Downloaded 38 times



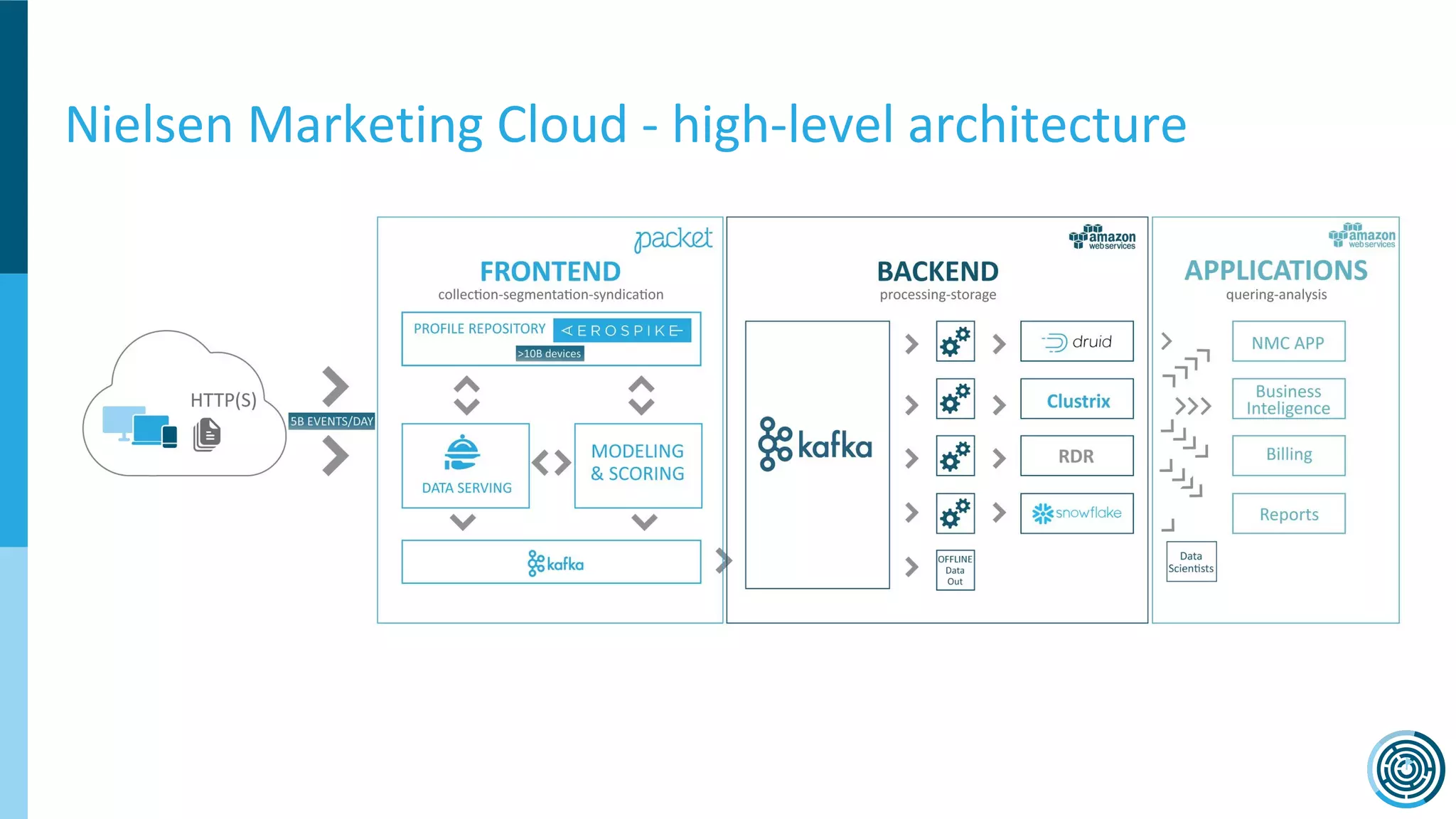

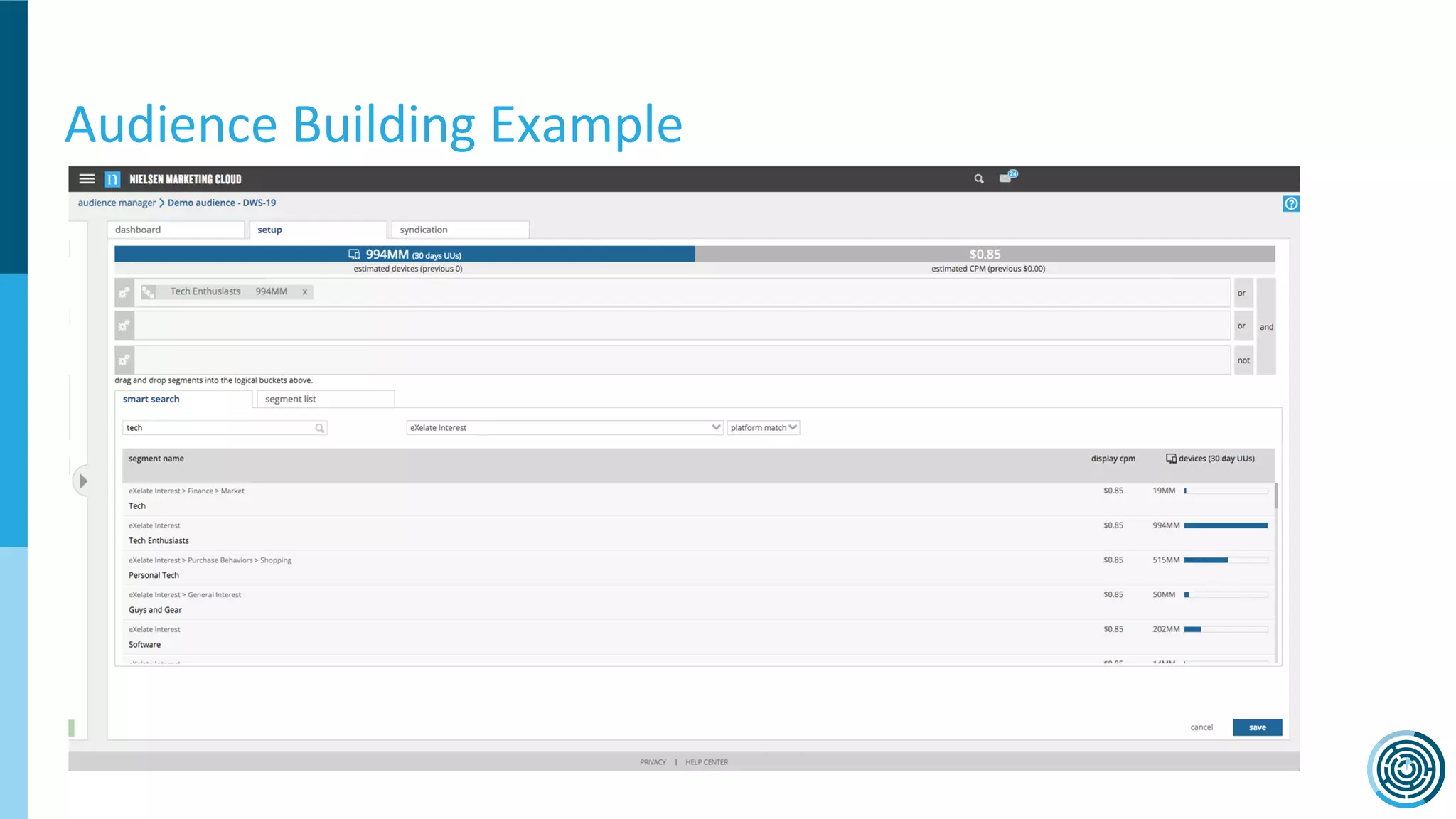

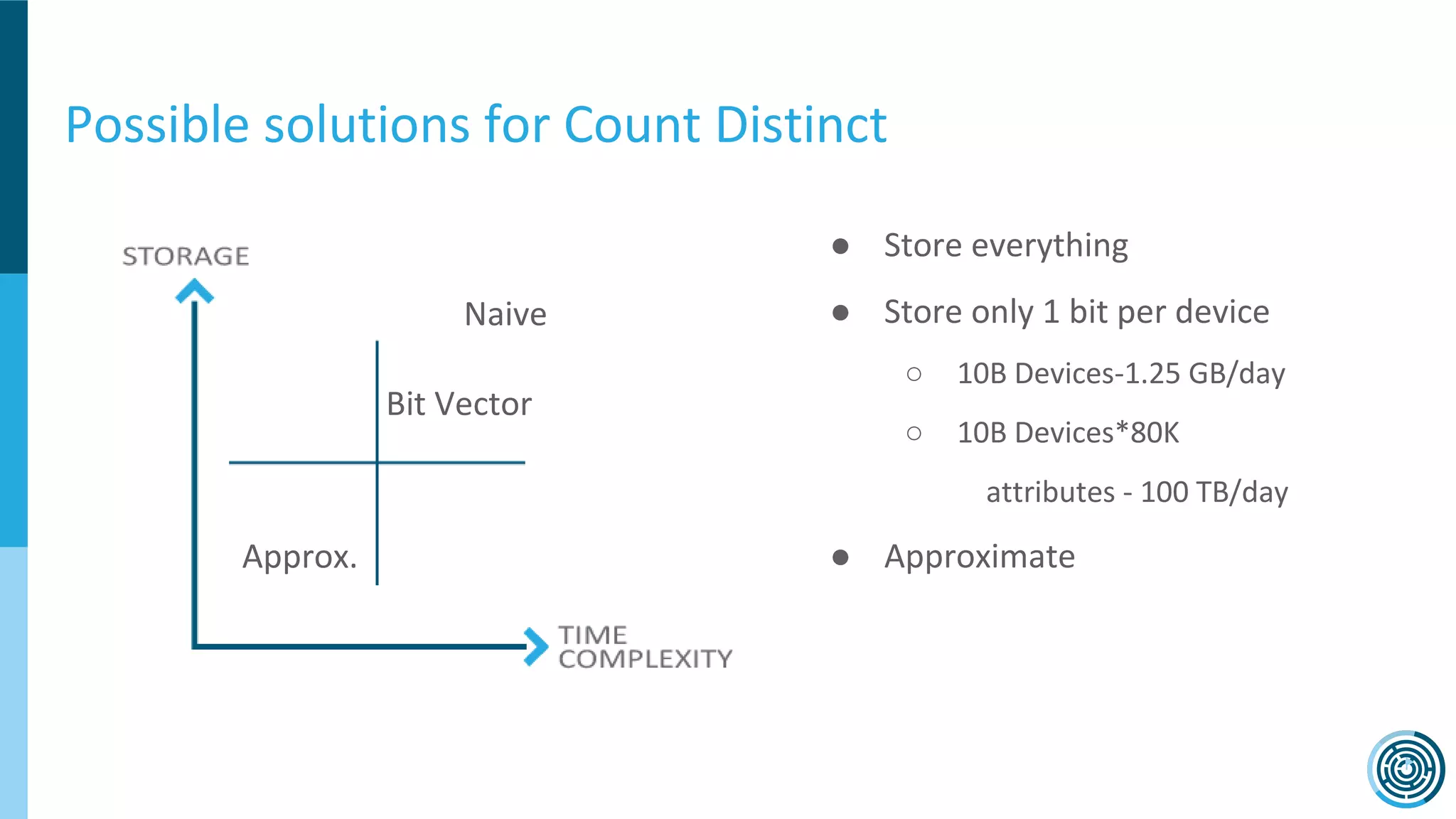

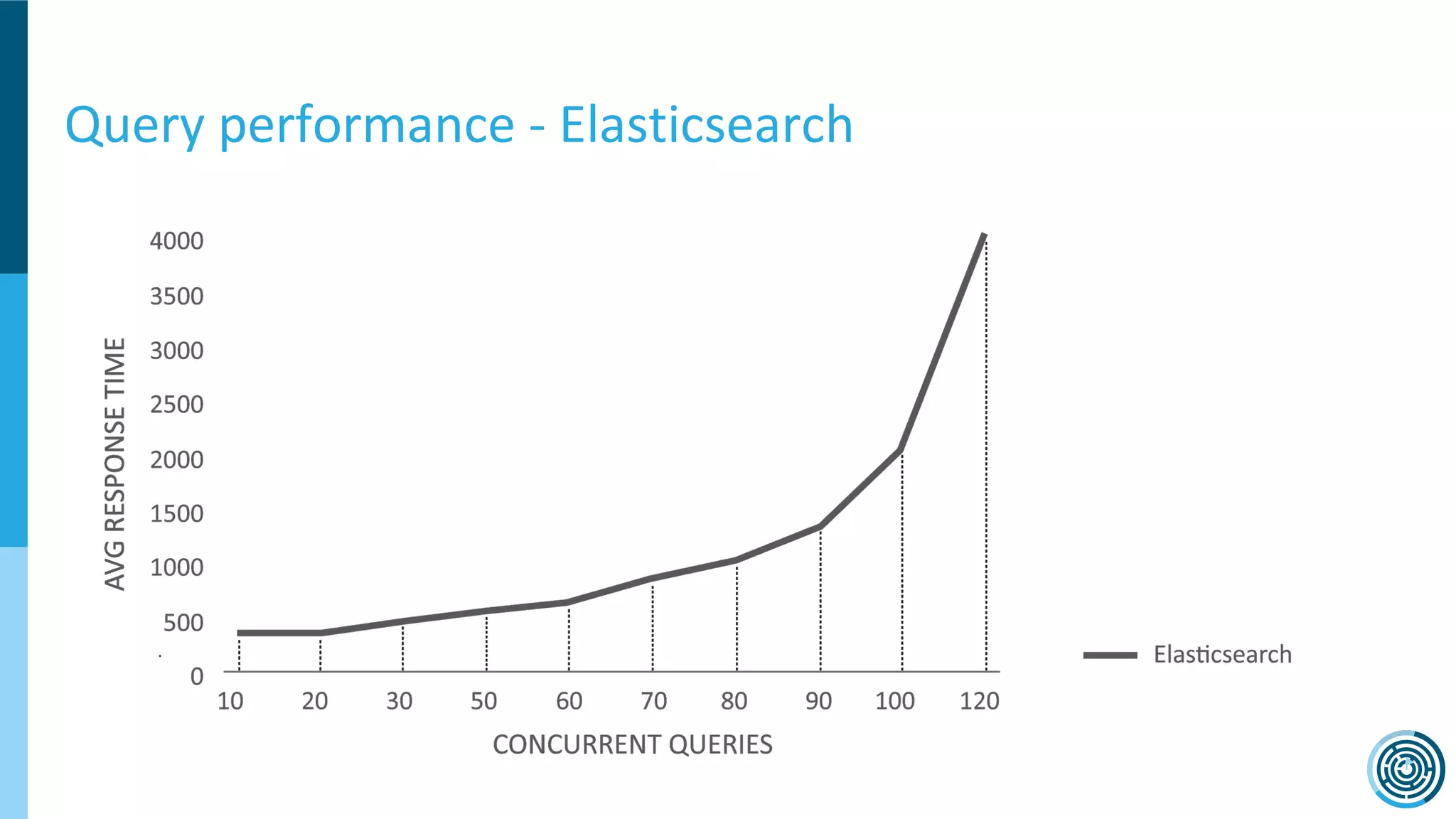

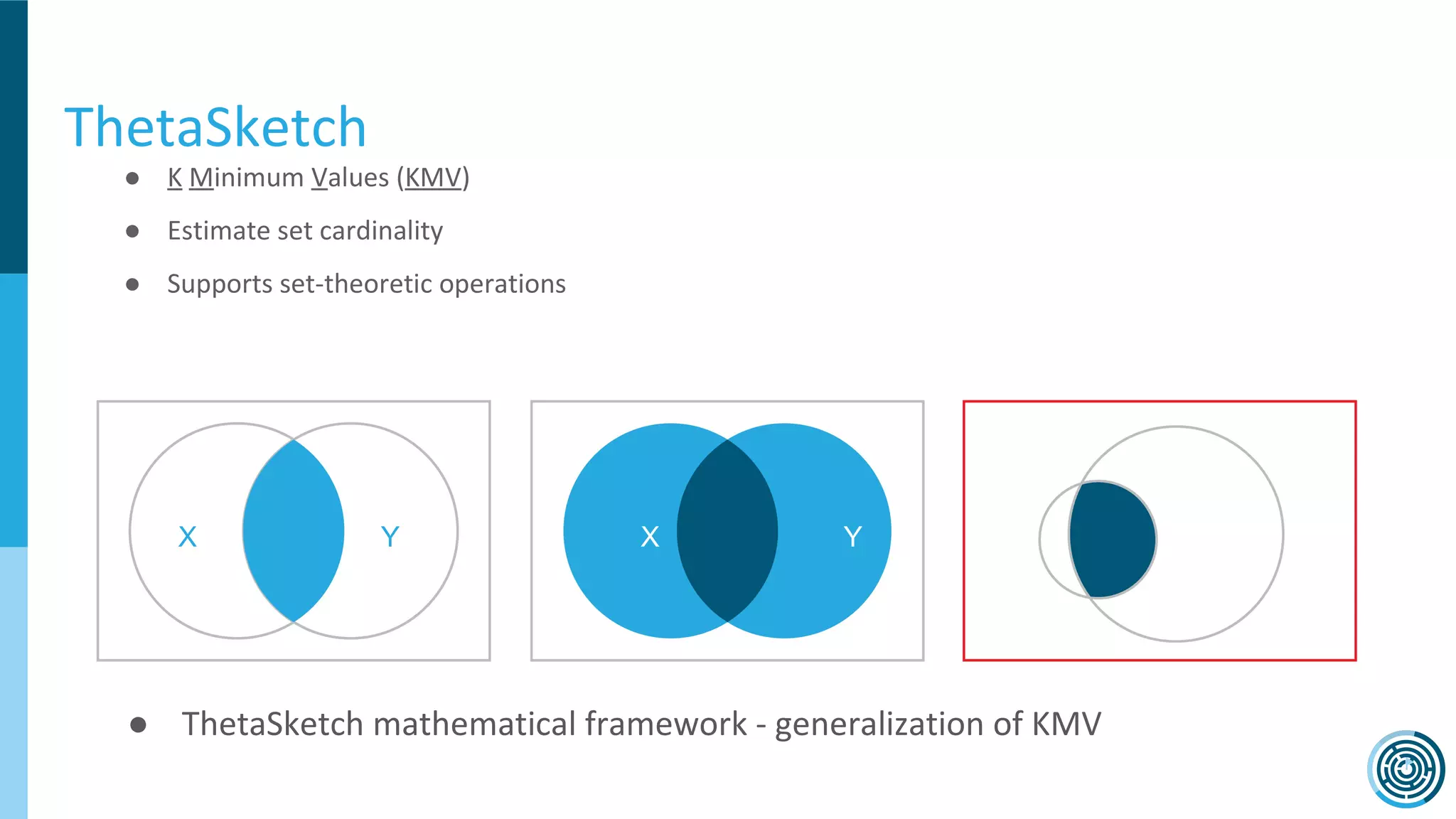
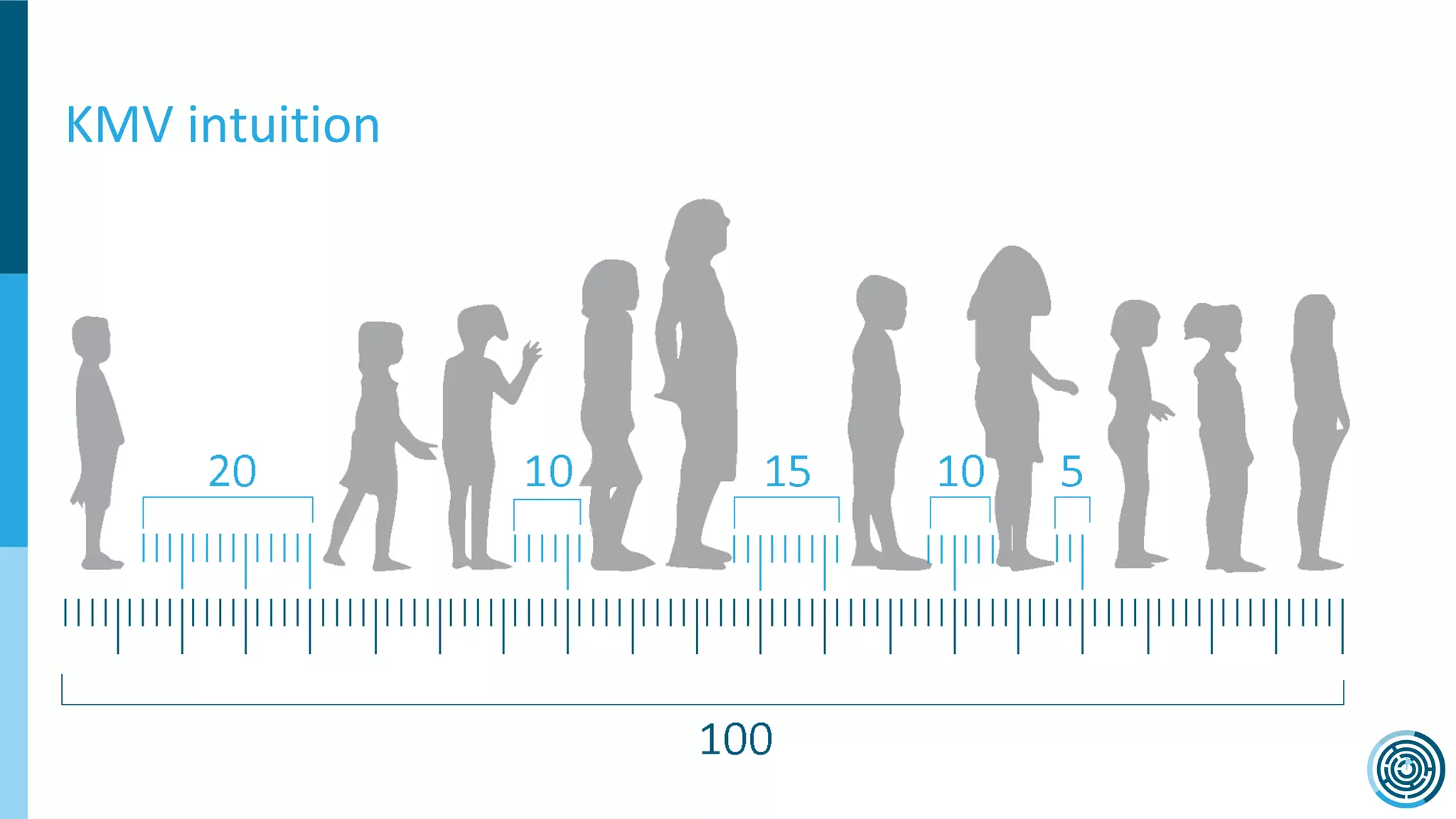
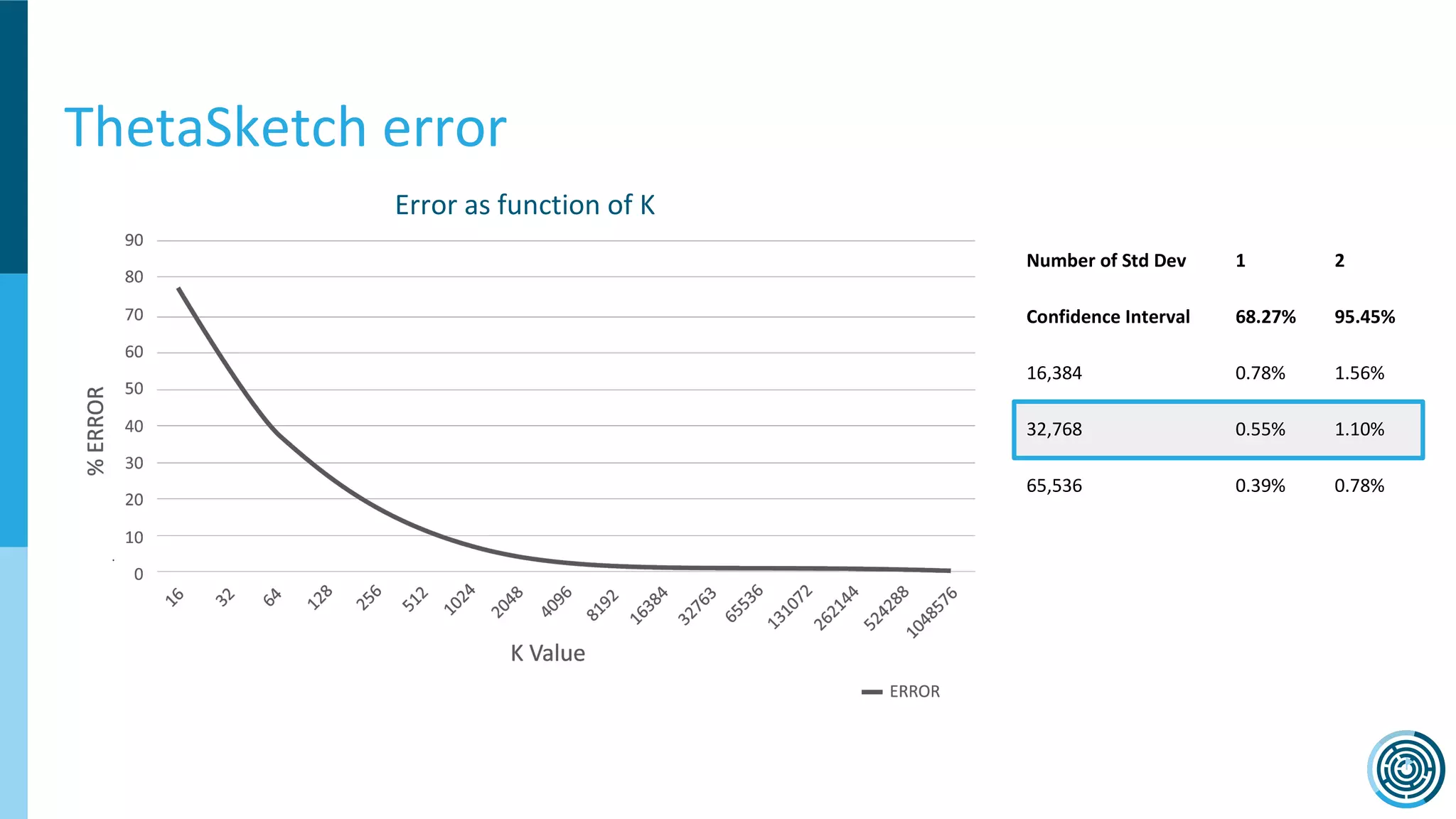



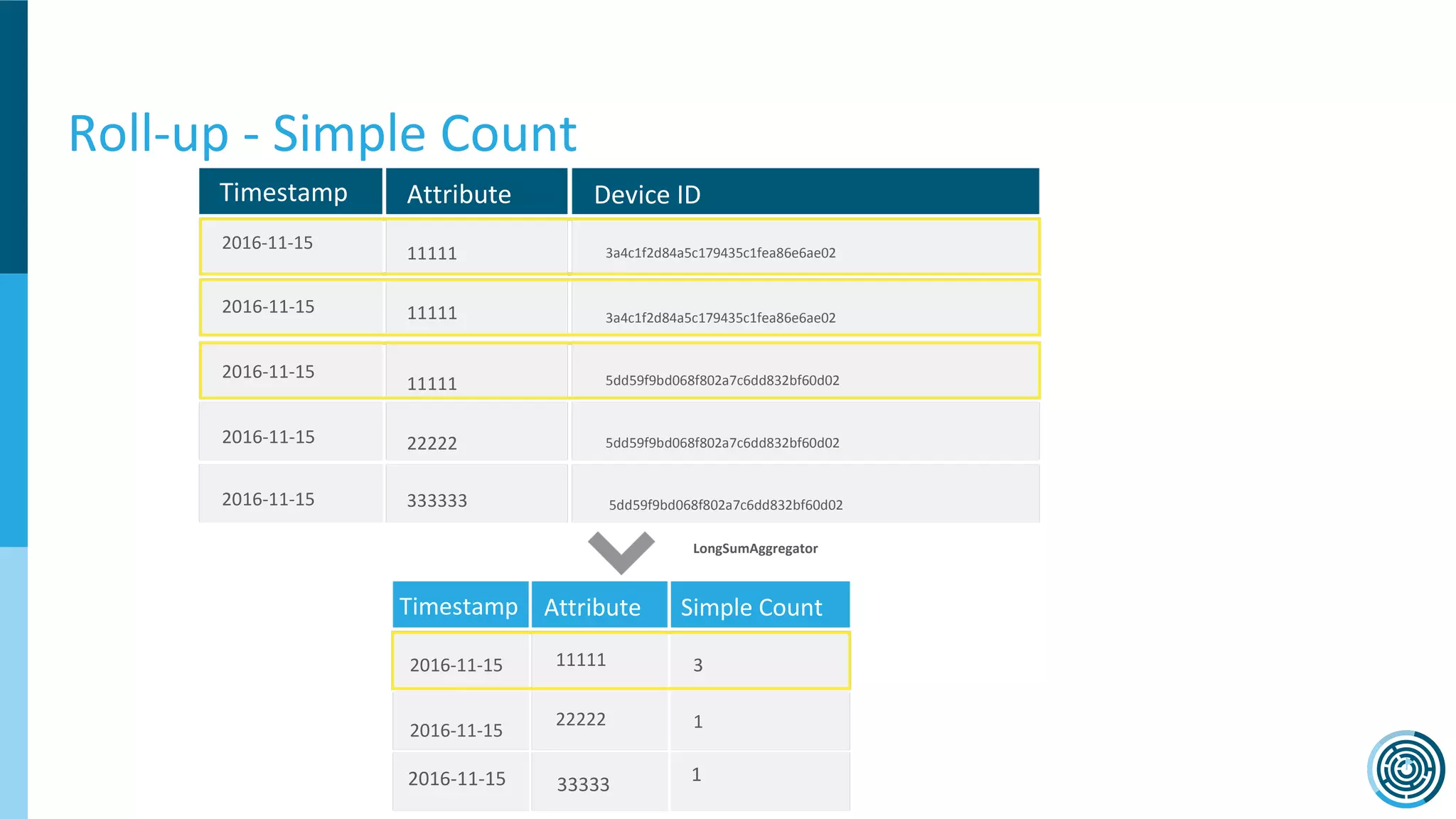
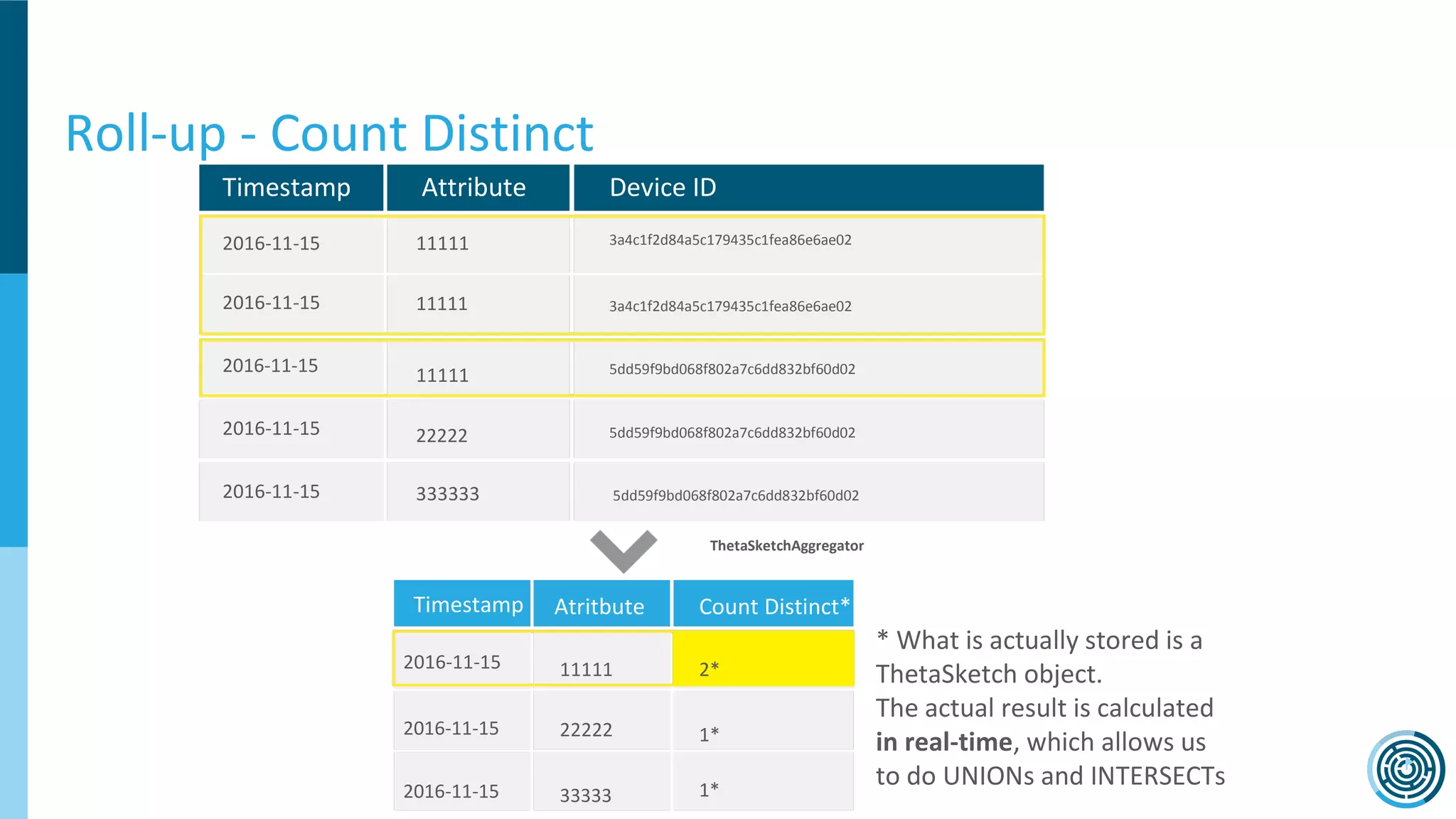
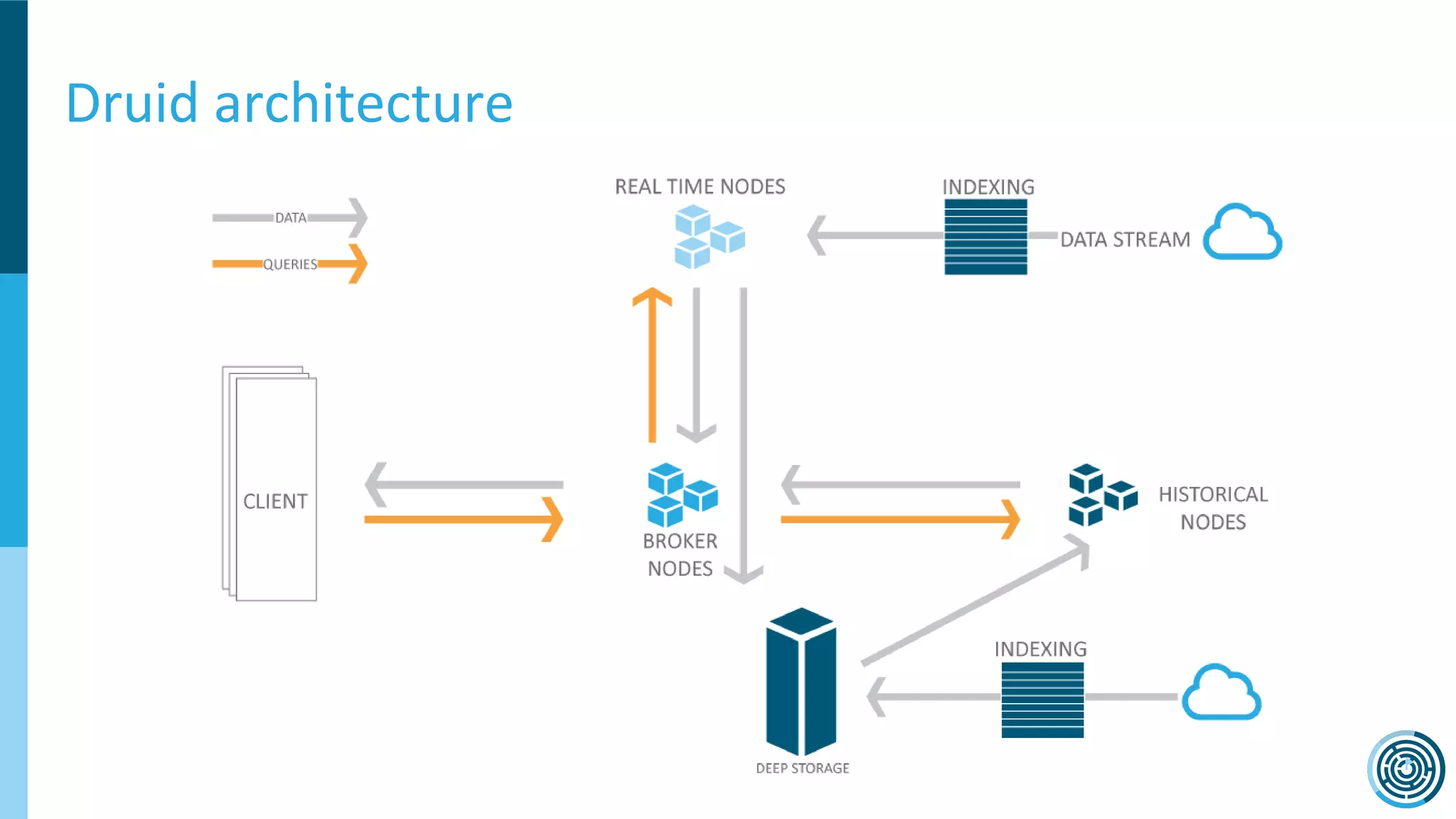
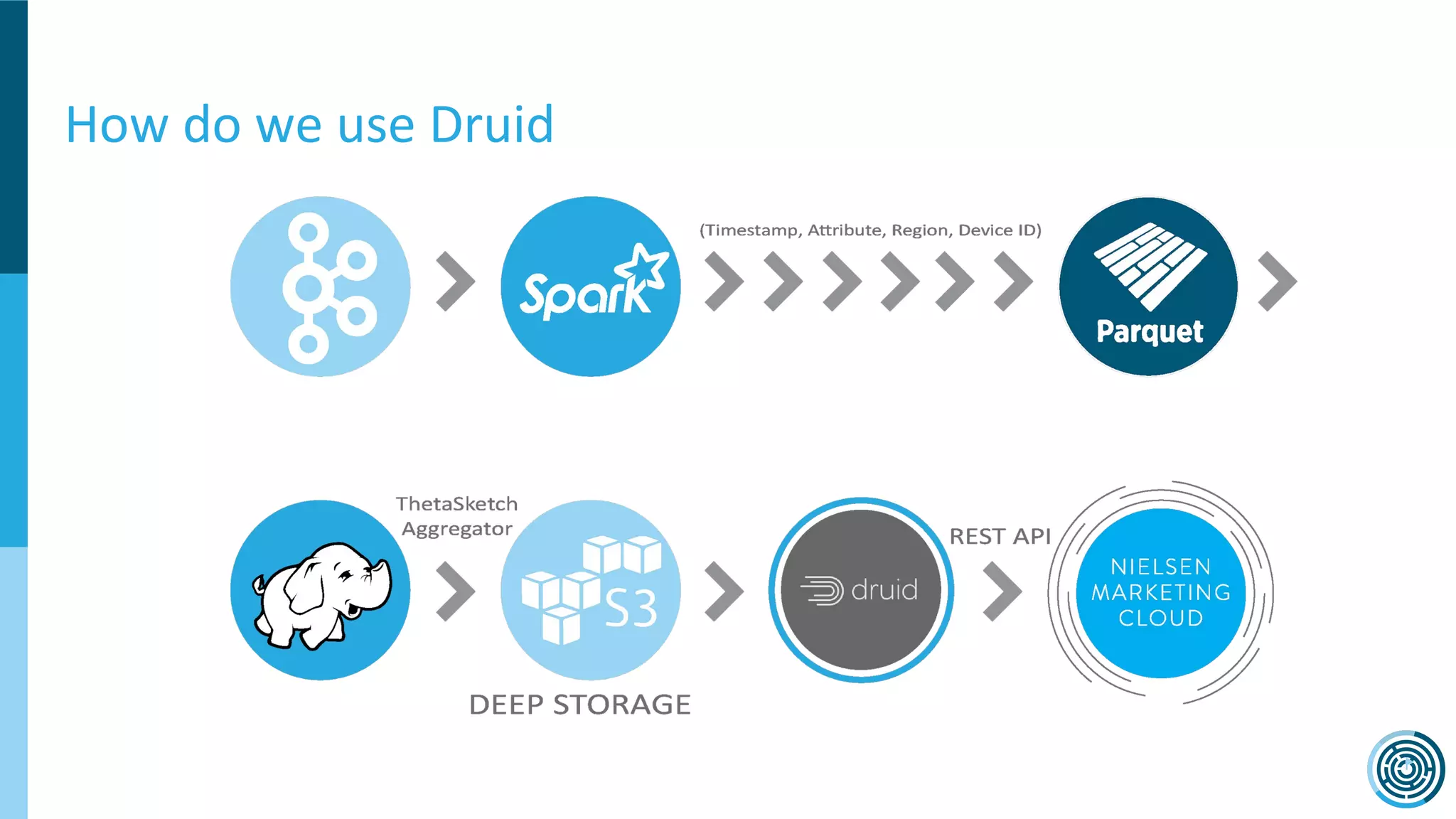
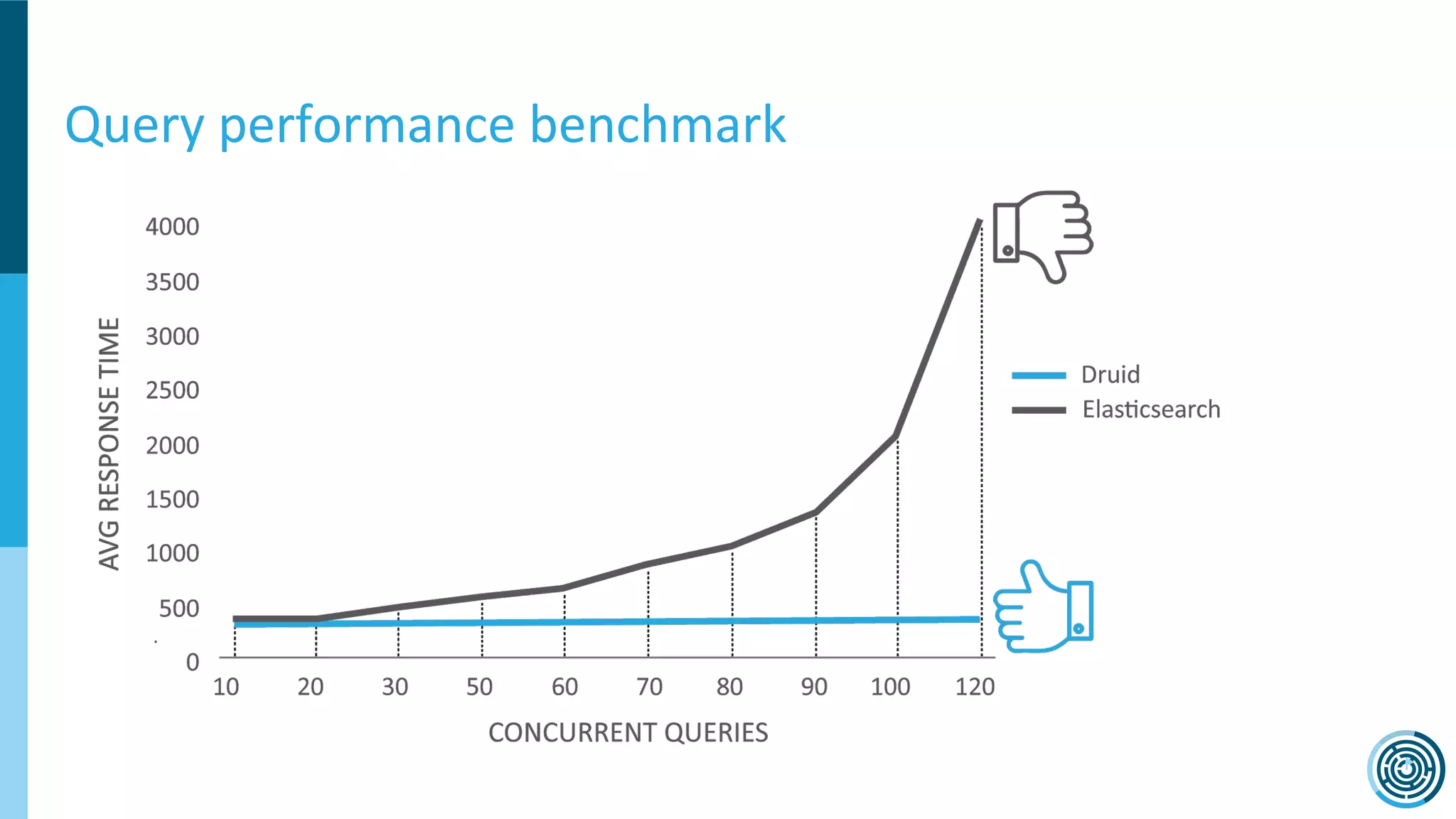

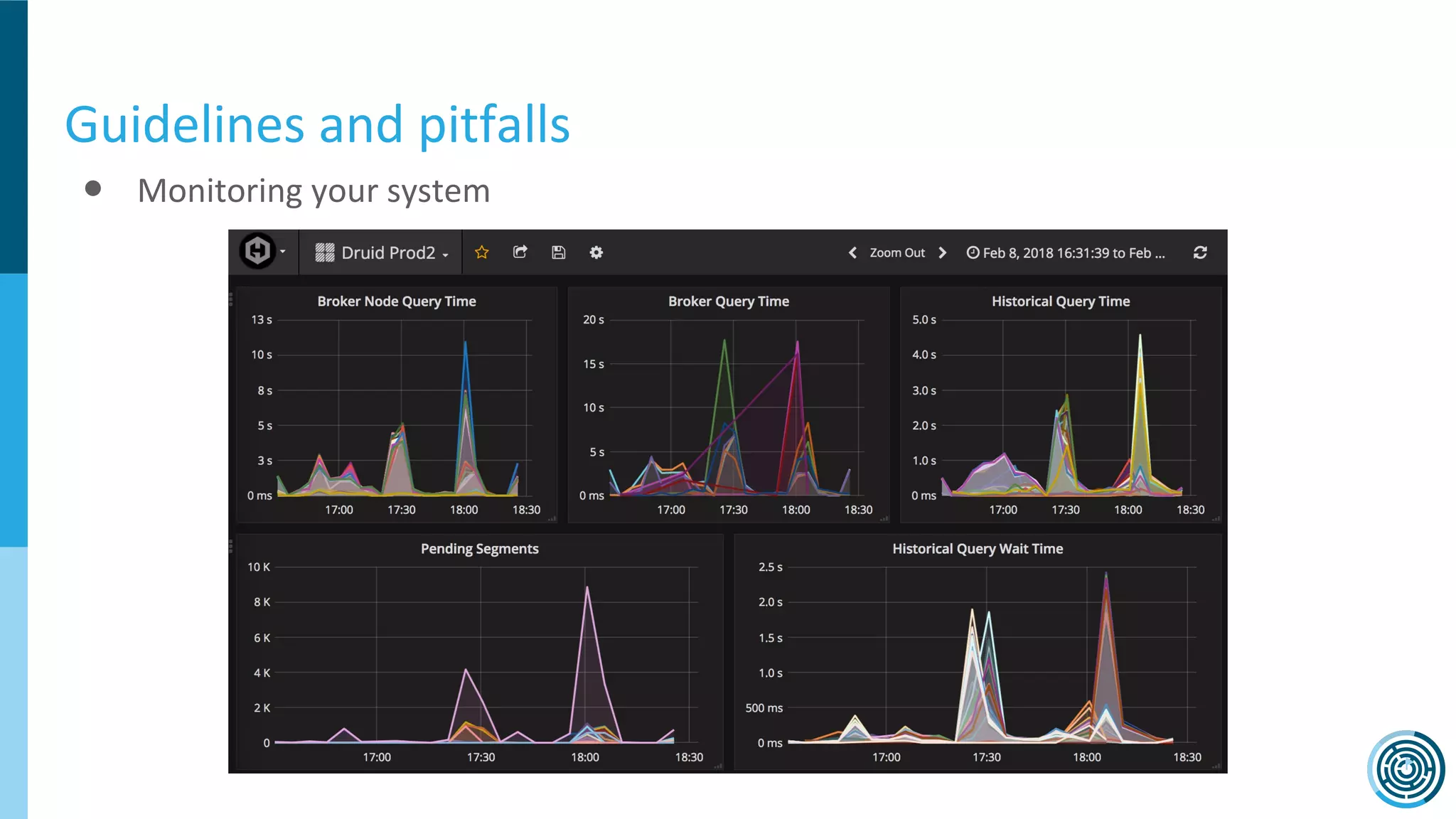




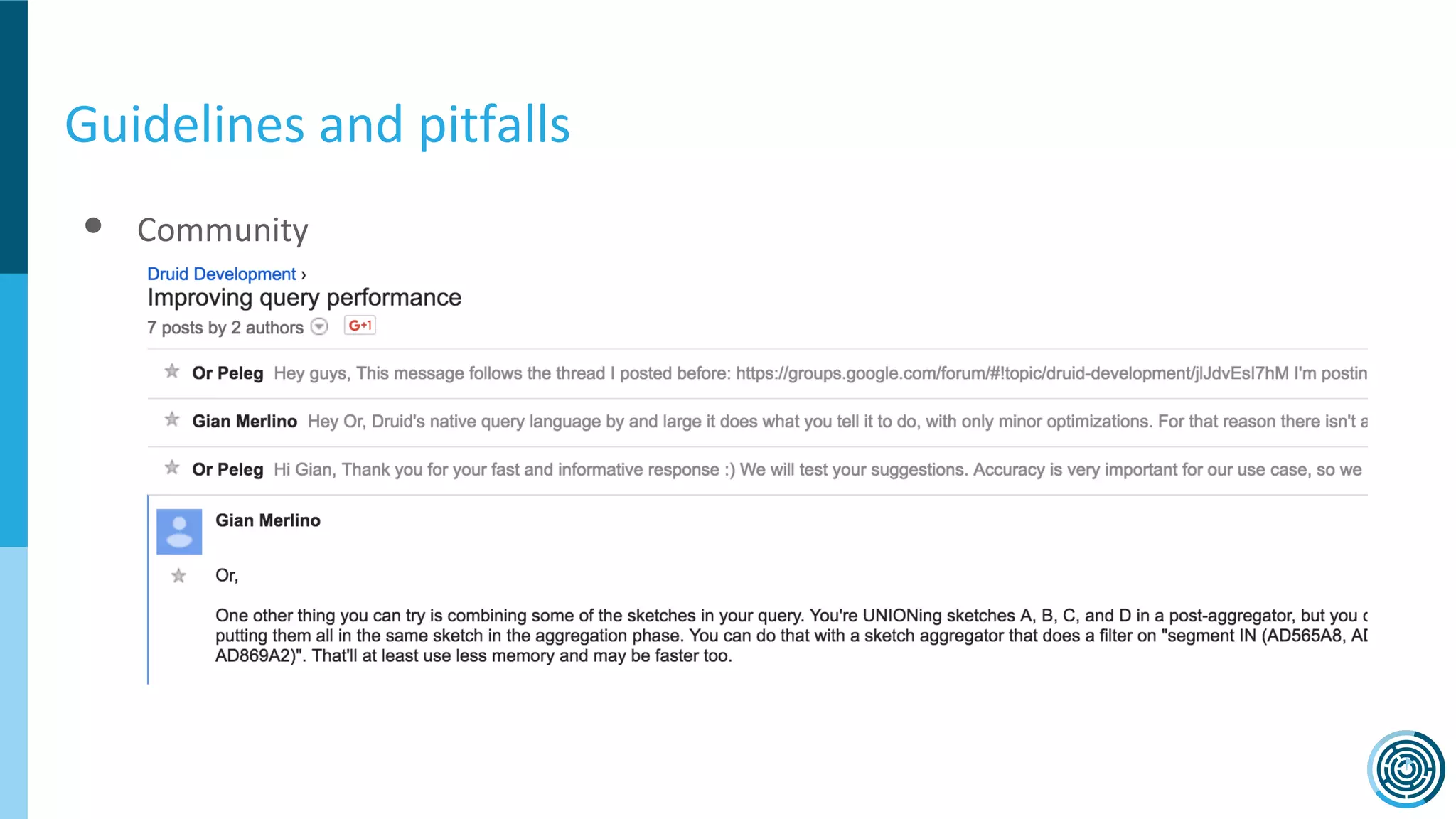





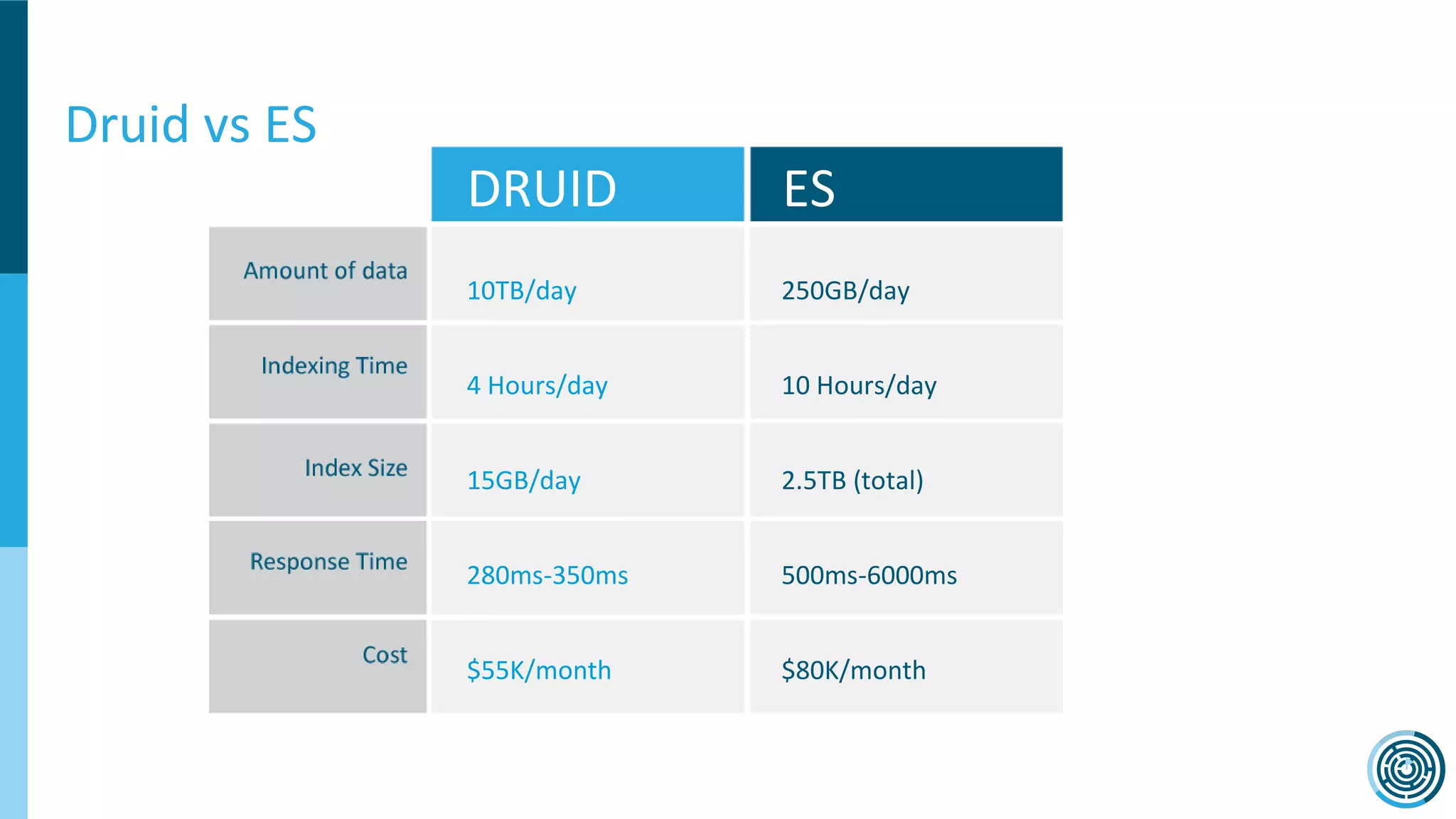

The document discusses the challenge of counting unique users in real-time using the Nielsen Marketing Cloud, with a focus on big data processing and machine learning solutions. It describes the various methods and frameworks, including theTasketch and Druid, for efficiently handling large datasets and real-time distinct count queries. The authors emphasize the importance of query performance optimization, data modeling, and community resources for achieving effective big data applications.
























![[네이버오픈소스세미나] Contribution, 전쟁의 서막 : Apache OpenWhisk 성능 개선 - 김동경](https://cdn.slidesharecdn.com/ss_thumbnails/apacheopenwhiskpublicfont-180905052401-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)






