


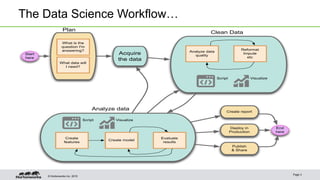






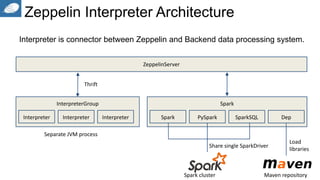
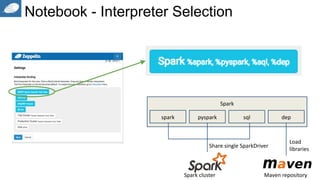



This document discusses Apache Zeppelin, an open-source web-based notebook that allows for interactive data analytics. It can be used for data exploration, visualization, collaboration and publishing. Zeppelin has deep integration with Apache Spark and supports multiple languages including Scala, Python, and SQL. It provides a modern data science studio environment and allows users to easily share code and results. The document demonstrates Zeppelin's capabilities through examples and encourages readers to join the open source community to help shape its development.






















































































