Download as PDF, PPTX
















































![57 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
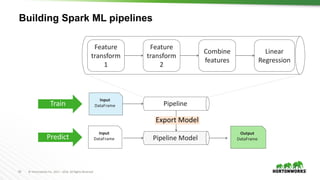
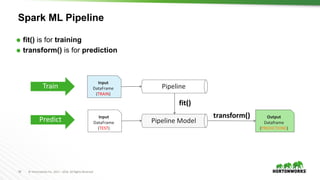
Sample Spark ML Pipeline
indexer = …
parser = …
hashingTF = …
vecAssembler = …
rf = RandomForestClassifier(numTrees=100)
pipe = Pipeline(stages=[indexer, parser, hashingTF, vecAssembler, rf])
model = pipe.fit(trainData) # Train model
results = model.transform(testData) # Test model](https://image.slidesharecdn.com/crashcourse-datascience-munich-public-170412150852/85/Data-Science-Crash-Course-57-320.jpg)








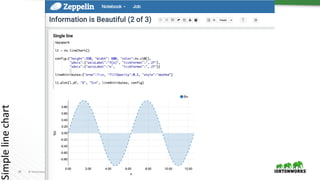
![66 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Scatter 2D Data Visualized
scatterData ç DataFrame
+-----+--------+
|label|features|
+-----+--------+
|-12.0| [-4.9]|
| -6.0| [-4.5]|
| -7.2| [-4.1]|
| -5.0| [-3.2]|
| -2.0| [-3.0]|
| -3.1| [-2.1]|
| -4.0| [-1.5]|
| -2.2| [-1.2]|
| -2.0| [-0.7]|
| 1.0| [-0.5]|
| -0.7| [-0.2]|
...
...
...](https://image.slidesharecdn.com/crashcourse-datascience-munich-public-170412150852/85/Data-Science-Crash-Course-66-320.jpg)
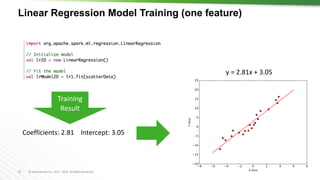
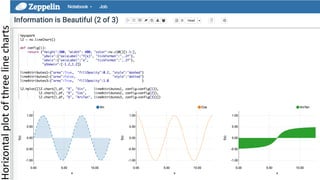
![68 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Linear Regression (two features)
Coefficients: [0.464, 0.464]
Intercept: 0.0563](https://image.slidesharecdn.com/crashcourse-datascience-munich-public-170412150852/85/Data-Science-Crash-Course-68-320.jpg)






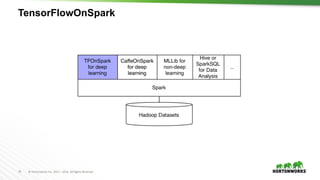



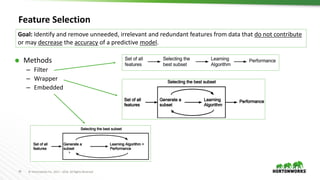













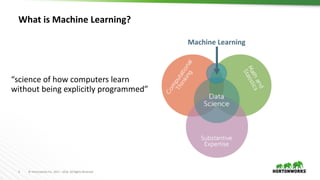
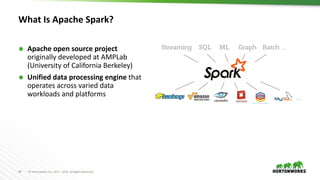
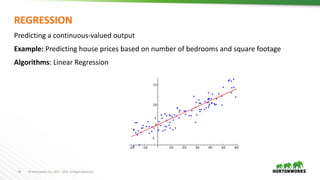
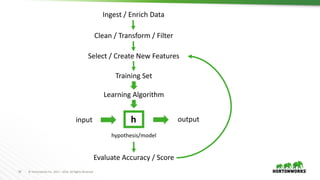
This document provides an overview of data science and machine learning. It discusses what data science and machine learning are, including extracting insights from data and computers learning without being explicitly programmed. It also covers Apache Spark, which is an open source framework for large-scale data processing. Finally, it discusses common machine learning algorithms like regression, classification, clustering, and dimensionality reduction.























































































