Downloaded 122 times


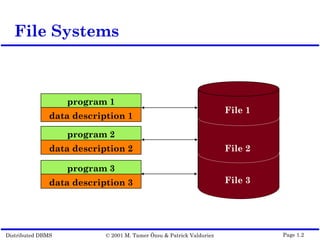
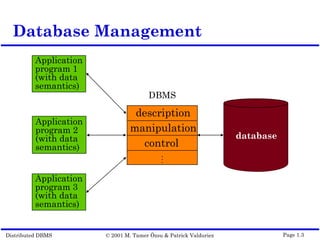
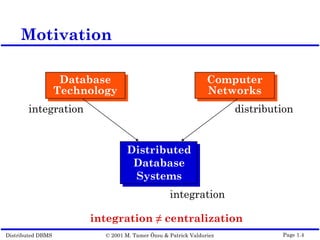





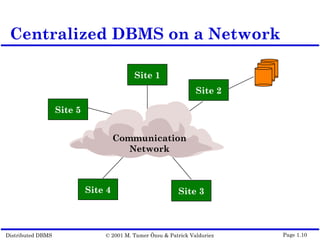
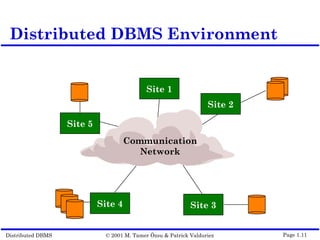

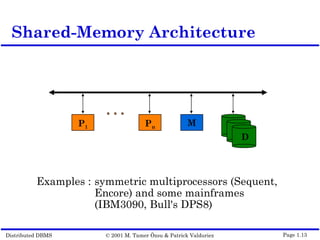
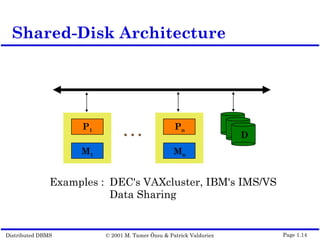
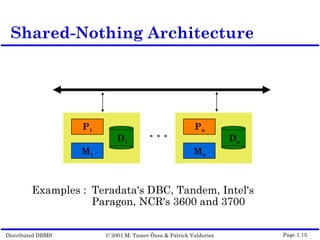








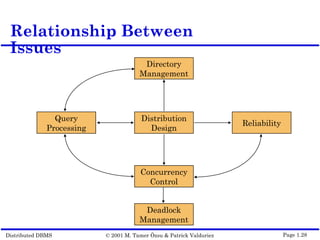


This document outlines the key topics covered in distributed database management systems (DDBMS). It introduces DDBMS and discusses their advantages over centralized systems, including improved performance, reliability, availability, and scalability. The document also summarizes major challenges in DDBMS, such as distributed database design, query processing, concurrency control, and reliability.



































































