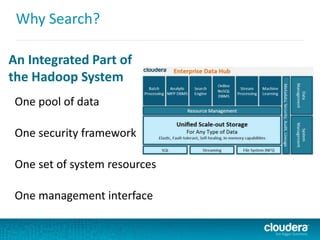
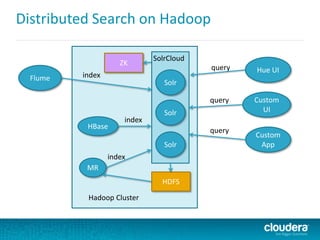
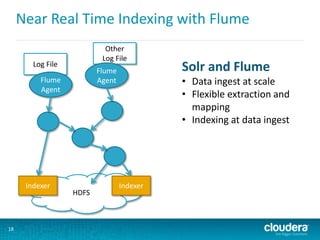
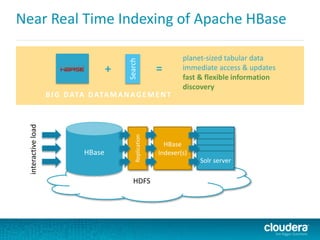
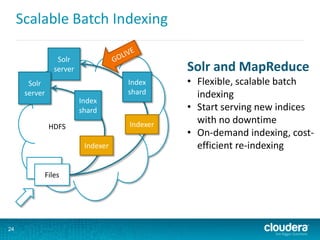
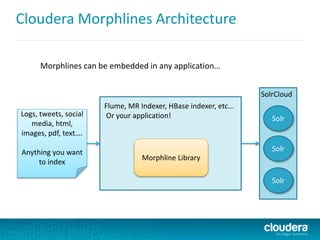
This document discusses Cloudera Search, which integrates Apache Solr with Cloudera's distribution of Apache Hadoop (CDH) to provide interactive search capabilities. It describes the architecture of Cloudera Search, including components like Solr, SolrCloud, and Morphlines for extraction and transformation. Methods for indexing data in real-time using Flume or batch using MapReduce are presented. The document also covers querying, security features like Kerberos authentication and collection-level authorization using Sentry, and concludes by describing how to obtain Cloudera Search.
























![Morphline Example – syslog with grok
morphlines : [
{
id : morphline1
importCommands : ["com.cloudera.**", "org.apache.solr.**"]
commands : [
{ readLine {} }
{
grok {
dictionaryFiles : [/tmp/grok-dictionaries]
expressions : {
message : """<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp}
%{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:[%{POSINT:syslog_pid}])?:
%{GREEDYDATA:syslog_message}"""
}
}
}
{ loadSolr {} }
]
}
]
Example Input
<164>Feb 4 10:46:14 syslog sshd[607]: listening on 0.0.0.0 port 22
Output Record
syslog_pri:164
syslog_timestamp:Feb 4 10:46:14
syslog_hostname:syslog
syslog_program:sshd
syslog_pid:607
syslog_message:listening on 0.0.0.0 port 22.](https://image.slidesharecdn.com/searchonhadoopocbigdata-140716234914-phpapp01/85/Solr-Hadoop-Interactive-Search-for-Hadoop-33-320.jpg)








![Policy File
[groups]
# Assigns each Hadoop group to its set of roles
dev_ops = engineer_role, ops_role
[roles]
# Assigns each role to its set of privileges
engineer_role = collection = source_code->action=Query,
collection = source_code- > action=Update
ops_role = collection = hbase_logs->action=Query](https://image.slidesharecdn.com/searchonhadoopocbigdata-140716234914-phpapp01/85/Solr-Hadoop-Interactive-Search-for-Hadoop-43-320.jpg)




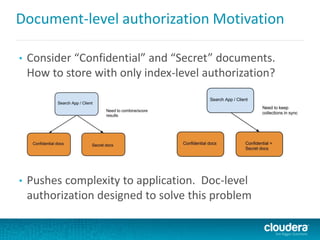
![Document-level authorization model
• Instead of storing in HDFS Policy File:
[groups]
# Assigns each Hadoop group to its set of roles
dev_ops = engineer_role, ops_role
[roles]
# Assigns each role to its set of privileges
engineer_role = collection = source_code->action=Query,
collection = source_code- > action=Update
ops_role = collection = hbase_logs->action=Query
• Store authorization tokens in each document
• Many more documents than collections; doesn’t scale to
store document-level info in Policy File
• Can use Solr’s built-in filtering capabilities to restrict access](https://image.slidesharecdn.com/searchonhadoopocbigdata-140716234914-phpapp01/85/Solr-Hadoop-Interactive-Search-for-Hadoop-49-320.jpg)
![Document-level authorization model
• A configurable token field stores the authorization tokens
• The authorization tokens are Sentry roles, i.e. “ops_role”
[roles]
ops_role = collection = hbase_logs->action=Query
• Represents the roles that are allowed to view the
document. To view a document, the querying user must
belong to at least one role whose token is stored in the
token field
• Can modify document permissions without restarting
Solr
• Can modify role memberships without reindexing](https://image.slidesharecdn.com/searchonhadoopocbigdata-140716234914-phpapp01/85/Solr-Hadoop-Interactive-Search-for-Hadoop-50-320.jpg)











































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)


