Download as PDF, PPTX





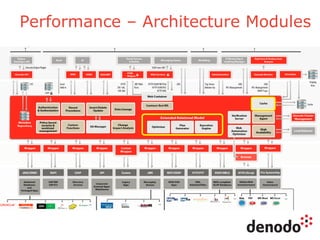





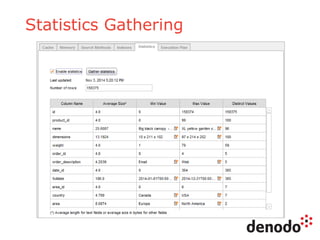



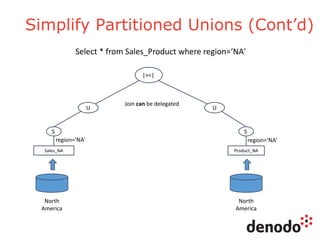
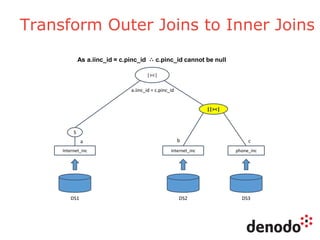


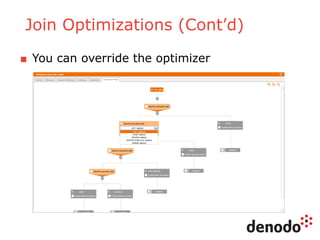
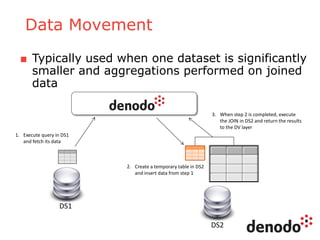







The document outlines a series of five webinars focusing on the Denodo platform, particularly addressing performance and scalability. It covers advanced query optimization techniques, architecture modules, and features of Denodo Express, a free data virtualization platform. Key topics include query plan generation, execution engine responsibilities, and mechanisms for performance optimization and caching.





























































































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)













