Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SN
Uploaded by
Shuyo Nakatani
PDF, PPTX
29,530 views
星野「調査観察データの統計科学」第1&2章
星野「調査観察データの統計科学」の読書スライドです。 社内勉強会で使った資料がベースです。 第1章の調査観察研究の枠組みと、第2章のルービンの因果モデルを紹介しています。
Technology
◦
Read more
40
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 50
2
/ 50
3
/ 50
4
/ 50
5
/ 50
6
/ 50
7
/ 50
8
/ 50
9
/ 50
10
/ 50
11
/ 50
12
/ 50
13
/ 50
14
/ 50
15
/ 50
16
/ 50
Most read
17
/ 50
18
/ 50
19
/ 50
20
/ 50
21
/ 50
22
/ 50
23
/ 50
24
/ 50
25
/ 50
26
/ 50
27
/ 50
28
/ 50
29
/ 50
Most read
30
/ 50
Most read
31
/ 50
32
/ 50
33
/ 50
34
/ 50
35
/ 50
36
/ 50
37
/ 50
38
/ 50
39
/ 50
40
/ 50
41
/ 50
42
/ 50
43
/ 50
44
/ 50
45
/ 50
46
/ 50
47
/ 50
48
/ 50
49
/ 50
50
/ 50
More Related Content
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PPTX
主成分分析
by
大貴 末廣
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
Stan超初心者入門
by
Hiroshi Shimizu
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
主成分分析
by
大貴 末廣
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
What's hot
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PPTX
距離とクラスタリング
by
大貴 末廣
PDF
潜在クラス分析
by
Yoshitake Takebayashi
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PDF
効果測定入門 Rによる傾向スコア解析
by
aa_aa_aa
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
関数データ解析の概要とその方法
by
Hidetoshi Matsui
PDF
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
PDF
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PDF
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
PDF
MICの解説
by
logics-of-blue
PDF
Stanの便利な事後処理関数
by
daiki hojo
PPTX
ブートストラップ法とその周辺とR
by
Daisuke Yoneoka
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
1 4.回帰分析と分散分析
by
logics-of-blue
PDF
傾向スコア:その概念とRによる実装
by
takehikoihayashi
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
階層ベイズによるワンToワンマーケティング入門
by
shima o
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
距離とクラスタリング
by
大貴 末廣
潜在クラス分析
by
Yoshitake Takebayashi
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
効果測定入門 Rによる傾向スコア解析
by
aa_aa_aa
機械学習のためのベイズ最適化入門
by
hoxo_m
関数データ解析の概要とその方法
by
Hidetoshi Matsui
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
MICの解説
by
logics-of-blue
Stanの便利な事後処理関数
by
daiki hojo
ブートストラップ法とその周辺とR
by
Daisuke Yoneoka
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
1 4.回帰分析と分散分析
by
logics-of-blue
傾向スコア:その概念とRによる実装
by
takehikoihayashi
Viewers also liked
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PDF
傾向スコアの概念とその実践
by
Yasuyuki Okumura
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PDF
強化学習その1
by
nishio
PDF
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
PPTX
Rで学ぶ観察データでの因果推定
by
Hiroki Matsui
PDF
無限関係モデル (続・わかりやすいパターン認識 13章)
by
Shuyo Nakatani
PDF
木と電話と選挙(causalTree)
by
Shota Yasui
PDF
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
PDF
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...
by
Shuyo Nakatani
PDF
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
PPTX
Emnlp読み会資料
by
Jiro Nishitoba
PPTX
EMNLP 2015 yomikai
by
Yo Ehara
PPTX
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
PDF
Learning Better Embeddings for Rare Words Using Distributional Representations
by
Takanori Nakai
PDF
Humor Recognition and Humor Anchor Extraction
by
裕樹 奥田
PDF
A Neural Attention Model for Sentence Summarization [Rush+2015]
by
Yuta Kikuchi
PPTX
20161127 doradora09 japanr2016_lt
by
Nobuaki Oshiro
PPTX
Tidyverseとは
by
yutannihilation
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
傾向スコアの概念とその実践
by
Yasuyuki Okumura
統計的因果推論勉強会 第1回
by
Hikaru GOTO
強化学習その1
by
nishio
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
Rで学ぶ観察データでの因果推定
by
Hiroki Matsui
無限関係モデル (続・わかりやすいパターン認識 13章)
by
Shuyo Nakatani
木と電話と選挙(causalTree)
by
Shota Yasui
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...
by
Shuyo Nakatani
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
Emnlp読み会資料
by
Jiro Nishitoba
EMNLP 2015 yomikai
by
Yo Ehara
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
Learning Better Embeddings for Rare Words Using Distributional Representations
by
Takanori Nakai
Humor Recognition and Humor Anchor Extraction
by
裕樹 奥田
A Neural Attention Model for Sentence Summarization [Rush+2015]
by
Yuta Kikuchi
20161127 doradora09 japanr2016_lt
by
Nobuaki Oshiro
Tidyverseとは
by
yutannihilation
Similar to 星野「調査観察データの統計科学」第1&2章
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PDF
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
PDF
統計学における相関分析と仮説検定の基本的な考え方とその実践
by
id774
PDF
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PPTX
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
PPTX
T検定と相関分析概要
by
Junko Yamada
PDF
Introduction to statistics
by
Kohta Ishikawa
PDF
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
PDF
ベイズ入門
by
Zansa
PPTX
Darm3(samplesize)
by
Yoshitake Takebayashi
PDF
第5回スキル養成講座 講義スライド
by
keiodig
PPT
K070k80 点推定 区間推定
by
t2tarumi
PDF
第3回スキル養成講座 講義スライド
by
keiodig
PDF
R-study-tokyo02
by
Yohei Sato
PPT
K070 点推定
by
t2tarumi
PDF
統計的因果推論の理論と実践 ch9 交互作用項のある共分散分析
by
YasutoTerasawa
PPT
070 統計的推測 母集団と推定
by
t2tarumi
PPT
K090 仮説検定
by
t2tarumi
PDF
統計的推定の基礎 1 -- 期待値の推定
by
Wataru Shito
社会心理学とGlmm
by
Hiroshi Shimizu
2012-1110「マルチレベルモデルのはなし」(censored)
by
Mizumoto Atsushi
統計学における相関分析と仮説検定の基本的な考え方とその実践
by
id774
非ガウス性を利用した 因果構造探索
by
Shiga University, RIKEN
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
要因計画データに対するベイズ推定アプローチ
by
Takashi Yamane
T検定と相関分析概要
by
Junko Yamada
Introduction to statistics
by
Kohta Ishikawa
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
ベイズ入門
by
Zansa
Darm3(samplesize)
by
Yoshitake Takebayashi
第5回スキル養成講座 講義スライド
by
keiodig
K070k80 点推定 区間推定
by
t2tarumi
第3回スキル養成講座 講義スライド
by
keiodig
R-study-tokyo02
by
Yohei Sato
K070 点推定
by
t2tarumi
統計的因果推論の理論と実践 ch9 交互作用項のある共分散分析
by
YasutoTerasawa
070 統計的推測 母集団と推定
by
t2tarumi
K090 仮説検定
by
t2tarumi
統計的推定の基礎 1 -- 期待値の推定
by
Wataru Shito
More from Shuyo Nakatani
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
PDF
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
PDF
Generative adversarial networks
by
Shuyo Nakatani
PDF
ドラえもんでわかる統計的因果推論 #TokyoR
by
Shuyo Nakatani
PDF
猫に教えてもらうルベーグ可測
by
Shuyo Nakatani
PDF
言語処理するのに Python でいいの? #PyDataTokyo
by
Shuyo Nakatani
PDF
Zipf? (ジップ則のひみつ?) #DSIRNLP
by
Shuyo Nakatani
PDF
アラビア語とペルシャ語の見分け方 #DSIRNLP 5
by
Shuyo Nakatani
PDF
Short Text Language Detection with Infinity-Gram
by
Shuyo Nakatani
PDF
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...
by
Shuyo Nakatani
PDF
ソーシャルメディアの多言語判定 #SoC2014
by
Shuyo Nakatani
PDF
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
by
Shuyo Nakatani
PDF
極大部分文字列を使った twitter 言語判定
by
Shuyo Nakatani
PDF
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013
by
Shuyo Nakatani
PDF
人間言語判別 カタルーニャ語編
by
Shuyo Nakatani
PDF
[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems
by
Shuyo Nakatani
PDF
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...
by
Shuyo Nakatani
PDF
人工知能と機械学習の違いって?
by
Shuyo Nakatani
ノンパラベイズ入門の入門
by
Shuyo Nakatani
Active Learning 入門
by
Shuyo Nakatani
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
Generative adversarial networks
by
Shuyo Nakatani
ドラえもんでわかる統計的因果推論 #TokyoR
by
Shuyo Nakatani
猫に教えてもらうルベーグ可測
by
Shuyo Nakatani
言語処理するのに Python でいいの? #PyDataTokyo
by
Shuyo Nakatani
Zipf? (ジップ則のひみつ?) #DSIRNLP
by
Shuyo Nakatani
アラビア語とペルシャ語の見分け方 #DSIRNLP 5
by
Shuyo Nakatani
Short Text Language Detection with Infinity-Gram
by
Shuyo Nakatani
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...
by
Shuyo Nakatani
ソーシャルメディアの多言語判定 #SoC2014
by
Shuyo Nakatani
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
by
Shuyo Nakatani
極大部分文字列を使った twitter 言語判定
by
Shuyo Nakatani
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013
by
Shuyo Nakatani
人間言語判別 カタルーニャ語編
by
Shuyo Nakatani
[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems
by
Shuyo Nakatani
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...
by
Shuyo Nakatani
人工知能と機械学習の違いって?
by
Shuyo Nakatani
Recently uploaded
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
Drupal Recipes 解説 .
by
iPride Co., Ltd.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PPTX
ddevについて .
by
iPride Co., Ltd.
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
Drupal Recipes 解説 .
by
iPride Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
ddevについて .
by
iPride Co., Ltd.
星野「調査観察データの統計科学」第1&2章
1.
星野「調査観察データの統計科学」 第1~2章 2015/9/8 @shuyo ( Cybozu
Labs )
2.
統計あるある
3.
3歳児神話 • 「子どもは3歳までは保育園に行かないで母 親のもとで育つほうが健全(社会性・知能の 発達が高い)」 • Hill+(2002)
による調査 – 1歳から3歳まで母親のもとで育った子どもと、同 じ時期に保育園に通っていた子どもを追跡調査 – 8歳の時点での社会性得点と知能検査を比較 – 保育園に通った子供のほうがどちらも良い成績 • 3歳児神話は否定されたとしていい?
4.
3歳児神話 • 「子どもは3歳までは保育園に行かないで母 親のもとで育つほうが健全(社会性・知能の 発達が高い)」 • Hill+(2002)
による調査 – 1歳から3歳まで母親のもとで育った子どもと、同 じ時期に保育園に通っていた子どもを追跡調査 – 8歳の時点での社会性得点と知能検査を比較 – 保育園に通った子供のほうがどちらも良い成績 • 3歳児神話は否定されたとしていい? ただし、保育園に子どもを 通わせる親の収入や学歴は 保育園に子どもを通わせない 親より平均して高かった
5.
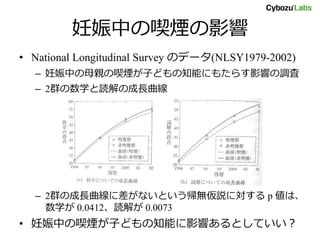
妊娠中の喫煙の影響 • National Longitudinal
Survey のデータ(NLSY1979-2002) – 妊娠中の母親の喫煙が子どもの知能にもたらす影響の調査 – 2群の数学と読解の成長曲線 – 2群の成長曲線に差がないという帰無仮説に対する p 値は、 数学が 0.0412、読解が 0.0073 • 妊娠中の喫煙が子どもの知能に影響あるとしていい?
6.
妊娠中の喫煙の影響 • National Longitudinal
Survey のデータ(NLSY1979-2002) – 妊娠中の母親の喫煙が子どもの知能にもたらす影響の調査 – 2群の数学と読解の成長曲線 – 2群の成長曲線に差がないという帰無仮説に対する p 値は、 数学が 0.0412、読解が 0.0073 • 妊娠中の喫煙が子どもの知能に影響あるとしていい? ただし、母親の学歴が高いと (タバコの有害性を知りやすく) 妊娠中に喫煙する可能性は小さく、 また母親の学歴が高いと 子どもの知能が高くなる可能性が 大きいことがわかっている
7.
教育費負担の実態調査(2008/10) • 高校~大学院などに在学している子どもを持 ち、国の教育ローンを利用している世帯に対 する調査 – 世帯収入に対する教育費は平均
34.1% – 年収200~400万円の世帯では 55.6% – 住宅ローン年間返済額と教育費を合わせると平均 45.9%、両社が世帯収入の5割を超えた世帯は全 体の 32.5% • 日本人は教育費の重い負担に苦しんでいる?
8.
教育費負担の実態調査(2008/10) • 高校~大学院などに在学している子どもを持 ち、国の教育ローンを利用している世帯に対 する調査 – 世帯収入に対する教育費は平均
34.1% – 年収200~400万円の世帯では 55.6% – 住宅ローン年間返済額と教育費を合わせると平均 45.9%、両社が世帯収入の5割を超えた世帯は全 体の 32.5% • 日本人は教育費の重い負担に苦しんでいる? ただし、調査対象である 「国の教育ローンを利用している家庭」 の多くが私学に子どもを入れるなどして、 収入の割に高い教育費を払っている 家庭であると考えられる
9.
解約予防フォローコール • 犀坊主(仮)は自社サービスを利用している 100件のユーザのうち、アクセスの少ない 30件について電話フォローを行った – フォローした30件はその後
40% が解約 – しなかった70件は 30% が解約 • 電話フォローは効果なしとしていい?
10.
解約予防フォローコール • 犀坊主(仮)は自社サービスを利用している 100件のユーザのうち、アクセスの少ない 30件について電話フォローを行った – フォローした30件はその後
40% が解約 – しなかった70件は 30% が解約 • 電話フォローは効果なしとしていい? ただし、アクセスの少ないユーザは もともと解約の可能性が 高かったことが推測される
11.
問題の分類 • 調査観察研究 • 選択バイアス •
データ融合
12.
調査観察研究 • 実験(無作為割り当て)ができない研究 – 対象が理論的・倫理的に操作可能ではない –
実験という特殊性により、被験者が通常と異なる 行動を取る可能性がある – コストが高く、サンプルが小さすぎる – 被験者の負担が高く、少数の協力者に限定される • 割り当ては無作為であっても、不遵守(被験者のサボ り)が起きると、無作為データで無くなる
13.
選択バイアス • 「本来対象とする集団」から一部の対象者が 選択(or除外)されている状況で、単純な解析 を行うことによって生じる結果の歪み – 作為的な選択バイアスは論外として…… –
特定の傾向を持った個人や組織を対象とした調 査・研究を行わざるをえないことは多い • インターネット調査も「選択バイアス」(インター ネットリテラシーの高い人、報酬に釣られた人) • 顧客アンケートも「選択バイアス」(顧客で、かつわ ざわざ送り返してくれた人)
14.
データ融合 • 対象者の異なる複数のデータを統合し、 擬似的なシングルソースデータを構成し、 顧客層の理解と購買行動予測を行う – 顧客のページ閲覧履歴、購買履歴 +市場調査、商品の属性 •
市場調査データの回答者が、購買履歴 データに含まれないなど対象者に重なり がなく、相関が得られないことも
15.
これらの問題を 統一的な枠組みで モデリングする
16.
調査観測+欠測データ • ルービンの因果モデル – 調査観測データを欠測のあるデータと考える –
もし介入を受けた場合の従属変数 • 英語早期教育を行わなかった群(対照群)は欠測 – もし介入を受けなかった場合の従属変数 • 英語早期教育を行った群(処置群)は欠測 – 2つの群の質的な違いを説明する共変量 • 例:親の学歴・収入・教育意欲 一般には「実験群」 とも呼ばれるが、 無作為抽出のニュア ンスを避けて 「処置群」と呼ぶ 処置群のデータ 欠測 欠測 対照群のデータ 全対象者に共通して得られている変数 処置群 対照群 介入を受けた 場合の結果 𝑦1 介入を受けない 場合の結果 𝑦0 共変量項目
17.
選択バイアス+欠測データ • 欠測データとしての選択バイアスの補正 – 調査対象者≠回答者であるとき –
関心のある従属変数は回答者において観測さ れるが、非回答者では観測されない 回答者のデータ 非回答者のデータ 全対象者に共通して得られている変数 回答者 非回答者 従属変数 共変量項目
18.
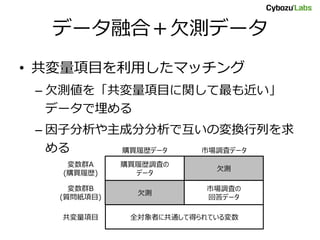
データ融合+欠測データ • 共変量項目を利用したマッチング – 欠測値を「共変量項目に関して最も近い」 データで埋める –
因子分析や主成分分析で互いの変換行列を求 める 購買履歴調査の データ 欠測 欠測 市場調査の 回答データ 全対象者に共通して得られている変数 購買履歴データ 市場調査データ 変数群A (購買履歴) 変数群B (質問紙項目) 共変量項目
19.
本書のアプローチ • 欠測のあるデータの枠組みで考える • 共変量情報を積極的に集め、活用する –
適切な選択や仮定も必要 • セミパラメトリックな手法を用い、 ロバストな結果を得る – 共変量と従属変数の線形性を仮定しない
20.
欠測データと因果推論
21.
欠測の分類 1. 各変数レベルでの記入漏れや無回答 2. 打ち切りや切断 –
打ち切り=閾値を超えたことはわかるが、本来の値 がわからない – 切断=閾値を超えた観測値の数そのものが不明 3. 経時データやパネルデータでの脱落 – パネルデータ=時系列+クロスセクション 4. 調査や測定全体への無回答や不参加、測定不能
22.
欠測のメカニズム 1. 完全にランダムな欠測 – 欠測するかどうかはモデリングに用いている変数 には依存しない 2.
ランダムな欠測 – 欠測するかどうかは欠測値には依存せず、観測値 に依存する 3. ランダムでない欠測 – 欠測するかどうかは欠測値そのものや観測してい ない他の変数にも依存する 下に行くほど仮定が弱くなり、表現力が高くなり、解くのが難しくなる
23.
欠測値付きモデル • 𝒚 =
𝒚obs 𝒚mis : 関心のある変数 – 𝒚obs:観測値、𝒚mis:欠測値 • 𝒎:欠測したか表すインディケータ変数 • 𝑝 𝒚, 𝒎 𝜽, 𝝓 = 𝑝 𝒚 𝜽 𝑝 𝒎 𝒚, 𝝓 – 𝜽:完全データ同時分布のパラメータ – 𝝓:欠測モデルのパラメータ • 𝑝 𝒚obs, 𝒎 𝜽, 𝝓 = ∫ 𝑝 𝒚 𝜽 𝑝 𝒎 𝒚, 𝝓 𝑑𝒚mis – モデルを解く=この尤度関数を最大化する
24.
欠測のメカニズム 1. 完全にランダムな欠測 – 𝑝
𝒎 𝒚, 𝝓 = 𝑝 𝒎 𝝓 2. ランダムな欠測 – 𝑝 𝒎 𝒚, 𝝓 = 𝑝 𝒎 𝒚obs, 𝝓 3. ランダムでない欠測 – 𝑝 𝒎 𝒚, 𝝓 のまま
25.
(完全に)ランダムな欠測 • 𝑝 𝒎
𝒚, 𝝓 = 𝑝 𝒎 𝒚obs, 𝝓 より • 尤度関数は 𝑝 𝒚obs, 𝒎 𝜽, 𝝓 = ∫ 𝑝 𝒚 𝜽 𝑝 𝒎 𝒚obs, 𝝓 𝑑𝒚mis = 𝑝 𝒎 𝒚obs, 𝝓 ∫ 𝑝 𝒚 𝜽 𝑑𝒚mis = 𝑝 𝒎 𝒚obs, 𝝓 𝑝(𝒚obs|𝜽) • 一般に関心があるのは θ であり、 log 𝑝 𝒚obs, 𝒎 𝜽, 𝝓 = log 𝑝 𝒎 𝒚obs, 𝝓 + log 𝑝(𝒚obs|𝜽) • より log 𝑝(𝒚obs|𝜽) のみを用いて推論すればいい 完全にランダム欠測 =強すぎる仮定 ランダム欠測 =解ける範囲で弱めた仮定
26.
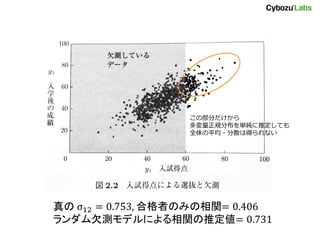
例 (線形) • 𝑦1:入試得点
と 𝑦2:入学後の成績 の関係 – 入試得点で合格点 𝐶 に達しなかった学生は入学できない ため、𝑦2 に欠測が生じる • 𝑦1, 𝑦2 に線形回帰の関係があるとすると、 𝑦2 = 𝜃1 + 𝜃2 𝑦1 + 𝜖, 𝜖~𝑁 0, 𝜎2 𝑝 𝑦2, 𝑚 𝑦1, 𝜽, 𝐶 = 𝑝 𝑦2 𝑦1, 𝜽, 𝜎2 𝑝(𝑚|𝑦1, 𝐶) • 𝑦2 の欠測インジケータ m は常に観測される 𝑦1 のみに 依存するので「ランダムな欠測」 • ∴ 𝜽 を欠測値を考慮せずに決めてよい
27.
この部分だけで線形回帰をしても 切片と傾きを推定できる 欠測
28.
例(多変量正規分布) • 𝑦1, 𝑦2
に2変量正規分布の関係があると 𝑦1 𝑦2 ~𝑁 𝜇1 𝜇2 , 𝜎1 2 𝜎12 𝜎21 𝜎2 2 • 観測されている 𝑦1, 𝑦2 だけからパラメータ推定す ると、𝜎12 に大きいバイアスがのる • 「ランダム欠損」であることを考慮した推定では 真の 𝜎12 に近い値を推定できる – 計算省略
29.
この部分だけから 多変量正規分布を単純に推定しても 全体の平均・分散は得られない 真の σ12 =
0.753, 合格者のみの相関= 0.406 ランダム欠測モデルによる相関の推定値= 0.731
30.
この本における変数 • Y:従属変数、結果変数 – (一般には)結果となる変数 –
必ずしも観測できない(欠測値がある) – この本では、一般の回帰問題で説明変数として扱われるような変数も Y となる(例:入試の点数) • Z:独立変数、説明変数、割り当て、(欠測)インディケータ – (一般には)原因となる変数 – この本では、群への割り当てを示す変数のみが独立変数として扱われ る。その他の変数は全て Y として扱われる • X:共変量 – (潜在的)結果変数と割当てのいずれにも影響を与える量 • 中間変数:当面出てこないので略
31.
処置群・対照群 • 無作為割り当てが行われている実験研究 において – 実験群:
特別な条件を与えた群 – 対照群: 与えていない群 • 調査観察研究においては実験群ではなく 「処置群」と呼ぶ – 「実験群」には無作為割り当てが行われてい る印象があるため
32.
「因果効果」の説明のための例 処置群(z) 1 1
1 0 0 0 対象者番号 1 2 … … N-1 N 𝑦1 𝑦11 𝑦21 … … 𝑦 𝑁−1,1 𝑦 𝑁1 𝑦0 𝑦10 𝑦20 … … 𝑦 𝑁−1,0 𝑦 𝑁0 早期教育する群(z=1) 早期教育しない群(z=0) 高い 低い • 𝑧:所属群を表す独立変数 • 𝑦1:早期教育した場合の子供の中学校での成績 • 𝑦0:早期教育しない場合の子供の中学校での成績
33.
因果効果(Rubin 1974) • 潜在的な説明変数 –
独立変数がとりうる値の数と同じ数だけ存在 する仮想的な従属変数 – 𝑧 ∈ 0,1 にそれぞれ 𝑦0, 𝑦1 が対応 – 特に限定・明記はされていないが、 • z=1 が処置群、z=0 が対照群で基本固定っぽい • 𝑦𝑧 が観測値、𝑦1−𝑧 が欠測値でこれまた固定
34.
因果効果(Rubin 1974) • 因果効果
= 𝑦1 − 𝑦0 – 処置群に割り当てられた場合の結果と、割り 当てられていなかった場合の結果の差 – 割り当て以外の対象者の要因が除外された量 – 片方は欠測値なので、直接計算はできない • Rubin の因果効果 = 𝐸 𝑦1 − 𝐸 𝑦0
35.
処置群が無作為抽出なら • すなわち 𝑦𝑗
と 𝑧 が独立 𝑝 𝑦𝑗 𝑧 = 𝑝 𝑦𝑗 なら、 – 𝐸 𝑦𝑗 = ∫ 𝑦𝑗 𝑝 𝑦𝑗 𝑑𝑦𝑗 = ∫ 𝑦𝑗 𝑝 𝑦𝑗|𝑧 𝑑𝑦𝑗 = 𝐸 𝑦𝑗 𝑧 – 𝐸 𝑦1 − 𝐸 𝑦0 = 𝐸 𝑦1 𝑧 = 1 − 𝐸 𝑦0 𝑧 = 0 • 𝐸 𝑦𝑗 𝑧 = 𝑗 は観察された各群の平均値 • ∴因果効果をバイアス無く推定できる
36.
因果効果と介入効果の関係 • 処置群での平均介入効果(average Treatment
Effect on the Treated) – 𝑇𝐸𝑇 = 𝐸 𝑦1 − 𝑦0 𝑧 = 1 • 対照群での平均介入効果(average Treatment Effect on the Untreated) – 𝑇𝐸U = 𝐸 𝑦1 − 𝑦0 𝑧 = 0 • このとき因果効果は – 𝐸 𝑦1 − 𝑦0 = 𝑇𝐸𝑇 × 𝑝 𝑧 = 1 + 𝑇𝐸𝑈 × 𝑝(𝑧 = 0) – 処置群と対照群の母集団における割合に依存
37.
共変量調整による因果効果推定の ための条件
38.
共変量 • 結果変数と割り当ての両方に影響のある量 – どのような共変量を選ぶべきかについては4章 •
すべての対象者について観測できる量 – 観測できない共変量がある場合については4章
39.
共変量調整 • 因果効果=処置群の期待値-対照群の期待値 – 共変量の影響により見かけ上の関係(擬似相関)やバイ アスが生じる可能性がある –
早期教育の例:「中学校での英語の成績」(結果変 数)も「小学校での英語教育の有無」(割り当て) もどちらも親の教育意欲や収入などの影響を受ける • 共変量調整: – 結果変数から共変量の影響を除去すること – 影響を除去しても残る相関から因果効果を求めたい 一般には難しかったりめんどくさかったり
40.
強く無視できる割り当て • 「割り当ては共変量のみに依存し、結果変数には 依存しない」という仮定 – (𝑦1,
𝑦0) ⊥ 𝑧|𝒙 すなわち 𝑝 𝑧 𝑦1, 𝑦0, 𝒙 = 𝑝 𝑧 𝒙 • このとき、 𝑝 𝑦1, 𝑦0, 𝑧, 𝒙 = 𝑝 𝑧 𝑦1, 𝑦0, 𝒙 𝑝 𝑦1, 𝑦0 𝒙 𝑝 𝒙 = 𝑝 𝑧 𝒙 𝑝 𝑦1, 𝑦0 𝒙 𝑝 𝒙 • 𝑝 𝑦1, 𝑦0 𝑧, 𝒙 = 𝑝 𝑦1, 𝑦0 𝒙 も成立※ – 共変量を条件付ければ、 𝑦1, 𝑦0 の同時分布はどちら の群に割り当てられたかに依存しない 𝑥 𝑦 𝑧 この分解の時に 𝑦 → 𝑧 が切れる ホントは条件付き独立の記号(縦2本) ※本には「式(2.16)をベイズの定理を用いて言い換えると~」(p44)とあるが、 条件付き独立の定義のままであり、特に言い換えは不要
41.
処置群(z) 1 1
1 0 0 0 対象者番号 1 2 … … N-1 N … … … … 早期教育する群(z=1) 早期教育しない群(z=0) 因果効果 on 強く無視できる割り当て • 𝑝 𝑦1, 𝑦0 𝑧, 𝒙 = 𝑝 𝑦1, 𝑦0 𝒙 から、平均での独 立性が得られる – 𝐸 𝑦1 𝑧 = 1, 𝒙 = 𝐸 𝑦1 𝒙 – 𝐸 𝑦0 𝑧 = 0, 𝒙 = 𝐸 𝑦0 𝒙 • よって 𝐸 𝑦1 − 𝐸 𝑦0 = 𝐸 𝒙 𝐸 𝑦1 − 𝐸 𝑦0 = 𝐸 𝒙[𝐸 𝑦1 𝑧 = 1, 𝒙 − 𝐸 𝑦0 𝑧 = 0, 𝒙 ] 式(2.19)改※ ※本の式(2.19)は不必要な変形が混じっていて混乱する。 y から始めるのをやめればスッキリする ここが不要に!
42.
共変量調整による因果効果の推定法 1. マッチング – 共変量が一致する(or
近い)対象者の互いの結果変数が等しいとする 2. 恒常化・限定 – 共変量が特定の値の対象者に限定し解析。因果効果は推定できない←! 3. 層別解析 – 共変量の値を幾つかの層に分け、層ごとに2つのグループがその共変量 の値について等質になるようにし、比較した結果を統合 ←? – (何らかの基準で5つほどの)サブクラスに分け、各クラスで 𝐸 𝑦1 − 𝐸 𝑦0 を求め、クラスのサイズで重みづけた平均を取る(3章の説明より) 4. 回帰モデルを用いる方法 – 各群ごとに回帰関数 𝐸 𝑦𝑗 𝑧 = 𝑗, 𝑥 を推定、その差の標本平均を取る
43.
マッチング・層別解析の欠点 • 恣意性 – 「近さ」の定義が恣意的 •
次元問題 – 高次元だと実行が難しい • サポート問題 – スパースだと「近い」対象者が存在しない
44.
回帰モデルによる因果効果の推定 • 𝐸 𝑦𝑗
𝑧 = 𝑗, 𝑥 を推定 – (𝑥𝑖, 𝑦𝑖𝑗) を説明・目的変数とした単純な線形回帰 問題を解けばいい • 求めた回帰間数を使って因果効果を計算 𝐸 𝑦1 − 𝐸 𝑦0 = 𝐸 𝑦1 𝑧 = 1, 𝒙 − 𝐸 𝑦0 𝑧 = 0, 𝒙 𝑝(𝒙)𝑑𝒙 = 1 𝑁 𝐸 𝑦𝑖1 𝑧 = 1, 𝒙𝑖 − 𝐸 𝑦𝑖0 𝑧 = 0, 𝒙𝑖 𝑁 𝑖=1 かどうかは厳密にはモデルによる。 本は暗黙に (ガウス)ノイズが乗った線 形回帰モデルを想定しており、よって (x,y)に最小二乗法を用いればよい
45.
結果変数の条件付き分布の母数推定 • 「強く無視できる割り当て」はランダム欠測を満 たす – 観測された値で最尤推定してパラメータ決定 •
𝑝 𝑦 𝑜𝑏𝑠 𝑥 = ∫ 𝑝 𝑦1, 𝑦0 𝑥, 𝜃1, 𝜃0, 𝜓 𝑑𝑦 𝑚𝑖𝑠 = 𝑝 𝑦𝑖1 𝑥𝑖, 𝜃1 𝑖:𝑧 𝑖=1 × 𝑝 𝑦𝑖0 𝑥𝑖, 𝜃0 𝑖:𝑧 𝑖=0 • この推定量は一致性をもつ – データが増えると漸近的に真値に一致する
46.
回帰モデルによる因果効果推定の問題点 • 結果変数と共変量のモデリングが必要 – 「正しい」モデルでなければバイアス発生 –
「正しい」モデルでも、要求される仮定を満 たさなければバイアス発生 • 直接因果効果の推定値は得られない – 前スライドの式を使って標本平均を推定値と する必要がある
47.
正しいモデルでもバイアス? • 処置群と対照群が次のモデルに従うとする – 𝑦𝑖1
= 𝜏1 + 𝒙𝑖 𝑡 𝜷1 + 𝜖𝑖1, 𝑦𝑖0 = 𝜏0 + 𝒙𝑖 𝑡 𝜷0 + 𝜖𝑖0 – 本では 𝜷1 − 𝜷0 = 0 とおいて計算した後、「逆に言えば~という強い仮 定を暗黙のうちにおいていることになる」となっているのだが、無理 筋なので、ここでは 𝜷1 − 𝜷0 = 0 を仮定しない • 共変量調整によって推定される因果効果は 𝐸 𝑦1 𝒙𝑖 − 𝐸 𝑦0 𝒙𝑖 = 𝜏1 + 𝒙𝑖 𝑡 𝜷1 − 𝜏0 + 𝒙𝑖 𝑡 𝜷0 = 𝜏1 − 𝜏0 + 𝒙𝑖 𝑡 𝜷1 − 𝜷0 ∴ 𝐸 𝒙 𝐸 𝑦1 𝒙 − 𝐸 𝑦0 𝒙 = 𝜏1 − 𝜏0 + 𝐸 𝒙 𝒙 𝑡 (𝜷1 − 𝜷0) • 一方、因果効果の真値もこうなり、一致するように見える…… 𝐸 𝑦1 − 𝐸 𝑦0 = 𝜏1 − 𝜏0 + 𝐸 𝒙 𝑡 (𝜷1 − 𝜷0) • 真値が 𝜏1 − 𝜏0 だったら 𝐸 𝒙 𝒙𝑖 𝑡 (𝜷1 − 𝜷0) がバイアスで、次頁の図 と解釈が一致するのだが……
48.
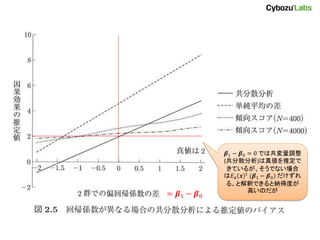
= 𝜷1 −
𝜷0 𝜷1 − 𝜷0 = 0 では共変量調整 (共分散分析)は真値を推定で きているが、そうでない場合 は𝐸 𝒙 𝒙 𝑡 (𝜷1 − 𝜷0) だけずれ る、と解釈できると納得度が 高いのだが
49.
モデルが間違っていたらもちろん× • 真のモデルが「1次の項だけではなく2次の項が存在する」場合 – 「ここでは2次の項だけ加えた結果を示しているため、2次の項を説明 変数として解析すればよいのでは思われるかもしれない。しかし、線 形以外の項を考慮するとするならば2次以外にも様々な関数を考える必 要がある。(中略)現実的ではない」
50.
カーネル回帰で共変量調整 • ノンパラメトリックな回帰分析 – 「様々な関数を考える必要」が無い –
ノンパラ=パラメータ数が固定ではなくデータ数に よって増える • つまりパラメータがめっちゃ多い • とても過適合しやすく、コントロールに職人技 • 一般にデータ数の2~3乗オーダー、次元の呪い – 以下省略 • ノンパラまで行かなくていいから、もうちょっと 扱いやすいやつ→セミパラメトリック
Download




































![処置群(z) 1 1 1 0 0 0
対象者番号 1 2 … … N-1 N
… …
… …
早期教育する群(z=1) 早期教育しない群(z=0)
因果効果 on 強く無視できる割り当て
• 𝑝 𝑦1, 𝑦0 𝑧, 𝒙 = 𝑝 𝑦1, 𝑦0 𝒙 から、平均での独
立性が得られる
– 𝐸 𝑦1 𝑧 = 1, 𝒙 = 𝐸 𝑦1 𝒙
– 𝐸 𝑦0 𝑧 = 0, 𝒙 = 𝐸 𝑦0 𝒙
• よって
𝐸 𝑦1 − 𝐸 𝑦0
= 𝐸 𝒙 𝐸 𝑦1 − 𝐸 𝑦0
= 𝐸 𝒙[𝐸 𝑦1 𝑧 = 1, 𝒙 − 𝐸 𝑦0 𝑧 = 0, 𝒙 ]
式(2.19)改※
※本の式(2.19)は不必要な変形が混じっていて混乱する。
y から始めるのをやめればスッキリする
ここが不要に!](https://image.slidesharecdn.com/observationalstudy1-150908070840-lva1-app6891/85/1-2-41-320.jpg)













































![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







![A Neural Attention Model for Sentence Summarization [Rush+2015]](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2015yomi-151024073845-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

































![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems](https://cdn.slidesharecdn.com/ss_thumbnails/karger-croudsourcing-nips11-120408005300-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









