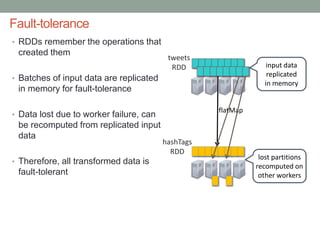
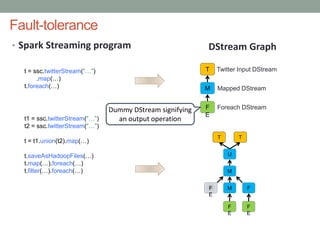
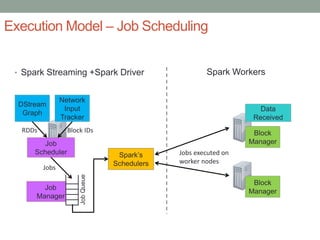
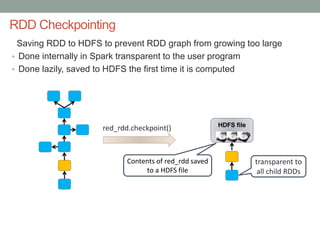
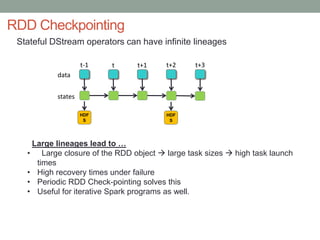
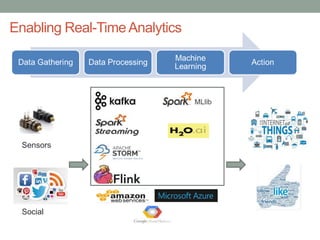
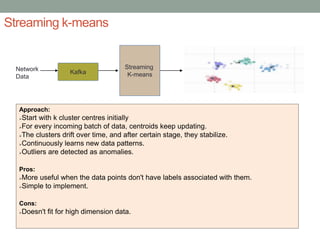
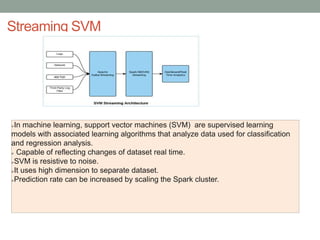
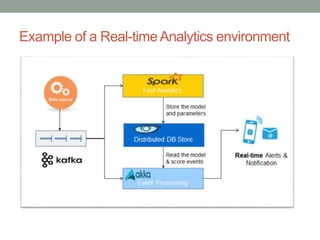
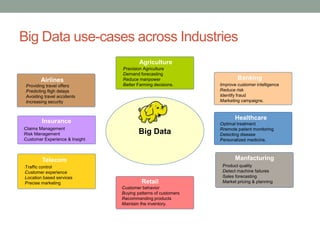
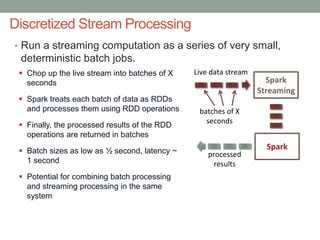
The document discusses real-time streaming analytics and its applications across various industries such as banking, healthcare, and retail, leveraging Apache Spark for processing large volumes of data efficiently. It details the capabilities of Spark Streaming for stateful stream processing, fault tolerance, and the integration of batch and streaming analytics. Additionally, it explores machine learning techniques, including clustering and online learning, emphasizing the importance of real-time data in driving business decisions and innovation.





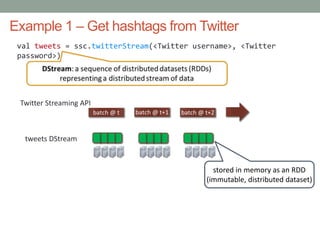
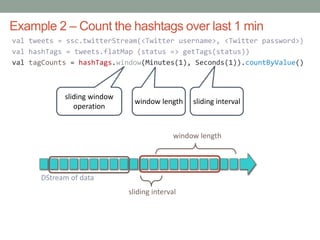
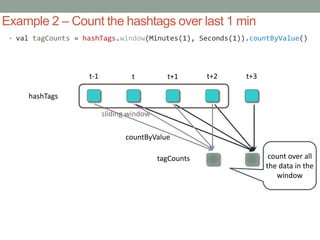
![Example 1 – Get hashtags from Twitter
val tweets = ssc.twitterStream(<Twitter username>, <Twitter
password>)
val hashTags = tweets.flatMap (status => getTags(status))
new DStream
transformation: modify data in one DStream to create
another DStream
batch @ t+1batch @ t batch @ t+2
flatMap flatMap flatMap
hashTags Dstream
[#cat, #dog, … ]
new RDDs created
for every batch
tweets Dstream](https://image.slidesharecdn.com/realtimestreaminganalytics-170403100658/85/Real-time-streaming-analytics-9-320.jpg)