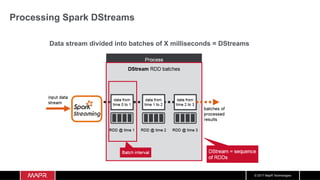
Create a DStream
DStream: a sequence of RDDs
representing a stream of data
val messagesDStream = KafkaUtils.createDirectStream[String,String]
(ssc, LocationStrategies.PreferConsistent,consumerStrategy)
// get message values from key,value and parse to Uber objects
val uDStream = linesDStream.map(_.value())
batch
time 0 to 1
batch
time 1 to 2
batch
time 2 to 3
dStream
Stored in memory
as an RDD](https://image.slidesharecdn.com/machinelearningiotrealtimepipeline-180417193640/85/Streaming-Machine-learning-Distributed-Pipeline-for-Real-Time-Uber-Data-Using-Apache-APIs-Kafka-Spark-HBase-93-320.jpg)



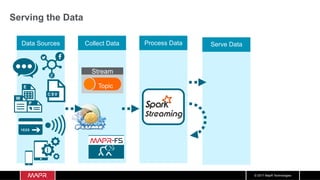
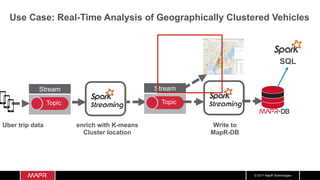
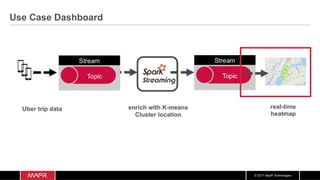
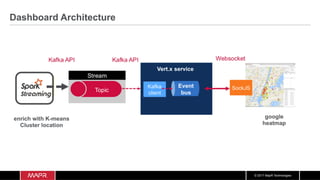
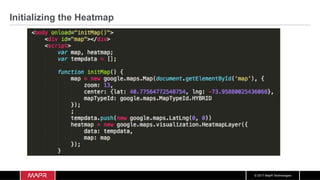
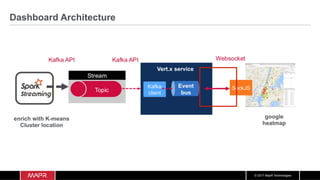
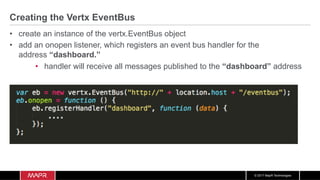
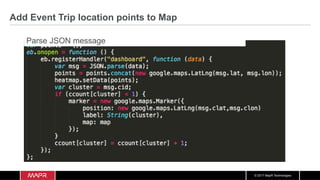
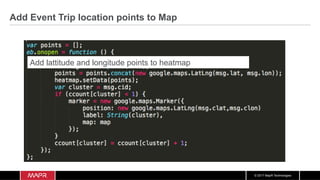
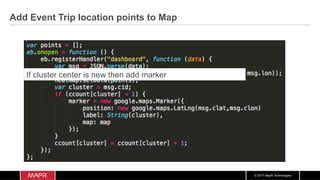


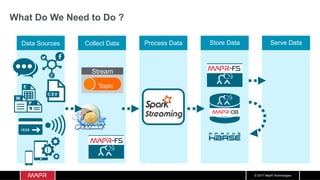
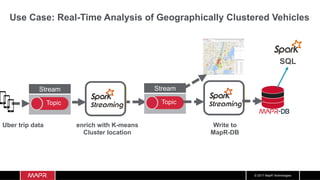
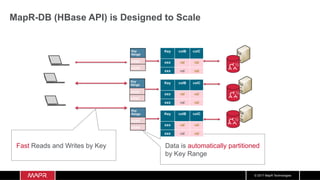
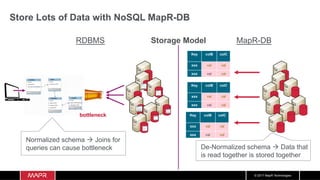

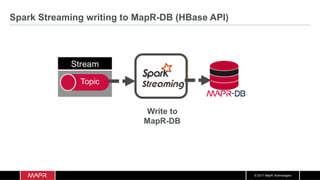
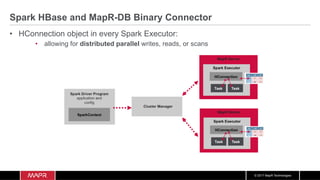
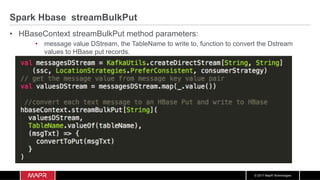
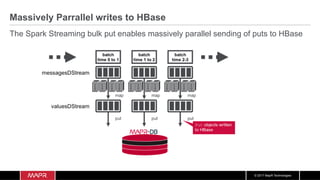






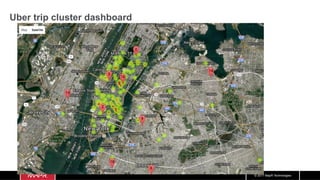
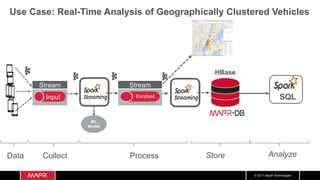
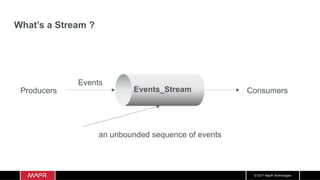
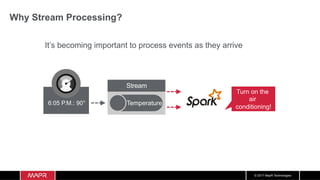
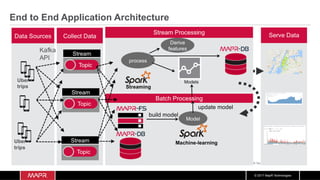
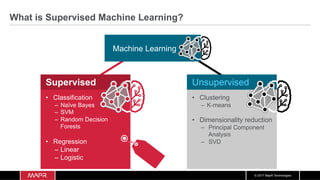
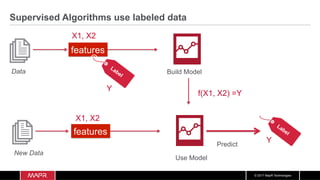
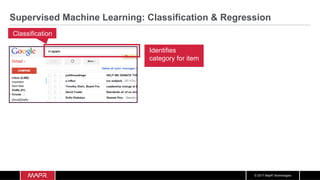
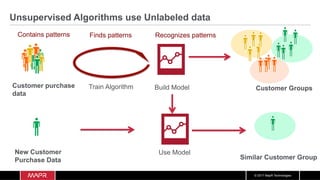
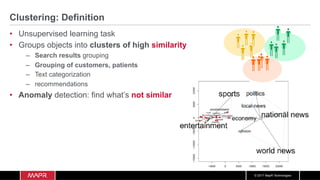
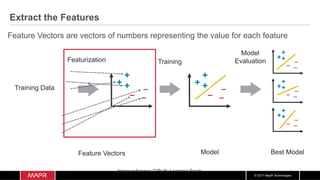
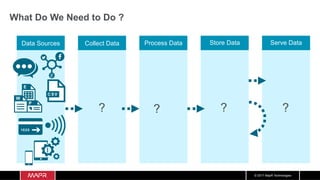
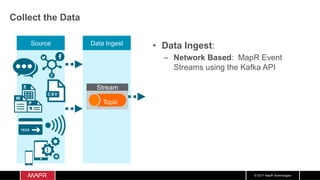
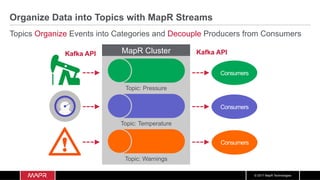
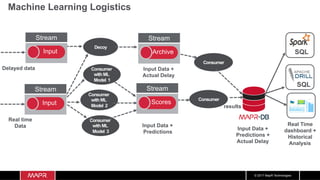
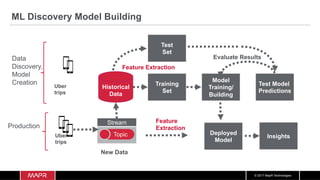
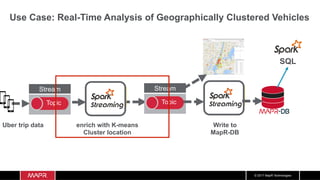
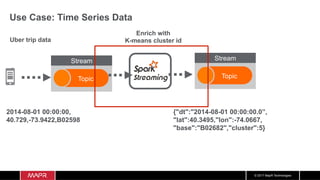
The document discusses the integration of machine learning with IoT and streaming data, specifically in the context of analyzing Uber trip data using Apache technologies such as Kafka and Spark. It covers key concepts of machine learning, including supervised and unsupervised learning, and provides an end-to-end architecture for processing real-time data. The document also illustrates practical use cases and offers examples of implementing Spark ML for monitoring and clustering Uber data.














































































