copyright 2016 YosukeKatada
階層型クラスタリング
11
A B C D E F G H
デンドログラム
距
離
A B C D E F G H
A 0 4 6 8 15 16 19 24
B - 0 5 6 17 15 18 20
C - - 0 6 13 11 16 18
D - - - 0 17 13 18 15
E - - - - 0 2 7 10
F - - - - - 0 6 9
G - - - - - - 0 8
H - - - - - - - 0
距離例
階層型クラスタリングではデンドログラムを構築することが一つ
のゴール
12.
copyright 2016 YosukeKatada
最も類似している
2番目に類似している
デンドログラム
12
クラスタリングの結合の過程を木で表現したもの
A B C D E
AB
DE
ABC
ABCDE
この高さは結合したク
ラスター間の距離を
表す
copyright 2016 YosukeKatada
階層型クラスタリングを用いる方法
• 事前に階層型クラスタリングを実施し、その結果からどのくらいのクラスタ数にな
りそうか検討してクラスター数を決定する
• 階層型クラスタリングはデータ数が多いとデンドログラムが見にくいのでサンプリ
ングベースで実施する
33
A B C D E F G H I J K L M N O
クラスター数は
4つくらい
copyright 2016 YosukeKatada
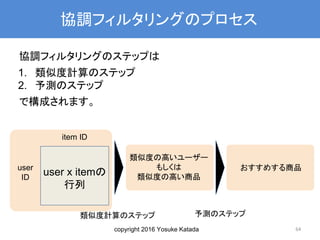
協調フィルタリングのプロセス
協調フィルタリングのステップは
1. 類似度計算のステップ
2. 予測のステップ
で構成されます。
64
user
ID
item ID
user x itemの
行列
類似度の高いユーザー
もしくは
類似度の高い商品
おすすめする商品
類似度計算のステップ 予測のステップ
65.
copyright 2016 YosukeKatada
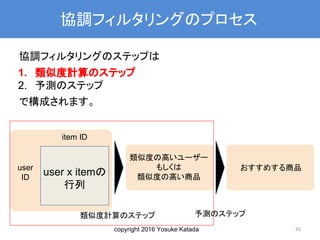
協調フィルタリングのプロセス
協調フィルタリングのステップは
1. 類似度計算のステップ
2. 予測のステップ
で構成されます。
65
user
ID
item ID
user x itemの
行列
類似度の高いユーザー
もしくは
類似度の高い商品
おすすめする商品
類似度計算のステップ 予測のステップ
copyright 2016 YosukeKatada
協調フィルタリングのプロセス
協調フィルタリングのステップは
1. 類似度計算のステップ
2. 予測のステップ
で構成されます。
70
user
ID
item ID
user x itemの
行列
類似度の高いユーザー
もしくは
類似度の高い商品
おすすめする商品
類似度計算のステップ 予測のステップ
























































![© 2016 Yosuke Katada
無断転載禁止
αとβはディリクレ分布のパラメーター
ディリクレ分布とは、複数クラスがあるうち、各クラ
スの目の出やすさを表現する確率分布
例: 今サイコロがあり、ディリクレ分布よりどの面の出やすさ(確
率)をサンプリングする。
1 2 3 4 5 6
0.00 0.99 0.00 0.00 0.00 0.01
0.00 0.00 0.01 0.27 0.72 0.00
1.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.51 0.49
1 2 3 4 5 6
0.13 0.14 0.21 0.26 0.16 0.10
0.15 0.13 0.25 0.19 0.18 0.10
0.12 0.20 0.19 0.09 0.26 0.14
0.24 0.10 0.17 0.13 0.12 0.23
alpha = [0.1, 0,1, 0.1 … 0.1] alpha = [10.0, 10.0, 10.0... . 10.0]](https://image.slidesharecdn.com/random-161227151900/85/slide-57-320.jpg)














![copyright 2016 Yosuke Katada
コールドスタート問題の解決方法
• 売上ランキング上位のものを出す?
• コンテンツベースのレコメンデーションで推薦す
る?
• もうフィードバックをもらえそうなユーザーに聞い
ちゃう?
– https://research.yahoo.com/mobstor/publication_attachments/exUseM
e_RecSys2015_CameraReady.pdf
• 次元削減手法を使って見る
– Netflix Prizeでも成果を上げた方法
• https://datajobs.com/data-science-repo/Recommender-Systems-[
Netflix].pdf
74](https://image.slidesharecdn.com/random-161227151900/85/slide-74-320.jpg)























![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


























