More Related Content

PDF
TensorFlow を使った�機械学習ことはじめ (GDG京都 機械学習勉強会) 
PPTX
Pythonとdeep learningで手書き文字認識 
PDF

PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築 
PDF

PDF
TensorFlowの使い方(in Japanese) 
PDF

PDF
Pythonで動かして学ぶ機械学習入門_予測モデルを作ってみよう What's hot

PDF
TensorFlowで機械学習ことはじめ(summer edition) 
PDF

PPT
17ゼロから作るディープラーニング2章パーセプトロン 
PDF
TensorFlowによるニューラルネットワーク入門 
KEY

PDF

PDF

PDF
最近のRのランダムフォレストパッケージ -ranger/Rborist- 
PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PPTX
Deep Learning基本理論とTensorFlow 
PDF
深層学習フレームワーク Chainer の開発と今後の展開 Viewers also liked

PPT

PDF
R入門(dplyrでデータ加工)-TokyoR42 
PDF
20140625 rでのデータ分析(仮) for_tokyor 
PDF

PDF

PDF
20170923 excelユーザーのためのr入門 
PDF

PDF

PPTX

PDF

PDF

PDF

PDF

PDF

PPTX

PDF

PPTX

PPTX

PPTX

PDF
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 - Similar to RとStanでクラウドセットアップ時間を分析してみたら #TokyoR

PDF

PDF

PDF
Tokyo r94 beginnerssession3 
PDF
RStanとShinyStanによるベイズ統計モデリング入門 
PPTX

PDF

PDF
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2 
PDF

PPTX
Feature Selection with R / in JP 
PDF

PDF
MCMCサンプルの使い方 ~見る・決める・探す・発生させる~ 
PPTX
MCMC and greta package社内勉強会用スライド 
PPT

PDF
Rにおける大規模データ解析(第10回TokyoWebMining) 
PDF
R言語で始めよう、データサイエンス(ハンズオン勉強会) 〜機会学習・データビジュアライゼーション事始め〜 
PPT

PDF
Bishop prml 9.3_wk77_100408-1504 
PDF

PDF

PPTX
More from Shuyo Nakatani

PDF
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15 
PDF
Generative adversarial networks 
PDF
無限関係モデル (続・わかりやすいパターン認識 13章) 
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装) 
PDF

PDF
![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl... 
PDF

PDF

PDF
言語処理するのに Python でいいの? #PyDataTokyo 
PDF
Zipf? (ジップ則のひみつ?) #DSIRNLP ![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh... 
PDF

PDF

PDF
アラビア語とペルシャ語の見分け方 #DSIRNLP 5 
PDF
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013 
PDF

PDF
数式を綺麗にプログラミングするコツ #spro2013 
PDF
![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri... RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
- 1.
- 2.
- 3.
- 4.
- 5.
MCMCサンプラーとは
• サイコロの設計図(モデルファイル)を渡す
と、サイコロを作っていっぱい投げてくれる
data {
int<lower=0>N;
int<lower=0> M;
matrix<lower=0,upper=1>[N, M] z;
real<lower=0> jtime[N];
}
parameters {
real mu[M];
real<lower=0> sig[M];
matrix<lower=0>[N, M] y;
real c;
real<lower=0> s;
}
model {
for (n in 1:N) {
jtime[n] ~
normal(c + dot_product(y[n], z[n]), s);
for (m in 1:M) {
y[n, m] ~ lognormal(mu[m], sig[m]);
}
}
// 事前分布
for (m in 1:M) {
mu[m] ~ normal(0, 1);
sig[m] ~ gamma(1, 0.1);
}
c ~ normal(0, 1);
s ~ gamma(1, 1);
}
かなり複雑な
設計図でもOK!
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
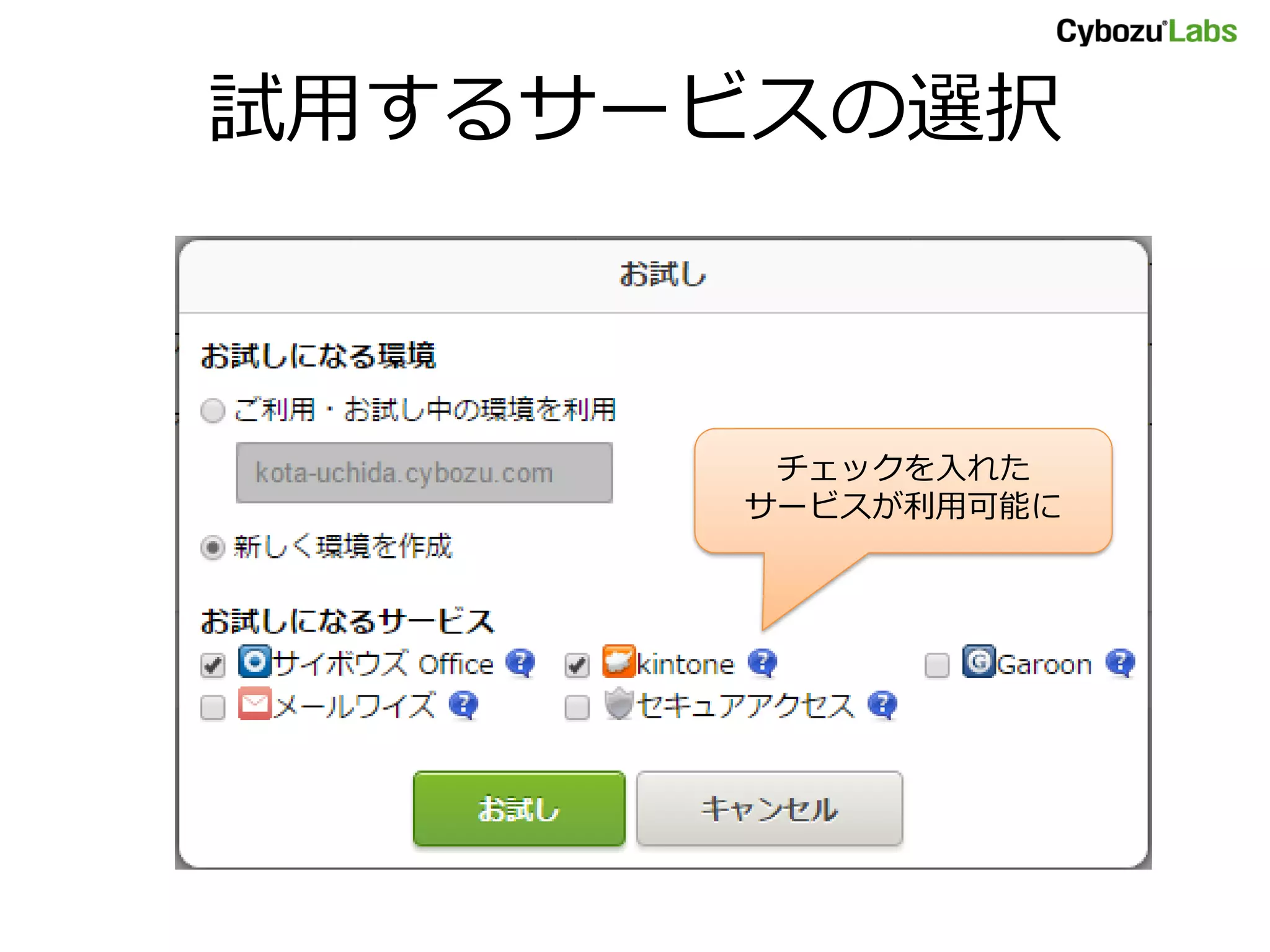
cybozu.com の 5つサービス
•kintone Webデータベース
• サイボウズ ガルーン (garoon)
• サイボウズ オフィス (office)
• メールワイズ (mailwise) メール共有
• セキュアアクセス (skylab)
グループウェア
- 13.
- 14.
- 15.
“village” : 自動セットアップ
•申し込まれたサービスを自動的にセット
アップする仕組み
– 7割のジョブは1分以内にセットアップ完了
– 99% は4分以内
– 0.25% が5分以上
• 「ご発注から5分~10分程度」と歌ってお
り、5分以内が望ましい
- 16.
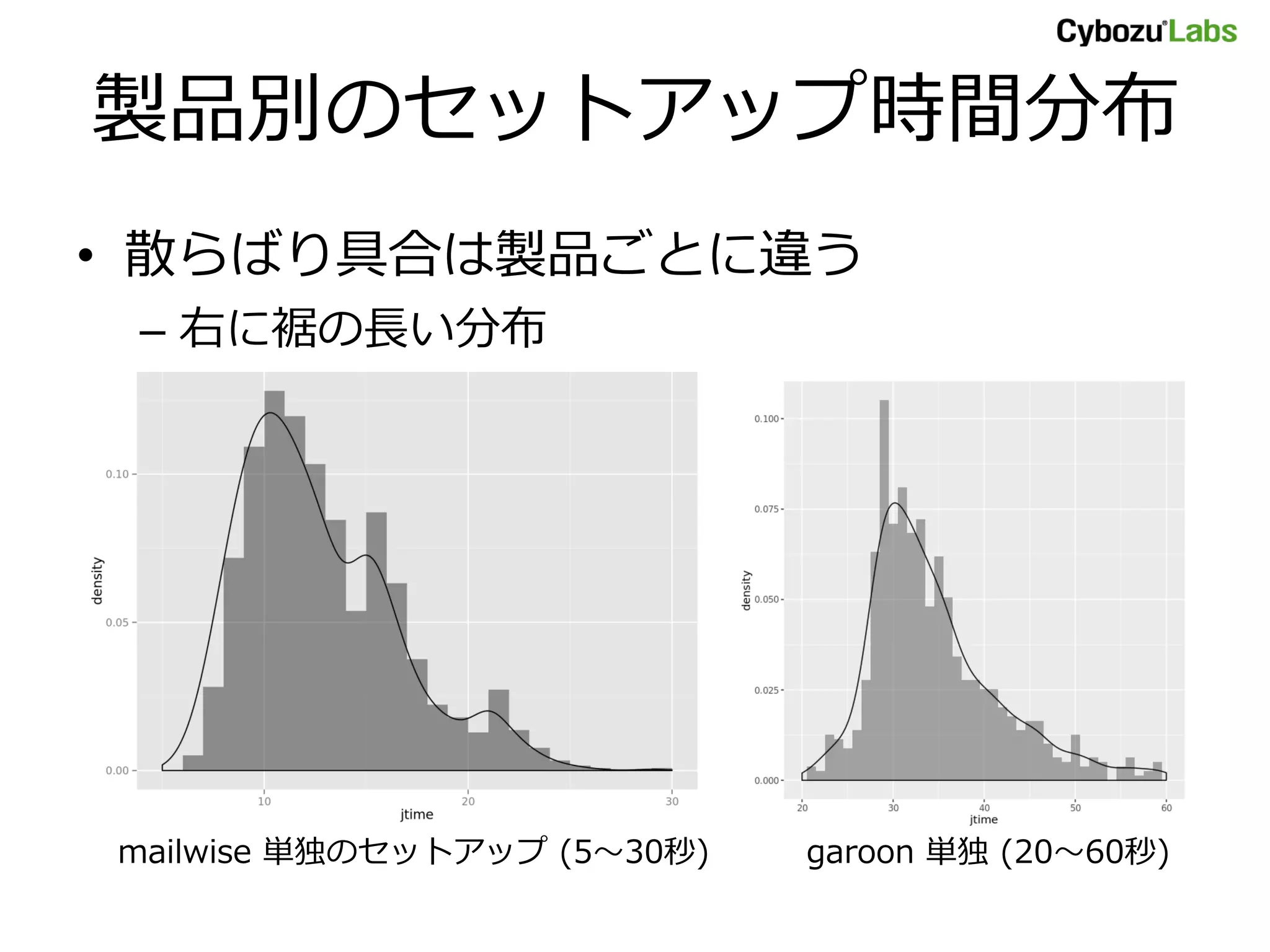
何に時間がかかっている?
• village の履歴ログ(抜粋)
–jtime =そのセットアップジョブの合計実行時間(秒)
– kintone ~ skylab =各サービスがセットアップ対象(=1)
か、対象外(=0)か
• 分析すれば、各サービスごとのセットアップ時間がわ
かる?
> head(village)
jtime kintone garoon office mailwise skylab
1 3.6307 1 0 0 0 0
2 18.1070 0 0 0 1 0
3 13.5170 0 0 1 0 0
4 13.3591 1 0 0 0 1
5 8.7739 0 0 1 0 0
6 2.8032 1 0 0 0 0
kintone と skylab の
セットアップに
13.4秒かかった
- 17.
- 18.
lm 関数で重回帰
> summary(lm(jtime~1+kintone+garoon+office+mailwise+skylab,data=village))
Call:
lm(formula = jtime ~ 1 + kintone + garoon + office + mailwise +
skylab, data = village)
Residuals:
Min 1Q Median 3Q Max
-21.525 -2.746 -1.746 2.254 86.841
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.2244 0.1172 36.04 <2e-16 ***
kintone 1.5214 0.1245 12.22 <2e-16 ***
garoon 31.1726 0.1518 205.32 <2e-16 ***
office 6.7723 0.1223 55.37 <2e-16 ***
mailwise 8.4679 0.1480 57.20 <2e-16 ***
skylab 5.3662 0.1781 30.13 <2e-16 ***
- 19.
分析完了
jtime = 4.2+ 1.5𝑧kintone + 31.2𝑧garoon +
6.8𝑧office + 8.5𝑧mailwise + 5.4𝑧skylab + 𝜖
– 𝑧サービス名はそのサービスを選択していれば 1、非選択なら 0
– office を選択すると6.8秒、skylab を選択すると 5.4秒追加される
• skylab のセットアップは office と同等の時間
– アプリ規模に比べて遅い。高速化はきっと容易だろう……
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.2244 0.1172 36.04 <2e-16 ***
kintone 1.5214 0.1245 12.22 <2e-16 ***
garoon 31.1726 0.1518 205.32 <2e-16 ***
office 6.7723 0.1223 55.37 <2e-16 ***
mailwise 8.4679 0.1480 57.20 <2e-16 ***
skylab 5.3662 0.1781 30.13 <2e-16 ***
- 20.
分析完了?
jtime = 4.2+ 1.5𝑧kintone + 31.2𝑧garoon +
6.8𝑧office + 8.5𝑧mailwise + 5.4𝑧skylab + 𝜖
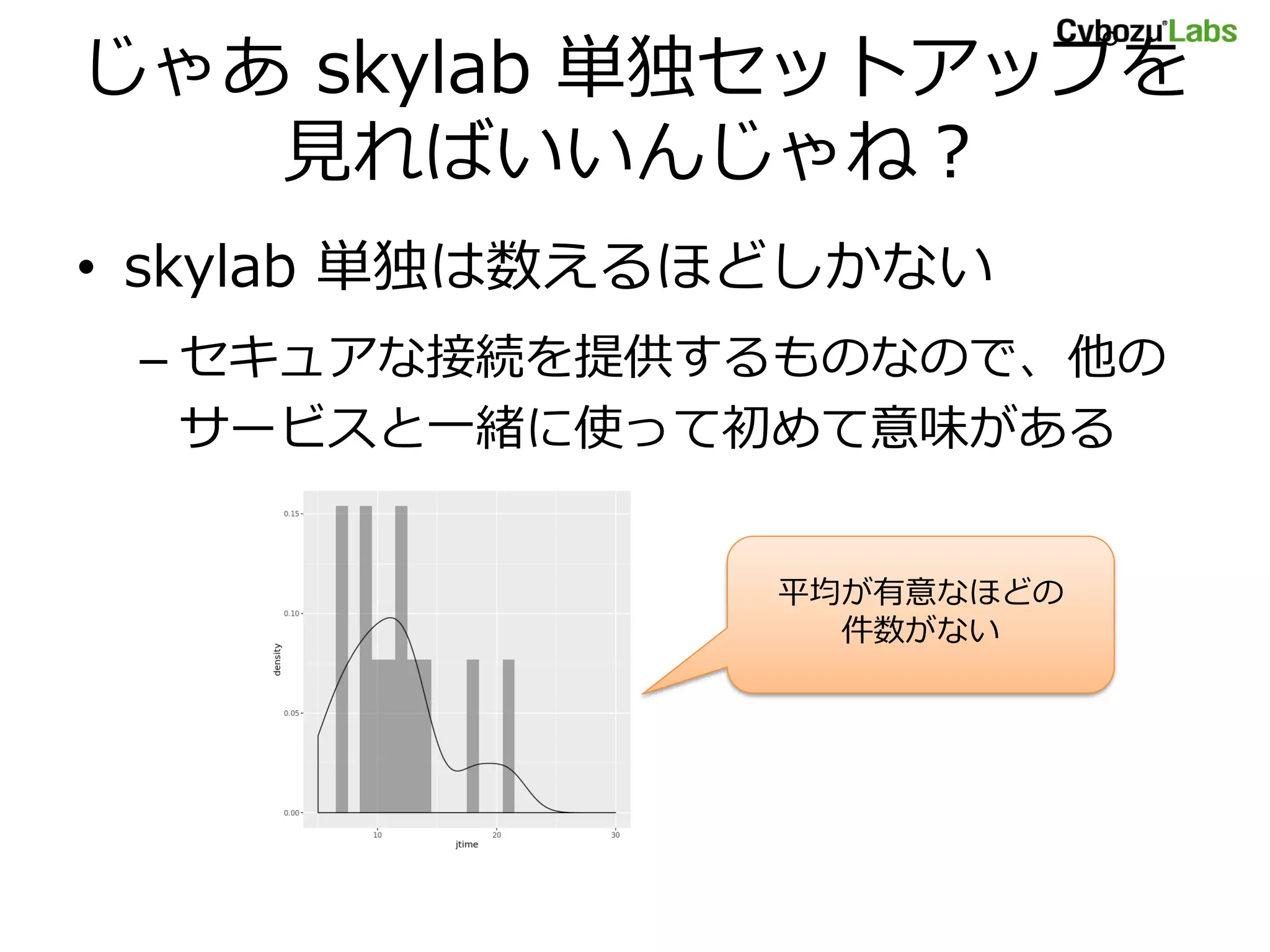
• skylab 遅すぎない?
– アプリの規模がぜんぜん違うのに……
• モデルに問題があるとすれば、
– 残差 𝜖 がサービスによらず共通
• garoon の分散 >>> office の分散 > kintone の分散
• garoon と一緒に選択されることが多い skylab が分散を吸収?
– 右に裾が長い分布なのに、考慮してない
• 残差 𝜖 が大きく負になると、jtime も負に!
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
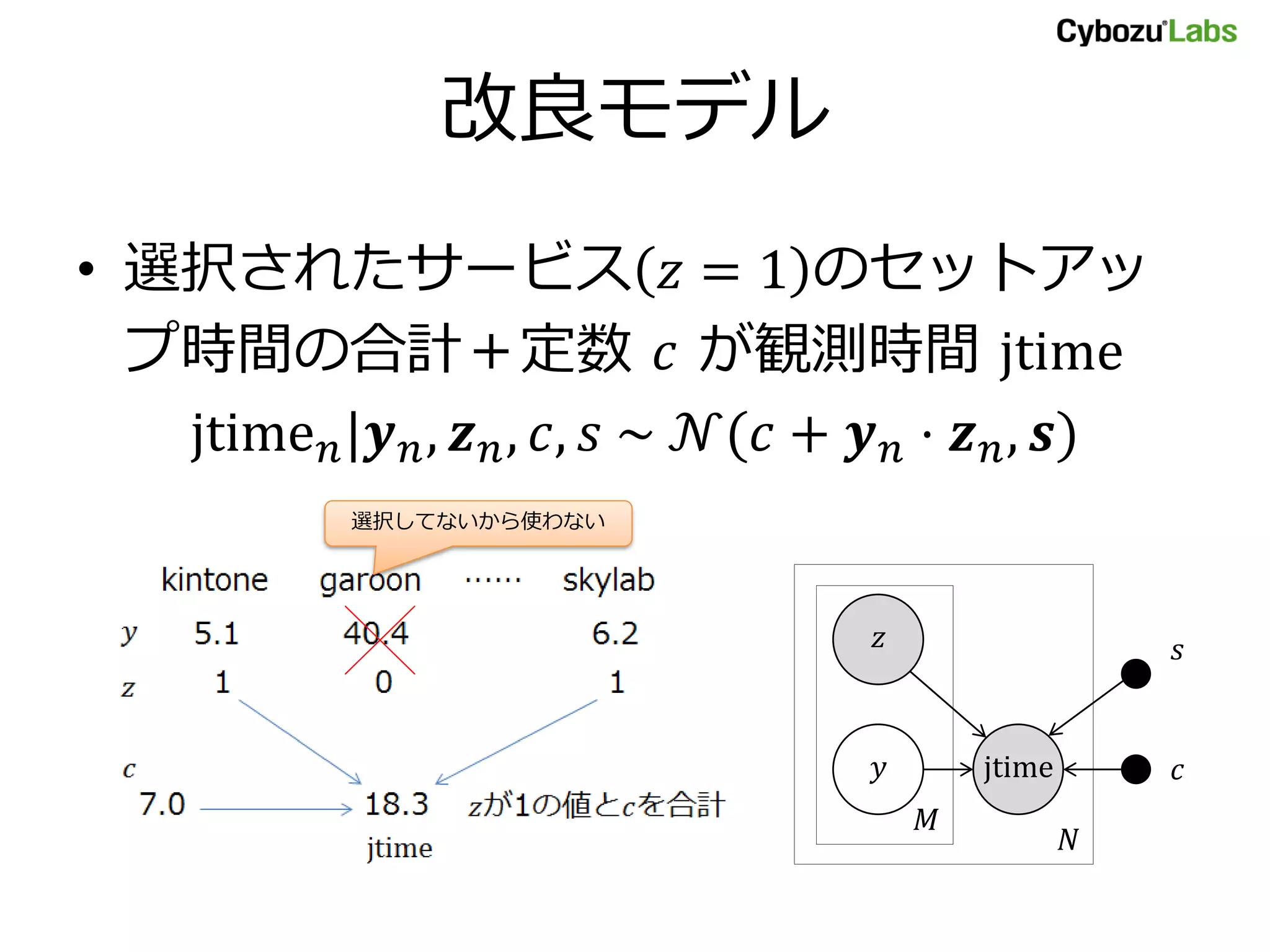
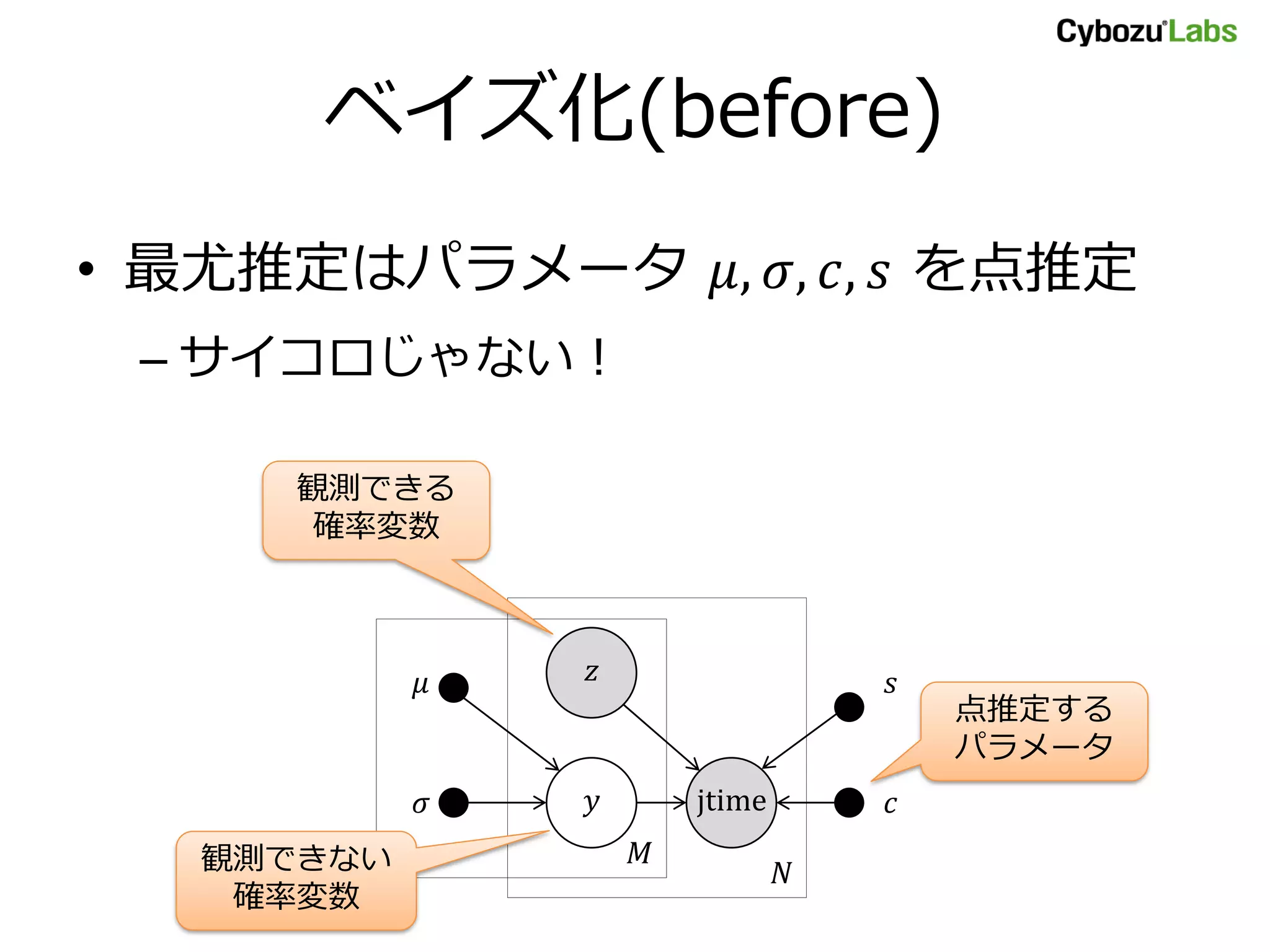
改良モデル
• 選択されたサービス 𝑧= 1 のセットアッ
プ時間の合計+定数 𝑐 が観測時間 jtime
jtime 𝑛|𝒚 𝑛, 𝒛 𝑛, 𝑐, 𝑠 ~ 𝒩(𝑐 + 𝒚 𝑛 ⋅ 𝒛 𝑛, 𝒔)
𝑧
jtime𝑦
𝑁
𝑀
𝑠
𝑐
選択してないから使わない
- 27.
- 28.
でも最尤法では解けない……
• 未観測変数 𝑦を積分消去しないといけない
∫ 𝑃 jtime 𝑧, 𝑦 𝑃 𝑦; 𝜇, 𝜎 𝑑𝑦
• しかも 𝑦 は対数正規分布(←計算が難しいやつ)
𝑃 𝑦; 𝜇, 𝜎 =
1
2𝜋𝜎𝑦
exp −
ln 𝑦 − 𝜇 2
2𝜎2
未観測変数は
積分消去しないと
最尤推定できない
- 29.
- 30.
- 31.
Stan に食わせるには……
• Stanは MCMC サンプラー
– サイコロをいっぱい振ってくれる奴
• 求めたい値がサイコロ(=確率変数)になっ
てないと Stan に食わせられない
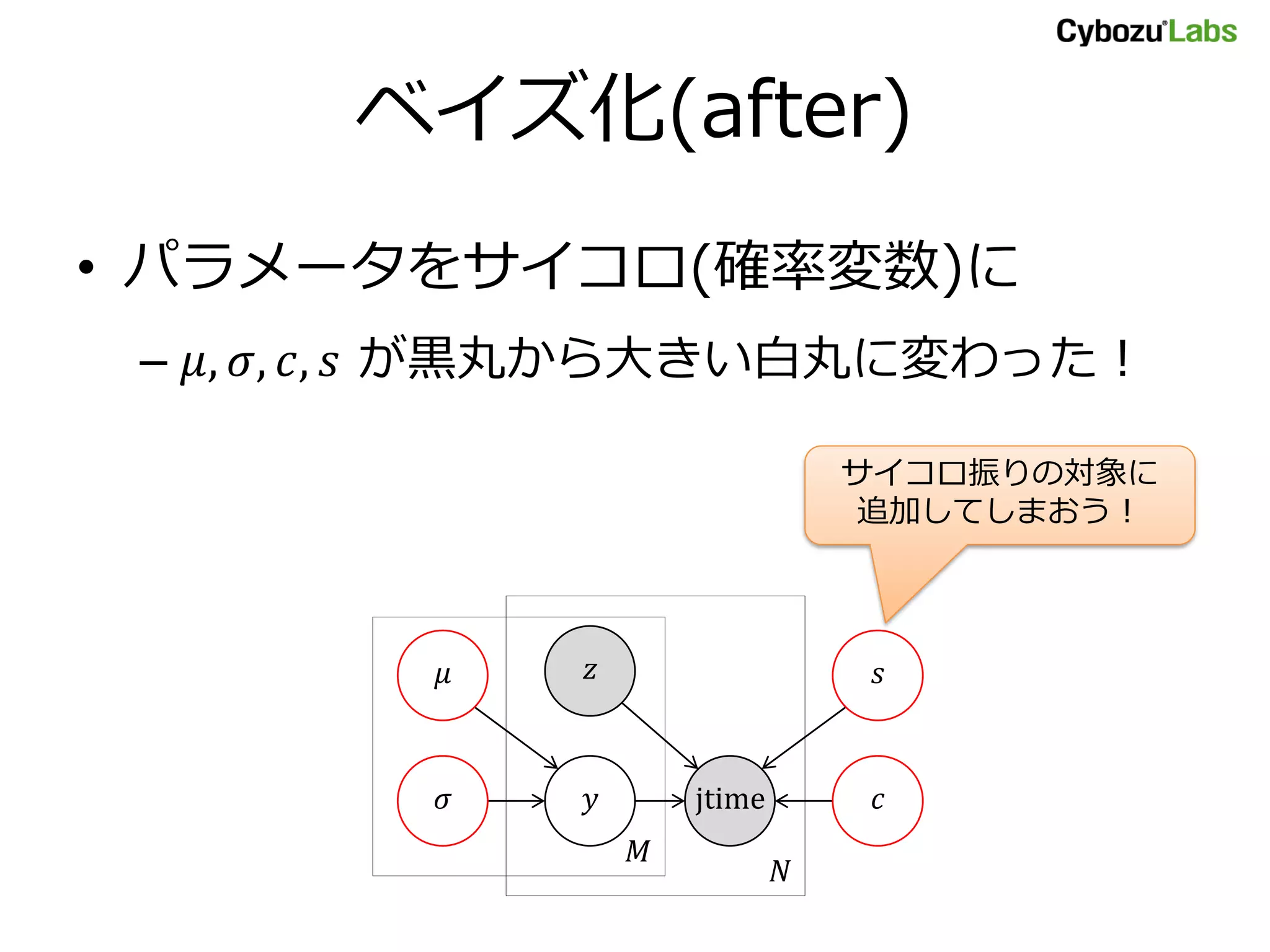
– ベイズ化≒パラメータを確率変数にすること
- 32.
- 33.
- 34.
- 35.
- 36.
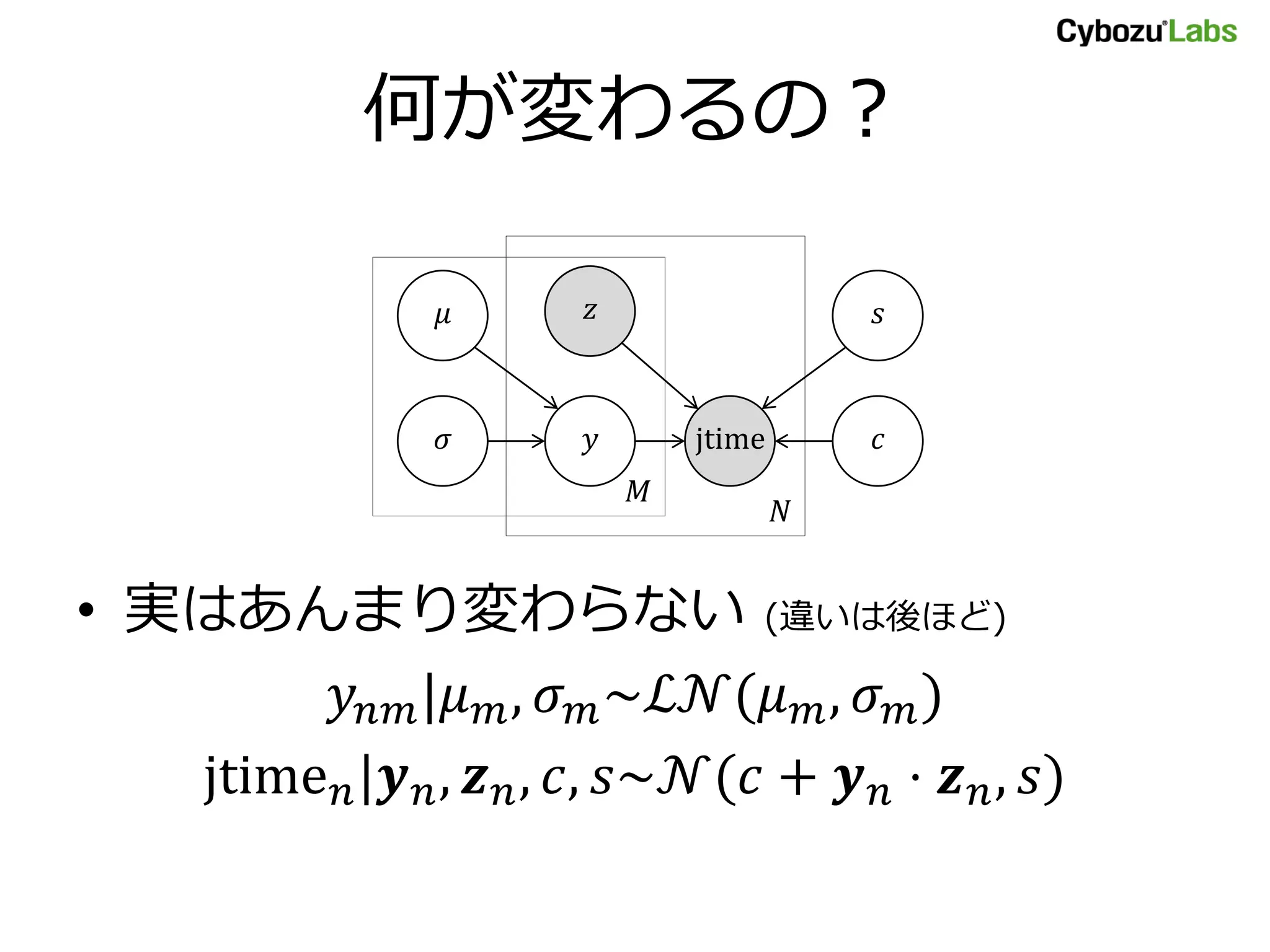
条件付き分布
• (1) 𝑦𝑛𝑚|𝜇𝑚, 𝜎 𝑚 ~ ℒ𝒩(𝜇 𝑚, 𝜎 𝑚)
• (2) jtime 𝑛|𝒚 𝑛, 𝒛 𝑛, 𝑐, 𝑠 ~ 𝒩(𝑐 + 𝒚 𝑛 ⋅ 𝒛 𝑛, 𝒔)
model {
for (n in 1:N) {
for (m in 1:M) {
y[n, m] ~ lognormal(mu[m], sig[m]); // (1)
}
// (2)
jtime[n] ~ normal(c + dot_product(y[n], z[n]), s);
}
}
- 37.
事前分布
• ベイズ化による最大の相違点
– 𝜇,𝜎, 𝑐, 𝑠 が確率変数になってしまった!
– ので、スタート地点となる分布を書いて
あげる必要があるmodel {
// 事前分布
for (m in 1:M) {
mu[m] ~ normal(0, 1);
sig[m] ~ gamma(1, 0.1);
}
c ~ normal(0, 1);
s ~ gamma(1, 1);
}
※ Stan では事前分布の指定を省略
することもできる。その場合、無情
報っぽいのが勝手に入る。今回は
データが多峰性をちょっと持つので、
正則化を効かせる感じで狭い事前分
布を明示的に入れている。
- 38.
推論(サイコロ振り)の実行
• rstan からStan を呼び出し
– 10000件食わせると一昼夜かかった上、結果
を読み込むところでメモリ不足で落ちた
– 1000件で1~2時間
N <- 1000
vlg <- village[sample(nrow(village), N),] # 1000 件サンプル
library(rstan)
data <- list(N=N, M=5, jtime=vlg$jtime, z=vlg[6:10])
fit <- stan(file=stan_file, data=data)
- 39.
- 40.
製品別セットアップ時間 𝑦 の分布
y<- melt(extract(fit, "y")$y, value.name="jtime")
y$lbl <- lbl[y$Var3]
ggplot(y, aes(jtime, ..density..)) +
geom_histogram(alpha=0.5, binwidth=1) +
geom_line(data=d,aes(x, y)) +
facet_wrap(~lbl) + xlim(0, 50)
- 41.
- 42.
(参考)他のパラメータの推定値
> print(fit, pars=c("mu","sig","c","s"))
meanse_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
mu[1] 0.91 0.01 0.07 0.74 0.86 0.91 0.96 1.04 50 1.07
mu[2] 3.43 0.00 0.03 3.37 3.41 3.42 3.45 3.49 128 1.02
mu[3] 2.15 0.00 0.03 2.10 2.13 2.15 2.16 2.20 146 1.02
mu[4] 2.29 0.00 0.04 2.21 2.26 2.29 2.31 2.36 76 1.07
mu[5] 1.04 0.03 0.20 0.64 0.92 1.04 1.18 1.42 41 1.07
sig[1] 0.99 0.01 0.06 0.88 0.95 0.98 1.03 1.10 55 1.04
sig[2] 0.27 0.00 0.02 0.24 0.26 0.27 0.29 0.32 78 1.04
sig[3] 0.39 0.00 0.02 0.36 0.38 0.39 0.40 0.43 191 1.01
sig[4] 0.38 0.01 0.03 0.32 0.35 0.37 0.39 0.45 27 1.17
sig[5] 1.00 0.04 0.16 0.77 0.89 0.98 1.07 1.40 14 1.34
c 1.65 0.02 0.10 1.46 1.59 1.64 1.71 1.92 33 1.12
s 0.19 0.04 0.10 0.06 0.11 0.16 0.28 0.40 6 2.39
> y %>% group_by(lbl) %>% summarise(mean(jtime))
lbl mean(jtime)
(chr) (dbl)
1 garoon 31.940648
2 kintone 3.978208
3 mailwise 10.573244
4 office 9.246358
5 skylab 4.803925
★重回帰の結果
Estimate Std. Error t value Pr(>|t
(Intercept) 4.2244 0.1172 36.04 <2e-
kintone 1.5214 0.1245 12.22 <2e-
garoon 31.1726 0.1518 205.32 <2e-
office 6.7723 0.1223 55.37 <2e-
mailwise 8.4679 0.1480 57.20 <2e-
skylab 5.3662 0.1781 30.13 <2e-
- 43.




![MCMCサンプラーとは
• サイコロの設計図(モデルファイル)を渡す
と、サイコロを作っていっぱい投げてくれる
data {
int<lower=0> N;
int<lower=0> M;
matrix<lower=0,upper=1>[N, M] z;
real<lower=0> jtime[N];
}
parameters {
real mu[M];
real<lower=0> sig[M];
matrix<lower=0>[N, M] y;
real c;
real<lower=0> s;
}
model {
for (n in 1:N) {
jtime[n] ~
normal(c + dot_product(y[n], z[n]), s);
for (m in 1:M) {
y[n, m] ~ lognormal(mu[m], sig[m]);
}
}
// 事前分布
for (m in 1:M) {
mu[m] ~ normal(0, 1);
sig[m] ~ gamma(1, 0.1);
}
c ~ normal(0, 1);
s ~ gamma(1, 1);
}
かなり複雑な
設計図でもOK!](https://image.slidesharecdn.com/rstanmcmcbayes-160924071122/75/R-Stan-TokyoR-5-2048.jpg)






















![Stan に渡す設計図を書こう
• モデルファイル
𝑧
jtime𝑦
𝑁
𝑀
𝜎
𝜇
𝑐
𝑠
data {
int<lower=0> N;
int<lower=0> M;
matrix<lower=0,upper=1>[N, M] z;
real<lower=0> jtime[N];
}
parameters {
real mu[M];
real<lower=0> sig[M];
matrix<lower=0>[N, M] y;
real c;
real<lower=0> s;
}](https://image.slidesharecdn.com/rstanmcmcbayes-160924071122/75/R-Stan-TokyoR-35-2048.jpg)
![条件付き分布
• (1) 𝑦𝑛𝑚|𝜇 𝑚, 𝜎 𝑚 ~ ℒ𝒩(𝜇 𝑚, 𝜎 𝑚)
• (2) jtime 𝑛|𝒚 𝑛, 𝒛 𝑛, 𝑐, 𝑠 ~ 𝒩(𝑐 + 𝒚 𝑛 ⋅ 𝒛 𝑛, 𝒔)
model {
for (n in 1:N) {
for (m in 1:M) {
y[n, m] ~ lognormal(mu[m], sig[m]); // (1)
}
// (2)
jtime[n] ~ normal(c + dot_product(y[n], z[n]), s);
}
}](https://image.slidesharecdn.com/rstanmcmcbayes-160924071122/75/R-Stan-TokyoR-36-2048.jpg)
![事前分布
• ベイズ化による最大の相違点
– 𝜇, 𝜎, 𝑐, 𝑠 が確率変数になってしまった!
– ので、スタート地点となる分布を書いて
あげる必要があるmodel {
// 事前分布
for (m in 1:M) {
mu[m] ~ normal(0, 1);
sig[m] ~ gamma(1, 0.1);
}
c ~ normal(0, 1);
s ~ gamma(1, 1);
}
※ Stan では事前分布の指定を省略
することもできる。その場合、無情
報っぽいのが勝手に入る。今回は
データが多峰性をちょっと持つので、
正則化を効かせる感じで狭い事前分
布を明示的に入れている。](https://image.slidesharecdn.com/rstanmcmcbayes-160924071122/75/R-Stan-TokyoR-37-2048.jpg)
![推論(サイコロ振り)の実行
• rstan から Stan を呼び出し
– 10000件食わせると一昼夜かかった上、結果
を読み込むところでメモリ不足で落ちた
– 1000件で1~2時間
N <- 1000
vlg <- village[sample(nrow(village), N),] # 1000 件サンプル
library(rstan)
data <- list(N=N, M=5, jtime=vlg$jtime, z=vlg[6:10])
fit <- stan(file=stan_file, data=data)](https://image.slidesharecdn.com/rstanmcmcbayes-160924071122/75/R-Stan-TokyoR-38-2048.jpg)

![製品別セットアップ時間 𝑦 の分布
y <- melt(extract(fit, "y")$y, value.name="jtime")
y$lbl <- lbl[y$Var3]
ggplot(y, aes(jtime, ..density..)) +
geom_histogram(alpha=0.5, binwidth=1) +
geom_line(data=d,aes(x, y)) +
facet_wrap(~lbl) + xlim(0, 50)](https://image.slidesharecdn.com/rstanmcmcbayes-160924071122/75/R-Stan-TokyoR-40-2048.jpg)

![(参考)他のパラメータの推定値
> print(fit, pars=c("mu","sig","c","s"))
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
mu[1] 0.91 0.01 0.07 0.74 0.86 0.91 0.96 1.04 50 1.07
mu[2] 3.43 0.00 0.03 3.37 3.41 3.42 3.45 3.49 128 1.02
mu[3] 2.15 0.00 0.03 2.10 2.13 2.15 2.16 2.20 146 1.02
mu[4] 2.29 0.00 0.04 2.21 2.26 2.29 2.31 2.36 76 1.07
mu[5] 1.04 0.03 0.20 0.64 0.92 1.04 1.18 1.42 41 1.07
sig[1] 0.99 0.01 0.06 0.88 0.95 0.98 1.03 1.10 55 1.04
sig[2] 0.27 0.00 0.02 0.24 0.26 0.27 0.29 0.32 78 1.04
sig[3] 0.39 0.00 0.02 0.36 0.38 0.39 0.40 0.43 191 1.01
sig[4] 0.38 0.01 0.03 0.32 0.35 0.37 0.39 0.45 27 1.17
sig[5] 1.00 0.04 0.16 0.77 0.89 0.98 1.07 1.40 14 1.34
c 1.65 0.02 0.10 1.46 1.59 1.64 1.71 1.92 33 1.12
s 0.19 0.04 0.10 0.06 0.11 0.16 0.28 0.40 6 2.39
> y %>% group_by(lbl) %>% summarise(mean(jtime))
lbl mean(jtime)
(chr) (dbl)
1 garoon 31.940648
2 kintone 3.978208
3 mailwise 10.573244
4 office 9.246358
5 skylab 4.803925
★重回帰の結果
Estimate Std. Error t value Pr(>|t
(Intercept) 4.2244 0.1172 36.04 <2e-
kintone 1.5214 0.1245 12.22 <2e-
garoon 31.1726 0.1518 205.32 <2e-
office 6.7723 0.1223 55.37 <2e-
mailwise 8.4679 0.1480 57.20 <2e-
skylab 5.3662 0.1781 30.13 <2e-](https://image.slidesharecdn.com/rstanmcmcbayes-160924071122/75/R-Stan-TokyoR-42-2048.jpg)
