回帰問題における過剰適合問題
データへのオーバーフィット
モデルの自由度
モデル選択法1: 交差検証法(CV)
k-fold Cross-Validation
Leave p-out Cross-Validation
モデル選択法2: 情報量基準
最尤法と尤度関数
赤池情報量基準(AIC)
ベイズ情報量基準(BIC)
講師: 東京都市大学 田中宏和
講義ビデオ: https://www.youtube.com/playlist?list=PLXAfiwJfs0jGOvZnwUdAykZvSdRFd7K2p







![過剰適合(overfit)の問題 その1
n=100; L=4;
x=linspace(0,L,n);
f=(x.^2).'; % parabola with 100 data points
M=20; % polynomical degree
for j=1:M
phi(:,j)=(x.').^(j-1); % build matrix A
end
for j=1:4
fn=(x.^2+0.1*randn(1,n)).';
an=pinv(phi)*fn; fna=phi*an; % least-square fit
En=norm(f-fna)/norm(f);
subplot(4,2,4+j),bar(an,'FaceColor',[.6 .6 .6], ...
'EdgeColor','k’);
end
subplot(2,1,1), plot(x,f,'k'), hold on
CH04_SEC04_1_CompareRegression_production.m
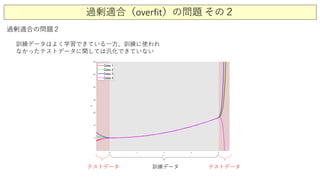
過剰適合の問題1
データに含まれるノイズ成分に引き連れて、データ
ごとに推定されるモデル係数が大きく変動する](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-8-320.jpg)
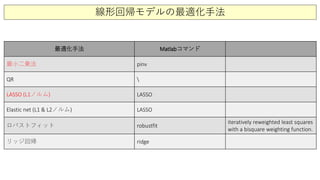
![線形回帰モデルの最適化手法の比較
%% different regressions
subplot(2,1,1)
lambda = 0.1; phi2 = phi(:,2:end);
for jj=1:100
f=(x.^2+0.2*randn(1,n)).'; % create noisy data
% pseudo inverse
a1=pinv(phi)*f; f1=phi*a1; E1(jj)=norm(f-f1)/norm(f);
% QR (backslash)
a2=phif; f2=phi*a2; E2(jj)=norm(f-f2)/norm(f);
% lasso (L1 norm)
[a3,stats]=lasso(phi,f,'Lambda',lambda); f3=phi*a3; E3(jj)=norm(f-f3)/norm(f);
% elastic net (L1 and L2 norm)
[a4,stats]=lasso(phi,f,'Lambda',lambda,'Alpha',0.8); f4=phi*a4; E4(jj)=norm(f-f4)/norm(f);
% robust fit
a5=robustfit(phi2,f); f5=phi*a5;E5(jj)=norm(f-f5)/norm(f);
% ridge regression
a6=ridge(f,phi2,0.5,0); f6=phi*a6;E6(jj)=norm(f-f6)/norm(f);
A1(:,jj)=a1;A2(:,jj)=a2;A3(:,jj)=a3;A4(:,jj)=a4;A5(:,jj)=a5;A6(:,jj)=a6;
plot(x,f), hold on
end](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-11-320.jpg)




![交差検証法:k-fold Cross-Validationの具体例
n=100; L=4;
x=linspace(0,L,n);
f=(x.^2).'; % parabola with 100 data points
M=21; % polynomial degree
for j=1:M
phi(:,j)=(x.').^(j-1); % build matrix A
end
figure(1); clf; hold on;
trials=[2 10 100];
for j=1:3
for jj=1:trials(j)
f=(x.^2+0.2*randn(1,n)).';
a1=pinv(phi)*f; f1=phi*a1; E1(jj)=norm(f-f1)/norm(f);
a2=phif; f2=phi*a2; E2(jj)=norm(f-f2)/norm(f);
[a3,stats]=lasso(phi,f,‘Lambda’,0.1); f3=phi*a3;
E3(jj)=norm(f-f3)/norm(f);
A1(:,jj)=a1; A2(:,jj)=a2; A3(:,jj)=a3;
end
A1m=mean(A1.'); A2m=mean(A2.'); A3m=mean(A3.');
Err=[E1; E2; E3];
subplot(3,3,j), bar(A1m); axis([0 21 -1 1.2]);
subplot(3,3,3+j), bar(A2m), axis([0 21 -1 1.2]);
subplot(3,3,6+j), bar(A3m), axis([0 21 -1 1.2]);
end
CH04_SEC06_1_kFoldValidation_production.m](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-16-320.jpg)
![交差検証法:crossvalコマンドを使う方法
% Quadratic data + Gaussian noise
N = 100;
x = sort(rand(N,1)*5-2.5);
y = x.^2 + 1*randn(N,1);
% evaluation of mean squared error for polynomial model
cvErrAll = zeros(10,1);
for q=1:10
regressionfitting = @(xtrain, ytrain, xtest)(polyval(polyfit(xtrain,ytrain,q), xtest));
err = crossval('mse', x, y, 'predfun', regressionfitting);
disp(['q=' num2str(q) ', mse=' num2str(err)]);
cvErrAll(q) = err;
end
figure(1); clf;
plot(1:10, cvErrAll, 'k.-');
xlabel('Polynomial order');
ylabel('Test error')
demo_crossval.m (WebClassにあります)
MSE=mean squared error 平均二乗誤差](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-17-320.jpg)














![モデル選択法2:情報量基準の具体例
データ生成モデル:自己回帰モデル AR(2) (=Auto-regressive model)
時刻 t の変数の値 (xt)は、一つ前の値 (xt-1) と二つ前の値 (xt-2)で決まる
( )1 2.4 0.2 0 5 0,2t t tx x x− −+=− + +
% Preallocate loglikelihood vector
rng(1); % For random data reproducibility
T = 100; % Sample size
DGP = arima('Constant',-4,'AR',[0.2, 0.5],'Variance',2);
y = simulate(DGP,T);](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-32-320.jpg)
![モデル選択法2:情報量基準の具体例
このデータを複数のモデルでフィット
AR(1)
AR(2)
AR(3)
AR(4)
AR(5)
0
1
t k t
k
k
K
x a a x −
=
= + ∑
AR(K)モデル
時刻 t の変数の値 (xt)は、Kステップま
でまでの値 (xt-1, xt-2, ... , xt-K) で決まる
% Preallocate loglikelihood vector
EstMdl1 = arima('ARLags',1);
EstMdl2 = arima('ARLags',1:2);
EstMdl3 = arima('ARLags',1:3);
EstMdl4 = arima('ARLags',1:4);
EstMdl5 = arima('ARLags',1:5);
% Preallocate loglikelihood vector
logL = zeros(5,1); % Preallocate loglikelihood vector
[~,~,logL(1)] = estimate(EstMdl1,y,'display','off');
[~,~,logL(2)] = estimate(EstMdl2,y,'display','off');
[~,~,logL(3)] = estimate(EstMdl3,y,'display','off');
[~,~,logL(4)] = estimate(EstMdl4,y,'display','off');
[~,~,logL(5)] = estimate(EstMdl5,y,'display','off');
[aic,bic] = aicbic(logL, [3; 4; 5; 6; 7], T*ones(5,1));
ARモデルを定義
ARモデルを推定
尤度の計算
AIC/BICを計算](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-33-320.jpg)
![モデル選択法2:情報量基準の具体例
% AR(2)モデルでデータを生成
rng(1); % For random data reproducibility
T = 100; % Sample size
DGP = arima('Constant',-4,'AR',[0.2, 0.5],'Variance',2);
y = simulate(DGP,T);
% 推定のための5つのモデル、AR(1)-AR(5)を準備
EstMdl1 = arima('ARLags',1);
EstMdl2 = arima('ARLags',1:2);
EstMdl3 = arima('ARLags',1:3);
EstMdl4 = arima('ARLags',1:4);
EstMdl5 = arima('ARLags',1:5);
% 5つのモデルでフィットし、対数尤度を計算
logL = zeros(5,1); % Preallocate loglikelihood vector
[~,~,logL(1)] = estimate(EstMdl1,y,'display','off');
[~,~,logL(2)] = estimate(EstMdl2,y,'display','off');
[~,~,logL(3)] = estimate(EstMdl3,y,'display','off');
[~,~,logL(4)] = estimate(EstMdl4,y,'display','off');
[~,~,logL(5)] = estimate(EstMdl5,y,'display','off');
% 5つのモデルの情報量基準(AIC/BIC)を計算
[aic,bic] = aicbic(logL, [3; 4; 5; 6; 7], T*ones(5,1)); AIC, BICの両方から、AR(2)モデルが最適
CH04_SEC07_2_RegressAIC_BIC.m](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-34-320.jpg)
![モデル選択法2:情報量基準の具体例
CH04_SEC07_2_RegressAIC_BIC.m
[~,~,logL(1)] = estimate(EstMdl1,y,'print',false);
[~,~,logL(1)] = estimate(EstMdl1,y, 'display', 'off');
エラーが出た場合
以下のように書き換えてください。](https://image.slidesharecdn.com/7regressionanalysisandmodelselection2-200811225426/85/7-2-35-320.jpg)











![[R勉強会][データマイニング] R言語による時系列分析](https://cdn.slidesharecdn.com/ss_thumbnails/r-100423232629-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)






































