Download as PDF, PPTX



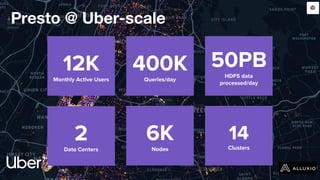
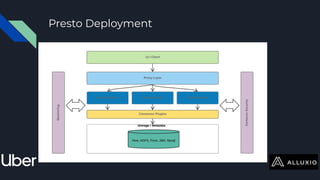


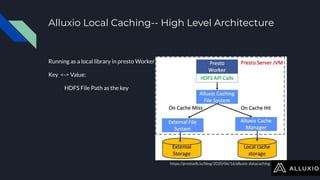
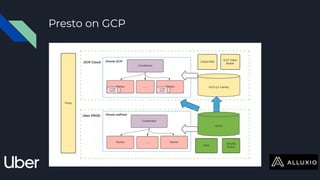

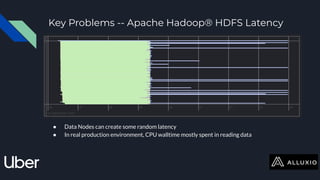
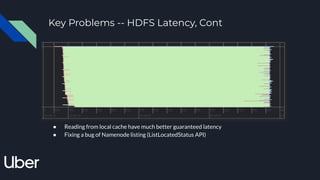

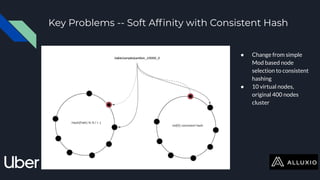



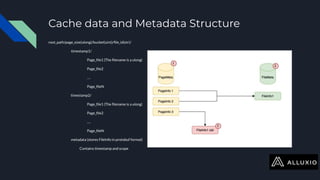
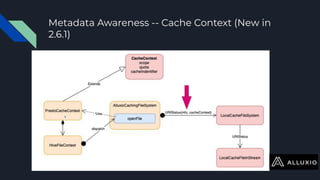
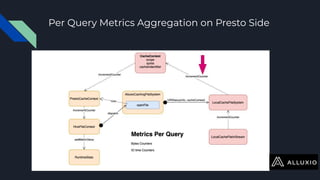


The document discusses enabling Presto caching at Uber using Alluxio, highlighting the architecture, data characteristics, and problems with HDFS latency. It details initial testing results, improvements in query performance, and outlines the implementation of a persistent file-level metadata store to manage cache and prevent stale caching. Future work includes performance tuning and enhancements for more efficient data handling.























































































