Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SN
Uploaded by
Shuyo Nakatani
PDF, PPTX
35,383 views
星野「調査観察データの統計科学」第3章
星野「調査観察データの統計科学」の読書スライドです。 社内勉強会で使った資料がベースです。 第3章の傾向スコアを紹介しています。
Technology
◦
Read more
23
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 58
2
/ 58
3
/ 58
4
/ 58
5
/ 58
6
/ 58
7
/ 58
8
/ 58
9
/ 58
10
/ 58
11
/ 58
12
/ 58
13
/ 58
14
/ 58
15
/ 58
16
/ 58
17
/ 58
18
/ 58
19
/ 58
20
/ 58
21
/ 58
22
/ 58
23
/ 58
24
/ 58
25
/ 58
26
/ 58
27
/ 58
Most read
28
/ 58
29
/ 58
30
/ 58
Most read
31
/ 58
32
/ 58
33
/ 58
Most read
34
/ 58
35
/ 58
36
/ 58
37
/ 58
38
/ 58
39
/ 58
40
/ 58
41
/ 58
42
/ 58
43
/ 58
44
/ 58
45
/ 58
46
/ 58
47
/ 58
48
/ 58
49
/ 58
50
/ 58
51
/ 58
52
/ 58
53
/ 58
54
/ 58
55
/ 58
56
/ 58
57
/ 58
58
/ 58
More Related Content
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PPTX
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
PDF
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
by
takehikoihayashi
PDF
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
「生態学における統計的因果推論」という大ネタへの挑戦:その理論的背景と適用事例
by
takehikoihayashi
PDF
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
PDF
潜在クラス分析
by
Yoshitake Takebayashi
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
なぜベイズ統計はリスク分析に向いているのか? その哲学上および実用上の理由
by
takehikoihayashi
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
ベイズファクターとモデル選択
by
kazutantan
「生態学における統計的因果推論」という大ネタへの挑戦:その理論的背景と適用事例
by
takehikoihayashi
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
潜在クラス分析
by
Yoshitake Takebayashi
What's hot
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PDF
因果推論の奥へ: "What works" meets "why it works"
by
takehikoihayashi
PDF
“機械学習の説明”の信頼性
by
Satoshi Hara
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PDF
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
PDF
データ解析7 主成分分析の基礎
by
Hirotaka Hachiya
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
負の二項分布について
by
Hiroshi Shimizu
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
pymcとpystanでベイズ推定してみた話
by
Classi.corp
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
因果推論の奥へ: "What works" meets "why it works"
by
takehikoihayashi
“機械学習の説明”の信頼性
by
Satoshi Hara
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
階層ベイズによるワンToワンマーケティング入門
by
shima o
ベイズ統計学の概論的紹介
by
Naoki Hayashi
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
データ解析7 主成分分析の基礎
by
Hirotaka Hachiya
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
不均衡データのクラス分類
by
Shintaro Fukushima
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
機械学習のためのベイズ最適化入門
by
hoxo_m
ノンパラベイズ入門の入門
by
Shuyo Nakatani
負の二項分布について
by
Hiroshi Shimizu
Viewers also liked
PDF
強化学習その1
by
nishio
PDF
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
PDF
傾向スコア:その概念とRによる実装
by
takehikoihayashi
PDF
傾向スコアの概念とその実践
by
Yasuyuki Okumura
PDF
無限関係モデル (続・わかりやすいパターン認識 13章)
by
Shuyo Nakatani
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PDF
木と電話と選挙(causalTree)
by
Shota Yasui
PDF
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
PDF
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
PDF
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...
by
Shuyo Nakatani
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
PPTX
Emnlp読み会資料
by
Jiro Nishitoba
PDF
A Neural Attention Model for Sentence Summarization [Rush+2015]
by
Yuta Kikuchi
PDF
Learning Better Embeddings for Rare Words Using Distributional Representations
by
Takanori Nakai
PDF
Humor Recognition and Humor Anchor Extraction
by
裕樹 奥田
PPTX
20161127 doradora09 japanr2016_lt
by
Nobuaki Oshiro
PPTX
Tidyverseとは
by
yutannihilation
PPTX
EMNLP 2015 yomikai
by
Yo Ehara
PPTX
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
強化学習その1
by
nishio
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
傾向スコア:その概念とRによる実装
by
takehikoihayashi
傾向スコアの概念とその実践
by
Yasuyuki Okumura
無限関係モデル (続・わかりやすいパターン認識 13章)
by
Shuyo Nakatani
統計的因果推論勉強会 第1回
by
Hikaru GOTO
木と電話と選挙(causalTree)
by
Shota Yasui
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...
by
Shuyo Nakatani
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
Emnlp読み会資料
by
Jiro Nishitoba
A Neural Attention Model for Sentence Summarization [Rush+2015]
by
Yuta Kikuchi
Learning Better Embeddings for Rare Words Using Distributional Representations
by
Takanori Nakai
Humor Recognition and Humor Anchor Extraction
by
裕樹 奥田
20161127 doradora09 japanr2016_lt
by
Nobuaki Oshiro
Tidyverseとは
by
yutannihilation
EMNLP 2015 yomikai
by
Yo Ehara
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
Similar to 星野「調査観察データの統計科学」第3章
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
効果測定入門 Rによる傾向スコア解析
by
aa_aa_aa
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PDF
PRML輪読#10
by
matsuolab
PPTX
第五回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
PRML 10.4 - 10.6
by
Akira Miyazawa
PDF
ベイズ入門
by
Zansa
PPTX
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
PPTX
PRML4.3
by
hiroki yamaoka
PDF
Oshasta em
by
Naotaka Yamada
PDF
2013 03 25
by
Mutsuki Kojima
PDF
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
ベイズ統計入門
by
Miyoshi Yuya
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
効果測定入門 Rによる傾向スコア解析
by
aa_aa_aa
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
Prml 1.3~1.6 ver3
by
Toshihiko Iio
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PRML輪読#10
by
matsuolab
第五回統計学勉強会@東大駒場
by
Daisuke Yoneoka
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PRML10-draft1002
by
Toshiyuki Shimono
PRML 10.4 - 10.6
by
Akira Miyazawa
ベイズ入門
by
Zansa
Introduction to Statistical Estimation (統計的推定入門)
by
Taro Tezuka
PRML4.3
by
hiroki yamaoka
Oshasta em
by
Naotaka Yamada
2013 03 25
by
Mutsuki Kojima
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
More from Shuyo Nakatani
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
PDF
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
PDF
ドラえもんでわかる統計的因果推論 #TokyoR
by
Shuyo Nakatani
PDF
言語処理するのに Python でいいの? #PyDataTokyo
by
Shuyo Nakatani
PDF
Zipf? (ジップ則のひみつ?) #DSIRNLP
by
Shuyo Nakatani
PDF
猫に教えてもらうルベーグ可測
by
Shuyo Nakatani
PDF
Generative adversarial networks
by
Shuyo Nakatani
PDF
アラビア語とペルシャ語の見分け方 #DSIRNLP 5
by
Shuyo Nakatani
PDF
Short Text Language Detection with Infinity-Gram
by
Shuyo Nakatani
PDF
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...
by
Shuyo Nakatani
PDF
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013
by
Shuyo Nakatani
PDF
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
by
Shuyo Nakatani
PDF
ソーシャルメディアの多言語判定 #SoC2014
by
Shuyo Nakatani
PDF
極大部分文字列を使った twitter 言語判定
by
Shuyo Nakatani
PDF
人間言語判別 カタルーニャ語編
by
Shuyo Nakatani
PDF
[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems
by
Shuyo Nakatani
PDF
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...
by
Shuyo Nakatani
PDF
Extreme Extraction - Machine Reading in a Week
by
Shuyo Nakatani
PDF
人工知能と機械学習の違いって?
by
Shuyo Nakatani
Active Learning 入門
by
Shuyo Nakatani
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
ドラえもんでわかる統計的因果推論 #TokyoR
by
Shuyo Nakatani
言語処理するのに Python でいいの? #PyDataTokyo
by
Shuyo Nakatani
Zipf? (ジップ則のひみつ?) #DSIRNLP
by
Shuyo Nakatani
猫に教えてもらうルベーグ可測
by
Shuyo Nakatani
Generative adversarial networks
by
Shuyo Nakatani
アラビア語とペルシャ語の見分け方 #DSIRNLP 5
by
Shuyo Nakatani
Short Text Language Detection with Infinity-Gram
by
Shuyo Nakatani
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...
by
Shuyo Nakatani
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013
by
Shuyo Nakatani
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
by
Shuyo Nakatani
ソーシャルメディアの多言語判定 #SoC2014
by
Shuyo Nakatani
極大部分文字列を使った twitter 言語判定
by
Shuyo Nakatani
人間言語判別 カタルーニャ語編
by
Shuyo Nakatani
[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems
by
Shuyo Nakatani
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...
by
Shuyo Nakatani
Extreme Extraction - Machine Reading in a Week
by
Shuyo Nakatani
人工知能と機械学習の違いって?
by
Shuyo Nakatani
Recently uploaded
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
PDF
Drupal Recipes 解説 .
by
iPride Co., Ltd.
PPTX
ddevについて .
by
iPride Co., Ltd.
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
Drupal Recipes 解説 .
by
iPride Co., Ltd.
ddevについて .
by
iPride Co., Ltd.
星野「調査観察データの統計科学」第3章
1.
星野「調査観察データの統計科学」 第3章 2015/9/14 @shuyo ( Cybozu
Labs )
2.
1&2章 ダイジェスト
3.
調査観察研究 • 実験(無作為割り当て)ができない研究 – 対象が理論的・倫理的に操作可能ではない –
実験という特殊性により、被験者が通常と異なる 行動を取る可能性がある – コストが高く、サンプルが小さすぎる – 被験者の負担が高く、少数の協力者に限定される • 割り当ては無作為であっても、不遵守(被験者のサボ り)が起きると、無作為データで無くなる
4.
Notation • 𝑧 ∈
{0,1} : 割り当て(所属群を表す独立変数) • 𝑑 ∈ {0,1} : 割り当てを受け入れたか否か • 𝑦 : (潜在的な)結果変数 – 𝑦1 : 処置群(特別な条件を与えた群, 𝑧 = 1) – 𝑦0 : 対照群(条件を与えていない群, 𝑧 = 0) – 𝑦 = 𝑧𝑦1 + 1 − 𝑧 𝑦0 • 𝒙 : 共変量 – 結果変数と割り当ての両方に影響のある量 – すべての対象者について観測できる量 • 観測できない共変量がある場合については4章 3.7 章で登場
5.
欠測のメカニズム 𝑝 𝑦1, 𝑦0,
𝑧, 𝒙 = 𝑝(𝑧|𝑦1, 𝑦0, 𝒙)𝑝(𝑦1, 𝑦0|𝒙) 𝑝(𝒙) 1. 完全にランダムな欠測 – 欠測するかどうかは結果変数に(全く間接的にも)依存しない – 𝑝 𝑧 𝑦, 𝒙 = 𝑝(𝑧) 2. 強く無視できる割り当て – 割り当ては共変量のみに依存し、結果変数に(直接は)依存しない – 𝑝 𝑧 𝑦, 𝒙 = 𝑝 𝑧 𝒙 3. ランダムな欠測 – 欠測するかどうかは欠測値には依存せず、観測値に依存 • このとき、モデルパラメータは観測値のみから最尤推定できる – 𝑝 𝑧 = 𝑗 𝑦, 𝒙 = 𝑝 𝑧 = 𝑗 𝑦𝑗, 𝒙
6.
因果効果(Rubin 1974) • 因果効果
= 𝑦1 − 𝑦0 – 処置群に割り当てられた場合の結果と、割り当てら れていなかった場合の結果の差 – 割り当て以外の対象者の要因が除外された量 – 片方は欠測値なので、直接計算はできない • Rubin の因果効果 = 𝐸 𝑦1 − 𝐸 𝑦0 – 処置群が無作為抽出なら、各群の観測値の平均の差 𝐸 𝑦1 𝑧 = 1 − 𝐸 𝑦0 𝑧 = 0 に一致 𝐸 𝑦1 𝑧 = 1 は 観測値の平均 処置群(z) 1 1 1 0 0 0 対象者番号 1 2 … … N-1 N … … … … 早期教育する群(z=1) 早期教育しない群(z=0) 𝐸(𝑦1) ここを推定する必要がある
7.
因果効果と介入効果の関係 • 処置群での平均介入効果(average Treatment
Effect on the Treated) – 𝑇𝐸𝑇 = 𝐸 𝑦1 − 𝑦0 𝑧 = 1 • 対照群での平均介入効果(average Treatment Effect on the Untreated) – 𝑇𝐸U = 𝐸 𝑦1 − 𝑦0 𝑧 = 0 • このとき因果効果は – 𝐸 𝑦1 − 𝑦0 = 𝑇𝐸𝑇 × 𝑝 𝑧 = 1 + 𝑇𝐸𝑈 × 𝑝(𝑧 = 0) – 処置群と対照群の母集団における割合に依存
8.
共変量調整 • 因果効果=処置群の期待値-対照群の期待値 – 共変量の影響により見かけ上の関係(擬似相関)やバイ アスが生じる可能性がある –
早期教育の例:「中学校での英語の成績」(結果変 数)も「小学校での英語教育の有無」(割り当て) もどちらも親の教育意欲や収入などの影響を受ける • 共変量調整: – 結果変数から共変量の影響を除去すること – 影響を除去しても残る相関から因果効果を求めたい 一般には難しかったりめんどくさかったり
9.
強く無視できる割り当て • 「割り当ては共変量のみに依存し、結果変数には 依存しない」という仮定 – (𝑦1,
𝑦0) ⊥ 𝑧|𝒙 すなわち 𝑝 𝑧 𝑦1, 𝑦0, 𝒙 = 𝑝 𝑧 𝒙 • このとき、 𝑝 𝑦1, 𝑦0, 𝑧, 𝒙 = 𝑝 𝑧 𝑦1, 𝑦0, 𝒙 𝑝 𝑦1, 𝑦0 𝒙 𝑝 𝒙 = 𝑝 𝑧 𝒙 𝑝 𝑦1, 𝑦0 𝒙 𝑝 𝒙 • 𝑝 𝑦1, 𝑦0 𝑧, 𝒙 = 𝑝 𝑦1, 𝑦0 𝒙 も成立 – 共変量を条件付ければ、 𝑦1, 𝑦0 の同時分布はどちら の群に割り当てられたかに依存しない 𝑥 𝑦 𝑧 この分解の時に 𝑦 → 𝑧 が切れる ホントは条件付き独立の記号(縦2本)
10.
因果効果 on 強く無視できる割り当て •
𝑝 𝑦1, 𝑦0 𝑧, 𝒙 = 𝑝 𝑦1, 𝑦0 𝒙 から、平均での独 立性が得られる – 𝐸 𝑦1 𝑧 = 1, 𝒙 = 𝐸 𝑦1 𝒙 – 𝐸 𝑦0 𝑧 = 0, 𝒙 = 𝐸 𝑦0 𝒙 • よって 𝐸 𝑦1 − 𝐸 𝑦0 = 𝐸 𝒙 𝐸 𝑦1 − 𝐸 𝑦0 = 𝐸 𝒙[𝐸 𝑦1 𝑧 = 1, 𝒙 − 𝐸 𝑦0 𝑧 = 0, 𝒙 ]
11.
共変量調整による因果効果の推定法 1. マッチング – 各群から共変量が一致する(or
近い)対象者のペアを作 り、その 𝑦1 − 𝑦0 の標本平均を取る 2. 層別解析 – (何らかの基準で5つほどの)サブクラスに分け、各ク ラスで 𝐸 𝑦1 − 𝐸 𝑦0 を求め、クラスのサイズで重み づけた平均を取る 3. 回帰モデルを用いる方法 – 各群ごとに回帰関数 𝐸 𝑦𝑗 𝑧 = 𝑗, 𝑥 を推定、その差の 標本平均を取る
12.
マッチング・層別解析の欠点 • 恣意性 – 「近さ」の定義が恣意的 •
次元問題 – 高次元だと実行コストが高い • サポート問題 – スパースだと「近い」対象者が存在しない
13.
3. セミパラメトリック解析
14.
傾向スコア (Rosenbaum &
Rubin 1983) • 「複数の共変量を1つの変数に集約するこ とができれば、その1変数上で層別化など を行うことができ、マッチングや層別で の問題が起こらない、ということから考 えだされた概念」(p60)
15.
バランシングスコア • 𝑏 𝒙
が「バランシングスコア」とは 𝒙 ⊥ 𝑧|𝑏(𝒙) – (そのような 𝑏(𝒙) が存在するとはまだ言ってない) • 𝒙 ⊥ 𝑧|𝑏(𝒙) ⇔ 𝑝 𝑧 𝑥, 𝑏 𝒙 = 𝑝 𝑧 𝑏 𝒙 • Proposition 𝒙 ⊥ 𝑧|𝑏 𝒙 ⇔ ∃ 𝑔, 𝑝 𝑧 = 1 𝒙 = 𝑔 𝑏 𝒙 – 𝑝 𝑧 = 1 𝒙 が 𝑏 𝒙 で決まる 𝑥 𝑧 𝑏(𝑥)
16.
• [⇒] 𝑥
を止めた時 𝑏(𝑥) も止まるので 𝑝 𝑧 𝑥 = 𝑝 𝑧 𝑥, 𝑏 𝑥 より 𝑝 𝑧 𝑥 = 𝑝 𝑧 𝑥, 𝑏 𝑥 = 𝑝 𝑧 𝑏 𝑥 よって 𝑔 𝑏 𝑥 ≔ 𝑝(𝑧 = 1|𝑏 𝑥 ) とおけばよい • [⇐] 𝑝 𝑧 = 1 𝑏 𝑥 = 𝑝(𝑧 = 1|𝑥) を示せば良い 𝑒 = 𝑏(𝑥) を固定して、 𝑝 𝑧 = 1 𝑏 𝑥 = 𝑒 = 𝑥|𝑏 𝑥 =𝑒 𝑝 𝑧 = 1, 𝑥 𝑏 𝑥 = 𝑒 𝑑𝑥 = 𝑥|𝑏 𝑥 =𝑒 𝑝 𝑧 = 1 𝑥, 𝑏 𝑥 = 𝑒 𝑝 𝑥 𝑏 𝑥 = 𝑒 𝑑𝑥 = 𝑥|𝑏 𝑥 =𝑒 𝑔 𝑏 𝑥 = 𝑒 𝑝(𝑥|𝑏 𝑥 = 𝑒)𝑑𝑥 = 𝑔 𝑏 𝑥 = 𝑒 𝑥|𝑏 𝑥 =𝑒 𝑝(𝑥|𝑏 𝑥 = 𝑒)𝑑𝑥 = 𝑔 𝑏 𝑥 = 𝑒 = 𝑝(𝑧 = 1|𝑥) 𝒙 ⊥ 𝑧|𝑏 𝒙 ⇔ ∃ 𝑔, 𝑝 𝑧 = 1 𝑥 = 𝑔(𝑏 𝑥 )の証明 ※書籍は必要条件を証明しているように書いているが、𝑝(𝑧 = 1|𝑥) = 𝑔(𝑏(𝑥))を使って等式を導き、そ の等式が成立するためには𝑝(𝑧 = 1|𝑥) = 𝑔(𝑏(𝑥))が必要という流れになっており、残念ながら証明とは 言えない。また、あとの傾向スコアがバランシングスコアであることを言うために使うのは十分条件の方である [Rosenbaum, Rubin 1983] では 背理法を使っているが その必要はない [Rosenbaum, Rubin 1983] では これが 𝐸 𝑝 𝑧 = 1 𝑥 𝑏 𝑥 で あることをだけを指摘した 簡潔な証明になっている
17.
傾向スコア • 𝑒𝑖 ≔
𝑝 𝑧𝑖 = 1 𝒙𝑖 を第 i 対象者の傾向スコアとい う • 傾向スコアはバランシングスコア – b 𝒙𝑖 ≔ 𝑒𝑖 for all i – 𝑔 b 𝒙 ≔ b 𝒙 は 𝑝 𝑧 = 1 𝒙 = 𝑔(𝑏 𝒙 ) を満たすの で、Proposition の十分条件により 𝑒𝑖 はバランシング スコア • 𝑒𝑖 の真値はわからない – {𝒙𝑖, 𝑧𝑖} を観測値とし 𝑏 𝒙 = 𝑝 𝑧 = 1 𝒙 をロジス ティック回帰で推定、 𝑒𝑖 = 𝑏 𝒙𝑖 とする
18.
バランシングスコア+強く無視できる割り当て • 𝑏 𝒙
がバランシングスコア、かつ「強く無視できる割 り当て」ならば、 𝑦𝑗と z は b(z) の元で条件付き独立 𝒙 ⊥ 𝑧|𝑏 𝒙 ⋀ 𝑦1, 𝑦0 ⊥ 𝑧|𝒙 ⇒ (𝑦1, 𝑦0) ⊥ 𝑧|𝑏 𝒙 [証明] • (1) 𝑝 𝑧, 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 = 𝑝 𝑥 𝑦1, 𝑦0, 𝑧, 𝑏 𝑥 𝑝 𝑧 𝑦1, 𝑦0, 𝑏 𝑥 = 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 𝑝 𝑧 𝑦1, 𝑦0, 𝑏 𝑥 ∵ 𝒙 ⊥ 𝑧 𝑏 𝒙 • (2) 𝑝 𝑧, 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 = 𝑝 𝑧 𝑦1, 𝑦0, 𝑥, 𝑏 𝑥 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 = 𝑝 𝑧 𝑥, 𝑏 𝑥 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 ∵ 𝑦1, 𝑦0 ⊥ 𝑧 𝒙 = 𝑝 𝑧 𝑏 𝑥 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 ∵ 𝒙 ⊥ 𝑧 𝑏 𝒙 • (1)=(2) より 𝑝 𝑧 𝑦1, 𝑦0, 𝑏 𝑥 = 𝑝 𝑧 𝑏 𝑥 ※書籍の証明は積分を使っているが、上に見る通り乗法公式のみで示すことができる。またそこ の積分では、𝑥で期待値をとっているのに𝑥が残っており、間違いにしか見えないが、これはおそらく 一度𝑔(𝑏(𝑥))に置き換えてから戻すというステップを省略しているのだと思われる。多分……。 𝑥 𝑦𝑗 𝑧 𝑏(𝑥) グラフィカル モデルを見れば 一目瞭然
19.
傾向スコアを使った因果効果推定 • 傾向スコア 𝑒
と強く無視できる割り当て のもとで、 – 𝐸 𝑦𝑗 𝑒 = 𝐸 𝑦𝑗 𝑒, 𝑧 = 𝑗 ゆえ – 𝐸 𝑦1 − 𝐸 𝑦0 = 𝐸𝑒 𝐸 𝑦1 − 𝑦0 𝑒 = 𝐸𝑒 𝐸 𝑦1 𝑒, 𝑧 = 1 − 𝐸 𝑦0 𝑒, 𝑧 = 0 – 𝐸 𝑦1 𝑒, 𝑧 = 1 − 𝐸 𝑦0 𝑒, 𝑧 = 0 が推定できれば 因果効果が得られる
20.
𝐸 𝑦1 𝑒,
𝑧 = 1 − 𝐸 𝑦0 𝑒, 𝑧 = 0 の推定 • マッチング – 2群で傾向スコアが等しい(近い)対象者ペアの 𝑦1 − 𝑦0 を平均 – 共変量を使ったマッチングにあった距離の定義の恣意性や次元 問題、サポート問題が大幅に解消 • 層別解析 – 傾向スコアの大小によって5つほどのサブクラスに分け、各クラ ス内で (𝑦1 の平均)- (𝑦0 の平均) をとり、クラスの大きさの重み をかけた平均を推定値とする • 線形回帰(共分散分析) – 𝑧, 𝑒 を説明変数として 𝐸(𝑦𝑗|𝑧 = 𝑗, 𝑒) を線形回帰で推定 • (IPW推定量:のちほど)
21.
傾向スコアの問題点 1. 3群以上の比較に関心がある場合も、2群ごとの推定となり、 母集団が各2群ごとに異なる 2. マッチング・層別解析では、推定した因果効果の標準誤差 が計算できない 3.
個々の 𝐸 𝑦𝑗 の推定はできない 4. ペアや層を作る基準に恣意性が残る 5. マッチングでペアから漏れた対象者のデータが無駄になり、 推定値も「対象者の少ない方の群の共変量の分布」上での 期待値をとったものとなる 6. 線形回帰は線形性を仮定するが、𝑧 ∈ {0,1} なので無理があ る
22.
𝐸 𝑦𝑗 の推定 •
𝐸 𝑦1 ≅ 1 𝑁 𝑖=1 𝑁 𝑦𝑖1 は欠測している 𝑦𝑖1 がある ため計算できない • 重み付き平均 𝑖=1 𝑁 𝑤𝑖 𝑦 𝑖 𝑖=1 𝑁 𝑤𝑖 で、その重み 𝑤𝑖 が欠 測している 𝑦𝑖1 に対しては 0 になっていて、 かつ 𝑁 → ∞ のときに推定値が期待値に一致 してくれるような、そんな都合のいい重みが あればいいのに → IPW 推定量
23.
IPW 推定量 (Inverse Probability
Weighting) • 傾向スコアの逆数による重み付け平均を周辺期待値の 推定値とする手法 • 𝑤𝑖 = 𝑧𝑖/𝑒𝑖, 𝑣𝑖 = 1 − 𝑧𝑖 /(1 − 𝑒𝑖) とすると、 𝐸 𝑦1 ≔ 𝑖=1 𝑁 𝑤𝑖 𝑦𝑖 𝑖=1 𝑁 𝑤𝑖 = 𝑖=1 𝑁 𝑧𝑖 𝑦𝑖 𝑒𝑖 𝑖=1 𝑁 𝑧𝑖 𝑒𝑖 𝐸 𝑦0 ≔ 𝑖=1 𝑁 𝑣𝑖 𝑦𝑖 𝑖=1 𝑁 𝑣𝑖 = 𝑖=1 𝑁 (1 − 𝑧𝑖)𝑦𝑖 1 − 𝑒𝑖 𝑖=1 𝑁 1 − 𝑧𝑖 1 − 𝑒𝑖 ※潜在的な結果変数 𝑦1, 𝑦0 と、i番目の対象者の結果変数 𝑦𝑖 の notation がゴッチャになってい るが、心の目で見れば区別できるので、特にフォローせず本のとおりに記載する
24.
IPW 推定量の一致性 • IPW
推定量は一致性をもつ(つまり lim 𝑁→∞ 𝐸 𝑦𝑗 = 𝐸 𝑦𝑗 )ことを示す – 𝐸 𝑧|𝒙 = 1 ⋅ 𝑝 𝑧 = 1 𝑥 + 0 ⋅ 𝑝 𝑧 = 0 𝑥 = 𝑒 より 𝐸 𝑧 𝑒 = 𝐸 𝑧 𝑒 = 𝐸 𝑥 𝐸 𝑧 𝑥 𝑒 = 𝑒 𝑒 = 1 – 𝑧𝑦 = 𝑧 𝑧𝑦1 + 1 − 𝑧 𝑦0 = 𝑧𝑦1 (∵ 𝑧 ∈ 0,1 ゆえ 𝑧2 = 𝑧, 𝑧 1 − 𝑧 = 0) – 𝐸 𝑧𝑦 𝑒 = 𝐸 𝑧𝑦1 𝑒 = 𝐸 𝑥 𝐸 𝑧𝑦1 𝑒 |𝑥 = 𝐸 𝑥 1 𝑒 𝐸 𝑧 𝑥 𝐸 𝑦1 𝑥 ∵ 𝑧 ⊥ 𝑦𝑗 𝑥 = 𝐸 𝑥 𝐸 𝑦1 𝑥 = 𝐸 𝑦1 – ∴ 𝐸 𝑦1 = 𝑖=1 𝑁 𝑧 𝑖 𝑦 𝑖 𝑒 𝑖 𝑖=1 𝑁 𝑧 𝑖 𝑒 𝑖 = 1 𝑁 𝑖=1 𝑁 𝑧 𝑖 𝑦 𝑖 𝑒 𝑖 1 𝑁 𝑖=1 𝑁 𝑧 𝑖 𝑒 𝑖 → 𝐸 𝑧𝑦 𝑒 𝐸 𝑧 𝑒 = 𝐸 𝑦1 • 𝑦0 についても同様 書籍はこのステップが なぜか省略されている
25.
IPW 推定量の漸近分散 • 推定量がどれくれい信頼できるかの見積もり 𝑁
𝐸 𝑦𝑗 − 𝐸 𝑦𝑗 ~𝑁 0, 𝜎2 where 𝜎2 = 1 𝑁 𝑖=1 𝑁 𝑧𝑖 𝑦𝑖 − 𝐸 𝑦1 2 𝑒𝑖 2 + 1 − 𝑧𝑖 𝑦𝑖 − 𝐸 𝑦0 2 1 − 𝑒𝑖 2 • M推定量の枠組みから導く – 一致推定量とその分散が得られるフレームワーク
26.
書籍の M 推定量まわりの話 •
全部フォローしていると大変なので部分的に – ここからしばらく、書籍を持っていること前提で 差分だけ書く。持ってない人ごめんなさい – 書籍では、目的関数を =0 とおいてその解が求め る推定量だったり、別の場所では目的関数を最適 化してその最大・最小を与えるのが推定量だった りとゴッチャなのだが、そこはツッコまない。
27.
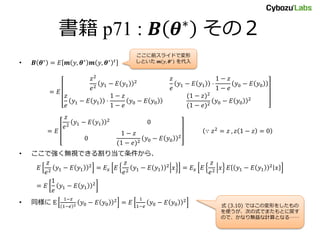
書籍 p70 – 書籍の記号では混乱するので、思い切って変える –
書籍では真値は 𝜃0 だが、それはパラメータに使いたいので、𝜃∗ を真値とした • 付録 A.1 節での 𝜽 = 𝜃1, 𝜃0 𝑡 を真値 𝜽∗ が 𝐸 𝑦1 , 𝐸 𝑦0 𝑡 である母数 とし、 関数 𝒎 を 𝒎 𝑦, 𝜽 = 𝑧 𝑒 𝑦 − 𝜃1 , 1 − 𝑧 1 − 𝑒 𝑦 − 𝜃0 𝑡 • とおけば、 𝐸 𝒎 y, 𝜽 = 0 は 𝐸 𝑦1 , 𝐸 𝑦0 𝑡 を解に持つM推定量の推定方 程式となり、式(A.2)は 1 𝑁 𝑖=1 𝑁 𝑧𝑖 𝑒𝑖 𝑦𝑖 − 𝜃1 , 1 − 𝑧𝑖 1 − 𝑒𝑖 𝑦𝑖 − 𝜃0 = 0 • となる。これを 𝜃1, 𝜃0 について解くと IPW 推定量 (3.8) が得られる。 これ最重要ポイント 𝜃をこうおけば、あとは普通に 式展開できるようになる
28.
書籍 p71 :
𝑨 𝜽∗ 𝑨 𝜽∗ = 𝐸 − 𝜕 𝜕𝜽 𝑡 𝒎 𝑦, 𝜽 𝜽=𝜽∗ = 𝐸 − 𝜕 𝜕𝜃1 𝑧 𝑒 𝑦 − 𝜃1 − 𝜕 𝜕𝜃0 𝑧 𝑒 𝑦 − 𝜃1 − 𝜕 𝜕𝜃1 1 − 𝑧 1 − 𝑒 𝑦 − 𝜃0 − 𝜕 𝜕𝜃0 1 − 𝑧 1 − 𝑒 𝑦 − 𝜃0 𝜽=𝜽∗ = 𝐸 𝑧 𝑒 0 0 1 − 𝑧 1 − 𝑒 𝜽=𝜽∗ = 1 0 0 1 最後の等号は 𝐸 𝑧|𝑥 = 𝑒 などを 使って IPW と同様に
29.
書籍 p71 :
𝑩 𝜽∗ その1 – Bの計算の前に、この変形をすましとくと楽 • 𝑧2 = 𝑧 , 𝑧 1 − 𝑧 = 0 より 𝑧𝑦 = 𝑧 𝑧𝑦1 + 1 − 𝑧 𝑦0 = 𝑧𝑦1 • 同様に 1 − 𝑧 𝑦 = 1 − 𝑧 𝑦0 ∴ 𝒎 𝑦, 𝜽 = 𝑧 𝑒 𝑦 − 𝜃1 , 1 − 𝑧 1 − 𝑒 𝑦 − 𝜃0 𝑡 = 𝑧 𝑒 𝑦1 − 𝜃1 , 1 − 𝑧 1 − 𝑒 𝑦0 − 𝜃0 𝑡
30.
書籍 p71 :
𝑩 𝜽∗ その2 • 𝑩 𝜽∗ = 𝐸 𝒎 𝑦, 𝜽∗ 𝒎 𝑦, 𝜽∗ 𝑡 = 𝐸 𝑧2 𝑒2 𝑦1 − 𝐸 𝑦1 2 𝑧 𝑒 𝑦1 − 𝐸 𝑦1 ⋅ 1 − 𝑧 1 − 𝑒 𝑦0 − 𝐸 𝑦0 𝑧 𝑒 𝑦1 − 𝐸 𝑦1 ⋅ 1 − 𝑧 1 − 𝑒 𝑦0 − 𝐸 𝑦0 (1 − 𝑧)2 (1 − 𝑒)2 𝑦0 − 𝐸 𝑦0 2 = 𝐸 𝑧 𝑒2 𝑦1 − 𝐸 𝑦1 2 0 0 1 − 𝑧 (1 − 𝑒)2 𝑦0 − 𝐸 𝑦0 2 ∵ 𝑧2 = 𝑧 , 𝑧 1 − 𝑧 = 0 • ここで強く無視できる割り当て条件から、 𝐸 𝑧 𝑒2 𝑦1 − 𝐸 𝑦1 2 = 𝐸 𝑥 𝐸 𝑧 𝑒2 𝑦1 − 𝐸 𝑦1 2 𝑥 = 𝐸 𝑥 𝐸 𝑧 𝑒2 𝑥 𝐸 𝑦1 − 𝐸 𝑦1 2 𝑥 = 𝐸 1 𝑒 𝑦1 − 𝐸 𝑦1 2 • 同様に E 1−𝑧 1−𝑒 2 𝑦0 − 𝐸 𝑦0 2 = 𝐸 1 1−𝑒 𝑦0 − 𝐸 𝑦0 2 ここに前スライドで変形 しといた 𝒎 𝑦, 𝜽∗ を代入 式 (3.10) ではこの変形をしたもの を使うが、次の式でまたもとに戻す ので、かなり無益な計算となる……
31.
書籍 p71 :
式(3.10) • IPW 推定量 𝜃 = 𝐸 𝑦1 , 𝐸 𝑦0 の漸近分散𝑽 𝜽∗ は 𝑽 𝜽∗ = 𝑨 𝜽∗ −1 𝑩 𝜽∗ 𝐀 𝜽∗ −1 𝑡 = 𝑩 𝜽∗ • 𝑽 𝜽∗ = 𝑩 𝜽∗ から 𝐸 𝑦1 と 𝐸 𝑦0 の漸近相関は 0 であり、 よって IPW 推定量にもとづく因果効果 𝐸 𝑦1 − 𝐸 𝑦0 の漸近 分散は、 var 𝑁 𝐸 𝑦1 − 𝐸 𝑦0 = var 𝑁 𝐸 𝑦1 + var 𝑁 𝐸 𝑦0 = 𝐸 1 𝑒 𝑦1 − 𝐸 𝑦1 2 + 𝐸 1 1 − 𝑒 𝑦0 − 𝐸 𝑦0 2 (3.10改) 書籍では式 (3.10) のあとに「ただし、実際には これは計算できないので~」と続くが、式 (3.10) はほぼ計算できる。よって計算できない式に改め、 その後の文章の意味が通じるようにした
32.
書籍 p71 :
(3.10) の次の式 – 式(3.10)の次の行から • ただし実際にはこれは計算出来ないので、𝐸 𝑦1 らを 推定量に、外側の期待値を観測平均で置き換えたもの を利用したいが、そのままでは欠測値 𝑦𝑗 が出てきて しまう。そこで 𝑧/𝑒2 から 1/𝑒 への置き換えをやめて 元に戻すと、欠測値の係数が 0 になり計算できるよう になる。 1 𝑁 𝑖=1 𝑁 𝑧𝑖 𝑦𝑖1 − 𝐸 𝑦1 2 𝑒𝑖 2 + 1 − 𝑧𝑖 𝑦𝑖0 − 𝐸 𝑦0 2 1 − 𝑒𝑖 2
33.
書籍 p71 :
母数𝜶も同時に推定 – 𝜶も同時に推定した場合の漸近分散の結果だけあるが、M推定量のセッ ティングが明記されていないので、定式化する • ……母数𝜶を最尤法で推定する場合には、関数𝒎に対数尤度の導関 数ベクトルを追加する。すなわち 𝜽 = 𝜃1, 𝜃0, 𝜶 𝑡 𝑡 としたとき 𝒎 𝑦, 𝑧, 𝑥, 𝜽 ≔ 𝑧 𝑒 𝑦 − 𝜃1 , 1 − 𝑧 1 − 𝑒 𝑦 − 𝜃0 , 𝜕 𝜕𝜶 𝑡 𝐿 𝜶 𝑡 • ただし 𝑒 = 𝑒 𝜶 = 𝑝 𝑧 = 1 𝒙; 𝜶 = 1 1 + exp −𝜶 𝑡 𝒙 𝐿 𝜶 = 𝑧 log 𝑒 + 1 − 𝑧 log(1 − 𝑒) • とおけば、𝒎 𝑦, 𝑧, 𝑥, 𝜽 は推定方程式となり、同様に M-推定量の議 論をすればよい。
34.
あとはがんばったら きっとできるので 省略
35.
2.7 章の実験(モデル) • 2.7
章では傾向スコアを使った解析はバイアスが小さい という実験結果が示されていたので、確認してみる • 割り付け – p(x|z=1) = N(1,1), p(x|z=0) = N(-1,1) – p(z=1)=1/2 – このとき、𝑝 𝑧 = 1 𝑥 = 1 / 1 + exp −2𝑥 • 結果変数 – 𝑦𝑖𝑗 = 𝜏𝑗 + 𝛽𝑗 𝑥𝑖 + 𝜖𝑖𝑗, 𝜖𝑖𝑗~𝑁 0,1 𝑗 = 1,0 – 例) 𝜏1 = 2.0, 𝛽1 = 1.5, 𝜏0 = 0.0, 𝛽0 = 1.0 緑は z=1, 赤は z=0。直線は真の回帰直線
36.
実験(層別解析 vs IPW) •
𝜏1 = 2.0, 𝜏0 = 0.0 のまま (因果効果の真値=2) 𝛽1 − 𝛽0 を [-5,5] で変化 • 因果効果を層別解析と IPW とで推定しプロット – 𝑥 ≤ −2, −2 < 𝑥 ≤ − 1, −1 < 𝑥 ≤ 0,0 < 𝑥 ≤ 1,1 < 𝑥 ≤ 2,2 < 𝑥 の6つの 層に分け、各層での𝑦1, 𝑦0 の平均の差の重み付け平 均を取る • IPW はバイアスが小さく、 層別解析は分散が小さい? 横軸が 𝛽1 − 𝛽0 、縦軸が推定量(真値=2) 赤が層別解析による因果効果の推定量、緑が IPW 推定量
37.
例)外傷センターの有用性 (MacKenzie+ 2006) – 外傷センター:外傷治療に特化した救命救急センター •
患者 5043人の治療予後を比較 – 処置群:質の高い外傷センターのある18病院 – 対照群:外傷センターを持たない51病院 – 共変量:処置群は年齢が低く、依存疾患が少なく、男性・ 非白人・保険未加入者が多く、症状の程度が重い • 症状に関する変数を加えて IPW 推定量を計算 – 処置群での入院中の死亡率は有意に低く(7.6%<9.5%)、 1年以内の死亡率も有意に低かった(10.4%<13.8%)
38.
例)小学校での英語教育の国語への影響 (Ojima and Hagiwara
2007) • 国語テストの平均得点を比較 – 処置群:低学年から英語教育を行う学校に通う子供 – 対照群:行っていない学校に通う子供 – 単純標本平均は処置群 79.49(標準誤差 1.528) に対し、対照 群 84.87(標準誤差 1.377)。p値も 0.009 と有意に低い? • 対照群の学校は転勤族が多く住む地域で、親の学歴や 教育費が高かった。これらの共変量を取り入れ IPW 推定量による周辺期待値の推定値を求めると、処置群 83.60±1.627、対照群 80.56±1.644、p値も 0.094 となり、 「国語テスト得点にほぼ違いがない」 「書き言葉に慣れていない低学年への英語 教育は、日本語学習に支障があるのでは」
39.
3.3 一般化推定方程式 • 結果変数が共分散を持つ(つまり
iid ではない) 一般化線形モデルを解く手法(Liang and Zeger 1986) • 𝑦 の 𝑤 への回帰関数を 𝜇(𝑤; 𝛽) とする • 結果変数の variance structure 𝑉𝑖 に対し、 𝑖=1 𝑁 𝑆𝑖 𝛽 = 𝑖=1 𝑁 𝜕𝜇 𝑤𝑖; 𝛽 𝜕𝛽 𝑡 𝑉𝑖 −1 𝑦𝑖 − 𝜇 𝑤𝑖; 𝛽 = 0 • を解くと、母数 𝛽 の一致推定量が得られる – 多変量ガウス分布の平均の最尤推定と同じ式? 結果変数同士の相関を 反映した「作業共分散行列」 ※章の流れ的に因果効果に関係あるとばかり思っていて混乱した。実は因果効果は 直接は関係なく、IPW の考え方を一般化推定方程式に使った時の話
40.
一般化推定方程式 with 欠測値 •
結果変数 𝑦 が欠測する場合: – 𝑧 を欠測するかどうかを表す変数とする • 𝑧 が従属変数 𝑤 にのみ依存する、つまり 𝑝 𝑧𝑖 𝑦𝑖, 𝑤𝑖 = 𝑝 𝑧𝑖 𝑤𝑖 なら、 𝑖=1 𝑁 𝑧𝑖 𝜕𝜇 𝑤𝑖; 𝛽 𝜕𝛽 𝑡 𝑉𝑖 −1 𝑦𝑖 − 𝜇 𝑤𝑖; 𝛽 = 0 – は 𝛽 の一致推定量を与える • 𝑧 が従属変数 𝑤 以外にも依存する変数 𝑥 があるなら、 – モデル 𝑝 𝑧𝑖 𝑥𝑖, 𝑤𝑖; 𝛼 を考え、𝜒𝑖 𝛼 = 1 𝑝 𝑧𝑖 𝑥𝑖, 𝑤𝑖; 𝛼 とおくと 𝑖=1 𝑁 𝜒𝑖 𝛼 𝜕𝜇 𝑤𝑖; 𝛽 𝜕𝛽 𝑡 𝑉𝑖 −1 𝑦𝑖 − 𝜇 𝑤𝑖; 𝛽 = 0 – は 𝛽 の一致推定量を与える(Robins+ 1994) 逆確率重み付け! 反実仮想的枠組みを入れる
41.
3.4 傾向スコアによる重み付き M
推定量 • 目的: 𝐸 𝑦1 − 𝑦0 や 𝐸 𝑦𝑗 ではなく、𝑝 𝑦𝑗 = 𝑝 𝑦𝑗 𝜃 が知りたい – 結果変数や共変量以外の変数との関係を見たい – 結果変数間の相関構造を見たい • N人の対象者は 𝐽 個の群いずれかに属す – 𝑧𝑖 ∈ {1, ⋯ , 𝐽} : i 番目の対象者が属する群 – 𝑧𝑖𝑗 = 1 (𝑧𝑖 = 𝑗), 𝑧𝑖𝑗 = 0 (𝑧𝑖 ≠ 𝑗) – 𝑦𝑖𝑗 : i 番目の対象者が j 群に属した時の潜在的な結果変数 – 𝑥𝑖 : i 番目の対象者の共変量
42.
PME(Propensity score weighted
M-Estimator) • ∀ 𝑦𝑖𝑗 が観測されるときのM-推定関数を 𝑚𝑗 𝑦𝑖𝑗 𝜃 とする – とりあえず対数尤度を想像しておくといい – 1 𝑁 𝑖=1 𝑁 𝑗=1 𝐽 𝑚𝑗 𝑦𝑖𝑗 𝜃 を最大化する 𝜃 を求める流れ • しかし実際には 𝑧𝑖𝑗 = 0 な 𝑦𝑖𝑗 は欠測 – そこで次の目的関数 𝑄 𝑊 を最適化する 𝜃 = 𝜃 を求める 𝑄 𝑊 𝑦, 𝑥, 𝑧 𝜃, 𝛼 = 1 𝑁 𝑖=1 𝑁 𝑗=1 𝐽 𝑧𝑖𝑗 𝑒𝑗 𝑥𝑖, 𝛼 𝑚𝑗 𝑦𝑖𝑗 𝜃 – ただし 𝑒𝑗 𝑥𝑖, 𝛼 = 𝑝 𝑧𝑖 = 𝑗 𝑥𝑖 は一般化傾向スコアの推定値 – M-推定量の議論から、 𝜃 は 𝜃 の真値の一致推定量となる • 漸近分散も評価できるが、そのへんもろもろは省略 推定値が推定「方程式の解」 ではなく推定「関数の最適 化」によって与えられる話に 変わっているので注意。 まじめにやるなら、ここで推 定関数と呼んでいるものの 偏微分=0 を推定方程式とす るべきなのだろう
43.
IPW なアプローチの問題点 • 𝑝
𝑧 = 1 𝑥 の推定時には対照群の共変量の情 報を用いているが、平均や母数の推定時には 用いない(重み 0 のため項ごと消える) – もったいない! • 𝑝 𝑧 = 1 𝑥 のモデル(一般にロジスティック 回帰)が正しくない(=真のモデルとかけはなれている?) 場合に、誤った結果を与える可能性がある
44.
3.5 二重にロバストな推定 (Doubly Robust
Estimator) • 𝑔 𝑥; 𝛽1 を 𝑦1 の 𝑥 における回帰関数(≈ 𝐸 𝑦1 𝑥 )、 𝛽1 をその母数の一致推定量とするとき 𝐸 𝐷𝑅 𝑦1 ≔ 1 𝑁 𝑁 𝑧𝑖 𝑒 𝑥𝑖, 𝛼 𝑦𝑖1 + 1 − 𝑧𝑖 𝑒 𝑥𝑖, 𝛼 𝑔 𝑥𝑖, 𝛽1 • はある条件の下で 𝐸 𝑦1 の一致推定量を与える – IPW では 𝑧/𝑒を平均の重みとする – DR では 𝑧/𝑒: 1 − 𝑧/𝑒 を観測値と、回帰による推定値 との配分の割合とする • 𝐸 𝐷𝑅 𝑦0 も同様に定義
45.
𝐸 𝐷𝑅 が一致推定量となる条件 第2項が0になればいい • 次の条件A
or B が成立すれば 𝐸 𝐷𝑅 𝑦1 は 𝐸 𝑦1 の一致推定量 – 条件A: 𝑝 𝑧 = 1 𝑥 のモデルが正しい – 条件B: 𝑔 𝑥; 𝛽1 のモデルが正しい • ∵ 𝐸 𝐷𝑅 𝑦1 の式から 𝑦𝑖1 をくくりだすと 𝐸 𝐷𝑅 𝑦1 = 1 𝑁 𝑁 𝑦𝑖1 + 𝑧𝑖 − 𝑒 𝑥𝑖, 𝛼 𝑒 𝑥𝑖, 𝛼 𝑦𝑖1 − 𝑔 𝑥𝑖, 𝛽1 → 𝐸 𝑦1 + 𝐸 𝑧 − 𝑒 𝑥, 𝛼∗ 𝑒 𝑥, 𝛼∗ 𝑦1 − 𝑔 𝑥, 𝛽1 ∗ – ただし 𝛼∗, 𝛽1 ∗ はそれぞれの極限 • 「正しいモデル」 なら 𝛼 らは一致推定量ゆえ、極限では真値に収束 IPW のとこでも書いたけど、 本では期待値を取っているが、 示したいのは一致性なので 極限を取るべき
46.
• A ⇒
第2項= 𝐸 𝑦,𝑥 𝐸𝑧|𝑦,𝑥 𝑧−𝑒 𝑥,𝛼∗ 𝑒 𝑥,𝛼∗ 𝑦1 − 𝑔 𝑥, 𝛽1 ∗ – 𝑦𝑗 ⊥ 𝑧|𝑥 より 𝐸𝑧|𝑦,𝑥 𝑧 = 𝐸𝑧|𝑥 𝑧 = 𝑒 𝑥, 𝛼∗ – ∴ 第2項=0 • B ⇒第2項= 𝐸𝑧,𝑥 𝐸 𝑦|𝑧,𝑥 𝑧−𝑒 𝑥,𝛼∗ 𝑒 𝑥,𝛼∗ 𝑦1 − 𝑔 𝑥, 𝛽1 ∗ – 𝑔 が正しいなら、𝐸 𝑦|𝑥 𝑦1 = 𝑔 𝑥, 𝛽1 ∗ – ∴ 第2項=0
47.
PME のロバスト化 • 同様に推定方程式と、周辺の共変量を 使った推定値とを
𝑧/𝑒: 1 − 𝑧/𝑒 の割合で混 ぜる
48.
3.6 𝑝(𝑦|𝑧) の母数推定 •
𝑇𝐸𝑇 = 𝐸 𝑦1 𝑧 = 1 − 𝐸 𝑦0 𝑧 = 1 を推定するには 𝑝 𝑦 𝑧 の考 え方を利用 – 何も仮定(モデル)を置かなければ、欠測している網掛け部の母数 を推定できない • 強く無視できる割り当て仮定のもとで、𝑝 𝑦1 𝑧 = 0, 𝜃10 の母 数𝜃10 (or統計量)の一致推定量は – 𝐸 𝑦1|𝑧=0 𝜕 𝜕𝜃10 𝑚10 𝑦1 𝜃10 = 0 を満たす推定関数𝑚10について – 𝑄10 𝑊 = 1 𝑁 𝑖=1 𝑁 𝑧 𝑖 1−𝑒 𝑥 𝑖, 𝛼 𝑒 𝑥 𝑖, 𝛼 𝑚10 𝑦𝑖1 𝜃10 を最大化する 𝜃10
49.
• とくに 𝜇10
= 𝐸 𝑦1 𝑧 = 0 を推定するなら – 𝑄10 𝑊 = − 1 𝑁 𝑖=1 𝑁 𝑧 𝑖 1−𝑒 𝑥 𝑖, 𝛼 𝑒 𝑥 𝑖, 𝛼 𝑦𝑖 − 𝜇10 2 として – 𝜇10 = 𝑖=1 𝑁 𝑧 𝑖 1−𝑒 𝑥 𝑖, 𝛼 𝑒 𝑥 𝑖, 𝛼 𝑦 𝑖 𝑖=1 𝑁 𝑧 𝑖 1−𝑒 𝑥 𝑖, 𝛼 𝑒 𝑥 𝑖, 𝛼 が得られる • 同様に 𝜇01 を求めて、 – 𝑇𝐸𝑇 = 𝑦1 − 𝜇01 = 𝑦1 − 𝑖=1 𝑁 1−𝑧 𝑖 𝑒 𝑥 𝑖, 𝛼 1−𝑒 𝑥 𝑖, 𝛼 𝑦 𝑖 𝑖=1 𝑁 1−𝑧 𝑖 𝑒 𝑥 𝑖, 𝛼 1−𝑒 𝑥 𝑖, 𝛼 • さらに同様に二重にロバストな推定量を求めることもできる
50.
3.7 操作変数法 • 回帰分析モデルでは説明変数と誤差が無相関 である仮定が要請される –
𝑦 = 𝜃1 + 𝜃2 𝑥 + 𝜖 において 𝑥 ⊥ 𝜖 • 一般にはこの仮定は満たされない – 成績、病気の致死率のばらつき 𝜖 は人 𝑥 による • 「操作変数」を導入 – 独立変数(割り当て)とは相関があるが、誤差とは 無相関な変数
51.
例:コロンビアの教育バウチャー制度 • 私立中学の授業料の半額を補助 – 対象:くじ(無作為)で当たった9万人の生徒のう ち、私立中学に入学した者 •
この制度の因果効果を推定するには? – 割り当て 𝑧 = 1 は「くじで当たった群」? • 当たっても半額じゃ私立に行けないから辞退 – それとも「くじに当たって私立入学」? • 当たらなくても私立に行く=保護者が裕福=成績高め • 誤差と相関あり
52.
LATE / 操作変数 •
𝑧 ∈ {1,0} : くじ当たり(1)/はずれ(0) (操作変数) • 𝑑 ∈ {1,0} : 私立入学(1)/入学せず(0) (割り当て) – 𝑑1:くじに当たったら~、𝑑0:くじにはずれたら~ – 𝑑 = 𝑧𝑑1 + 1 − 𝑧 𝑑0 • 𝑦1:私立入学した場合の成績、𝑦0:しなかった場合 (結果変数) – 𝑦 = 𝑑𝑦1 + 1 − 𝑑 𝑦0 • バウチャーの効果 = 𝐸 𝑦1 − 𝑦0 𝑑1 = 1, 𝑑0 = 0 – 「くじに当たったら私立に行くが、はずれたら行かない」(𝑑1 = 1, 𝑑0 = 0)群が私立に行った場合の成績上昇度 – 𝑧 (実際にくじが当たったかどうか)は見ていない LATE (Local Averate Treatment Effect)
53.
Assumption of LATE
[Angrist+ 1996] – LATE に課される一般的な仮定 – 書籍でも一応触れられてはいるのだが、 𝑑 𝑧 ⊥ 𝑧 とか解釈のしよ うがないため、元論文を参照 • d は同じ対象者の z のみに依存 • y は同じ対象者の d のみに依存 i.e. 𝑦1, 𝑦0 ⊥ 𝑧 | 𝑑 • 𝐸 𝑑1 − 𝑑0 ≠ 0、とくに d は z と独立でない • z は無作為(P(z=1) が個体によらない) • 単調性 : 𝑑1 ≥ 𝑑0 – defiers (𝑑1 = 0, 𝑑0 = 1) はいない • この仮定のもとで 𝐿𝐴𝑇𝐸 = 𝐸 𝑦 𝑧 = 1 −𝐸 𝑦 𝑧 = 0 𝐸 𝑑 𝑧 = 1 −𝐸 𝑑 𝑧 = 0 くじが当たったら私立行かない はずれたら行く
54.
3.8 回帰分断デザイン • 書籍でも雰囲気に触れているだけなので パス
55.
3.9 差分の差 • 経済・政治・教育における「介入」の効果 –
処置群(介入対象)と対照群は質的に大きく異なる ことが多い • 対象の観測値は介入後も比較的低く、対照群と単純比 較できない(例:成績悪いから補習) • 処置前後での変化量に注目したい
56.
DID (Difference In
Differences) • 差分の差=介入後の差-介入前の差 =処置群での介入前後の差-対照群での差 • 𝐷𝐼𝐷 = 𝐸 𝑦1𝑏 − 𝑦0𝑏 − 𝐸 𝑦1𝑎 − 𝑦0𝑎 = 𝐸 𝑦1𝑏 − 𝑦1𝑎 − 𝐸 𝑦0𝑏 − 𝑦0𝑎 = 𝐸 𝑦1𝑏 − 𝑦1𝑎|𝑧 = 1 − 𝐸 𝑦0𝑏 − 𝑦0𝑎|𝑧 = 0 = 1 𝑁1 𝑖:𝑧 𝑖=1(𝑦𝑏 (𝑖) − 𝑦𝑎 𝑖 ) − 1 𝑁0 𝑖:𝑧 𝑖=0(𝑦𝑏 (𝑖) − 𝑦𝑎 𝑖 ) 本来 𝑦0𝑎, 𝑦1𝑎 を区別せず 𝑦𝑎 とするが、説明の容易さの ため、今だけ分けている 𝑦0𝑎𝑦1𝑎 𝑦1⋅, 𝑦0⋅ : 介入があった場合(z=1), 介入が なかった場合(z=0) 𝑦⋅𝑎, 𝑦⋅𝑏 : 介入前(時刻 a)、介入後(時刻 b) かんたんに 求められる
57.
DID と TET
の差 • 𝐷𝐼𝐷 = 𝐸 𝑦1𝑏 − 𝑦𝑎 𝑧 = 1 − 𝐸 𝑦0𝑏 − 𝑦𝑎 𝑧 = 0 • 𝑇𝐸𝑇 = 𝐸 𝑦1𝑏 − 𝑦0𝑏 𝑧 = 1 ∴ 𝐷𝐼𝐷 − 𝑇𝐸𝑇 = 𝐸 𝑦0𝑏 − 𝑦𝑎 𝑧 = 1 − 𝐸 𝑦0𝑏 − 𝑦𝑎 𝑧 = 0 • DID と TET が等しい ⇔ 𝐸 𝑦0𝑏 − 𝑦𝑎 𝑧 = 1 − 𝐸 𝑦0𝑏 − 𝑦𝑎 𝑧 = 0 = 0 – つまり「介入対象とならなかったときの2群の経 時変化が等しい」と仮定すれば、 TET=DID 本では謎い式変形をしているが 単純に引けばいい
58.
セミパラメトリックな「差分の差」推定 • p106 の
TET などの数式展開が間違ってい る – × 𝐸 ⋅ 𝑧 = 1 = 𝐸 𝑥 𝐸 ⋅ 𝑧 = 1, 𝑥 – ○ 𝐸 ⋅ 𝑧 = 1 = 𝐸 𝑥|𝑧=1 𝐸 ⋅ 𝑧 = 1, 𝑥 • 正しい計算は元論文読まないと多分わか らない(まだ読んでない)
Download









![因果効果 on 強く無視できる割り当て
• 𝑝 𝑦1, 𝑦0 𝑧, 𝒙 = 𝑝 𝑦1, 𝑦0 𝒙 から、平均での独
立性が得られる
– 𝐸 𝑦1 𝑧 = 1, 𝒙 = 𝐸 𝑦1 𝒙
– 𝐸 𝑦0 𝑧 = 0, 𝒙 = 𝐸 𝑦0 𝒙
• よって
𝐸 𝑦1 − 𝐸 𝑦0
= 𝐸 𝒙 𝐸 𝑦1 − 𝐸 𝑦0
= 𝐸 𝒙[𝐸 𝑦1 𝑧 = 1, 𝒙 − 𝐸 𝑦0 𝑧 = 0, 𝒙 ]](https://image.slidesharecdn.com/observationalstudy2-150914035024-lva1-app6892/85/3-10-320.jpg)





![• [⇒] 𝑥 を止めた時 𝑏(𝑥) も止まるので 𝑝 𝑧 𝑥 = 𝑝 𝑧 𝑥, 𝑏 𝑥 より
𝑝 𝑧 𝑥 = 𝑝 𝑧 𝑥, 𝑏 𝑥 = 𝑝 𝑧 𝑏 𝑥
よって 𝑔 𝑏 𝑥 ≔ 𝑝(𝑧 = 1|𝑏 𝑥 ) とおけばよい
• [⇐] 𝑝 𝑧 = 1 𝑏 𝑥 = 𝑝(𝑧 = 1|𝑥) を示せば良い
𝑒 = 𝑏(𝑥) を固定して、
𝑝 𝑧 = 1 𝑏 𝑥 = 𝑒
=
𝑥|𝑏 𝑥 =𝑒
𝑝 𝑧 = 1, 𝑥 𝑏 𝑥 = 𝑒 𝑑𝑥
=
𝑥|𝑏 𝑥 =𝑒
𝑝 𝑧 = 1 𝑥, 𝑏 𝑥 = 𝑒 𝑝 𝑥 𝑏 𝑥 = 𝑒 𝑑𝑥
=
𝑥|𝑏 𝑥 =𝑒
𝑔 𝑏 𝑥 = 𝑒 𝑝(𝑥|𝑏 𝑥 = 𝑒)𝑑𝑥
= 𝑔 𝑏 𝑥 = 𝑒
𝑥|𝑏 𝑥 =𝑒
𝑝(𝑥|𝑏 𝑥 = 𝑒)𝑑𝑥 = 𝑔 𝑏 𝑥 = 𝑒 = 𝑝(𝑧 = 1|𝑥)
𝒙 ⊥ 𝑧|𝑏 𝒙 ⇔
∃
𝑔, 𝑝 𝑧 = 1 𝑥 = 𝑔(𝑏 𝑥 )の証明
※書籍は必要条件を証明しているように書いているが、𝑝(𝑧 = 1|𝑥) = 𝑔(𝑏(𝑥))を使って等式を導き、そ
の等式が成立するためには𝑝(𝑧 = 1|𝑥) = 𝑔(𝑏(𝑥))が必要という流れになっており、残念ながら証明とは
言えない。また、あとの傾向スコアがバランシングスコアであることを言うために使うのは十分条件の方である
[Rosenbaum, Rubin 1983] では
背理法を使っているが
その必要はない
[Rosenbaum, Rubin 1983] では
これが 𝐸 𝑝 𝑧 = 1 𝑥 𝑏 𝑥 で
あることをだけを指摘した
簡潔な証明になっている](https://image.slidesharecdn.com/observationalstudy2-150914035024-lva1-app6892/85/3-16-320.jpg)

![バランシングスコア+強く無視できる割り当て
• 𝑏 𝒙 がバランシングスコア、かつ「強く無視できる割
り当て」ならば、 𝑦𝑗と z は b(z) の元で条件付き独立
𝒙 ⊥ 𝑧|𝑏 𝒙 ⋀ 𝑦1, 𝑦0 ⊥ 𝑧|𝒙 ⇒ (𝑦1, 𝑦0) ⊥ 𝑧|𝑏 𝒙
[証明]
• (1) 𝑝 𝑧, 𝑥 𝑦1, 𝑦0, 𝑏 𝑥
= 𝑝 𝑥 𝑦1, 𝑦0, 𝑧, 𝑏 𝑥 𝑝 𝑧 𝑦1, 𝑦0, 𝑏 𝑥
= 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 𝑝 𝑧 𝑦1, 𝑦0, 𝑏 𝑥 ∵ 𝒙 ⊥ 𝑧 𝑏 𝒙
• (2) 𝑝 𝑧, 𝑥 𝑦1, 𝑦0, 𝑏 𝑥
= 𝑝 𝑧 𝑦1, 𝑦0, 𝑥, 𝑏 𝑥 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥
= 𝑝 𝑧 𝑥, 𝑏 𝑥 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 ∵ 𝑦1, 𝑦0 ⊥ 𝑧 𝒙
= 𝑝 𝑧 𝑏 𝑥 𝑝 𝑥 𝑦1, 𝑦0, 𝑏 𝑥 ∵ 𝒙 ⊥ 𝑧 𝑏 𝒙
• (1)=(2) より 𝑝 𝑧 𝑦1, 𝑦0, 𝑏 𝑥 = 𝑝 𝑧 𝑏 𝑥
※書籍の証明は積分を使っているが、上に見る通り乗法公式のみで示すことができる。またそこ
の積分では、𝑥で期待値をとっているのに𝑥が残っており、間違いにしか見えないが、これはおそらく
一度𝑔(𝑏(𝑥))に置き換えてから戻すというステップを省略しているのだと思われる。多分……。 𝑥
𝑦𝑗 𝑧
𝑏(𝑥)
グラフィカル
モデルを見れば
一目瞭然](https://image.slidesharecdn.com/observationalstudy2-150914035024-lva1-app6892/85/3-18-320.jpg)















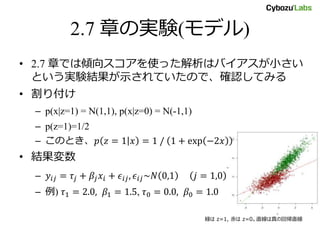
![実験(層別解析 vs IPW)
• 𝜏1 = 2.0, 𝜏0 = 0.0 のまま
(因果効果の真値=2) 𝛽1 −
𝛽0 を [-5,5] で変化
• 因果効果を層別解析と
IPW とで推定しプロット
– 𝑥 ≤ −2, −2 < 𝑥 ≤
− 1, −1 < 𝑥 ≤ 0,0 < 𝑥 ≤
1,1 < 𝑥 ≤ 2,2 < 𝑥 の6つの
層に分け、各層での𝑦1, 𝑦0
の平均の差の重み付け平
均を取る
• IPW はバイアスが小さく、
層別解析は分散が小さい?
横軸が 𝛽1 − 𝛽0 、縦軸が推定量(真値=2)
赤が層別解析による因果効果の推定量、緑が IPW 推定量](https://image.slidesharecdn.com/observationalstudy2-150914035024-lva1-app6892/85/3-36-320.jpg)
















![Assumption of LATE [Angrist+ 1996]
– LATE に課される一般的な仮定
– 書籍でも一応触れられてはいるのだが、 𝑑 𝑧 ⊥ 𝑧 とか解釈のしよ
うがないため、元論文を参照
• d は同じ対象者の z のみに依存
• y は同じ対象者の d のみに依存 i.e. 𝑦1, 𝑦0 ⊥ 𝑧 | 𝑑
• 𝐸 𝑑1 − 𝑑0 ≠ 0、とくに d は z と独立でない
• z は無作為(P(z=1) が個体によらない)
• 単調性 : 𝑑1 ≥ 𝑑0
– defiers (𝑑1 = 0, 𝑑0 = 1) はいない
• この仮定のもとで 𝐿𝐴𝑇𝐸 =
𝐸 𝑦 𝑧 = 1 −𝐸 𝑦 𝑧 = 0
𝐸 𝑑 𝑧 = 1 −𝐸 𝑑 𝑧 = 0
くじが当たったら私立行かない
はずれたら行く](https://image.slidesharecdn.com/observationalstudy2-150914035024-lva1-app6892/85/3-53-320.jpg)










































![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![A Neural Attention Model for Sentence Summarization [Rush+2015]](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2015yomi-151024073845-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems](https://cdn.slidesharecdn.com/ss_thumbnails/karger-croudsourcing-nips11-120408005300-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










