






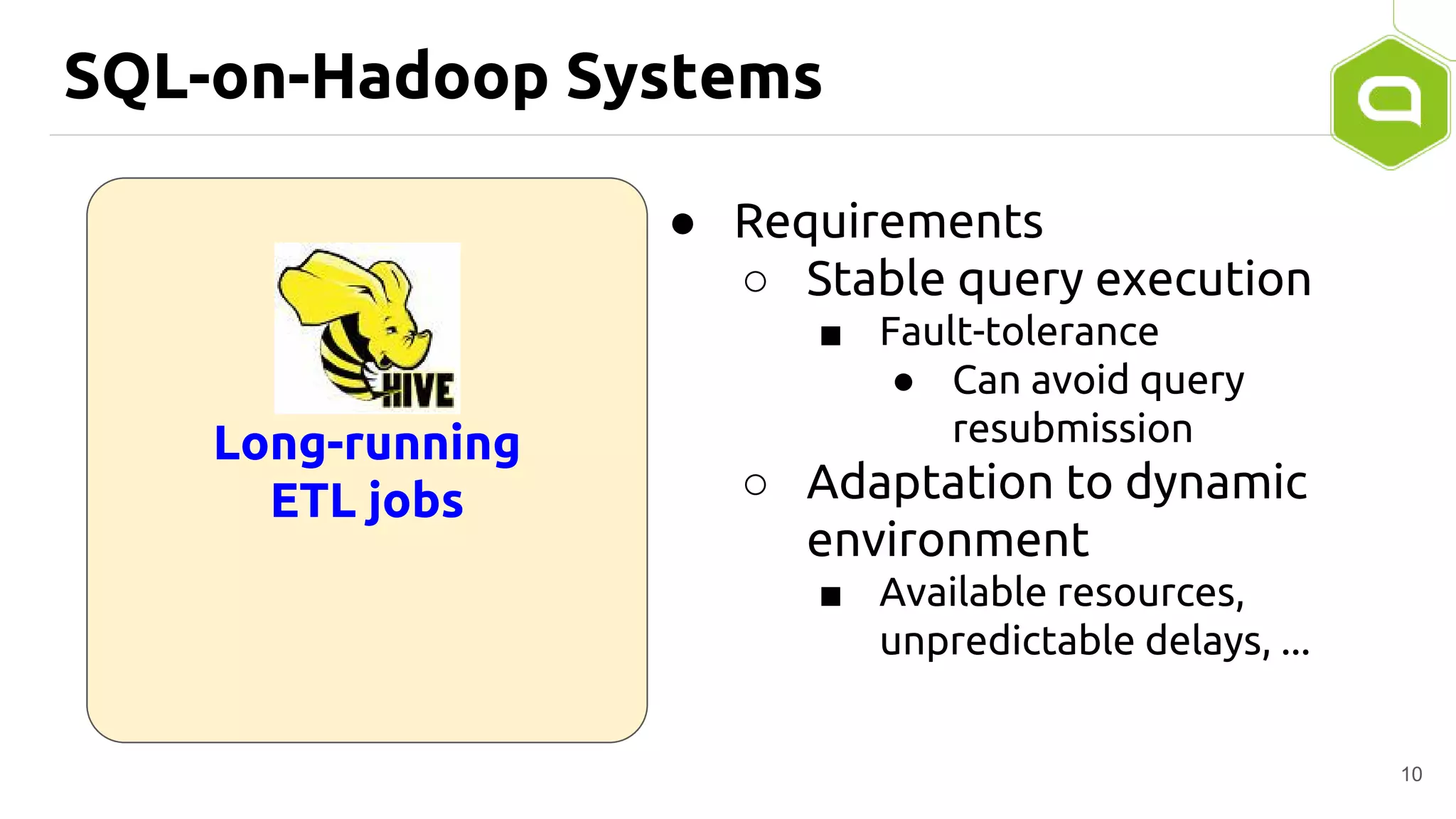
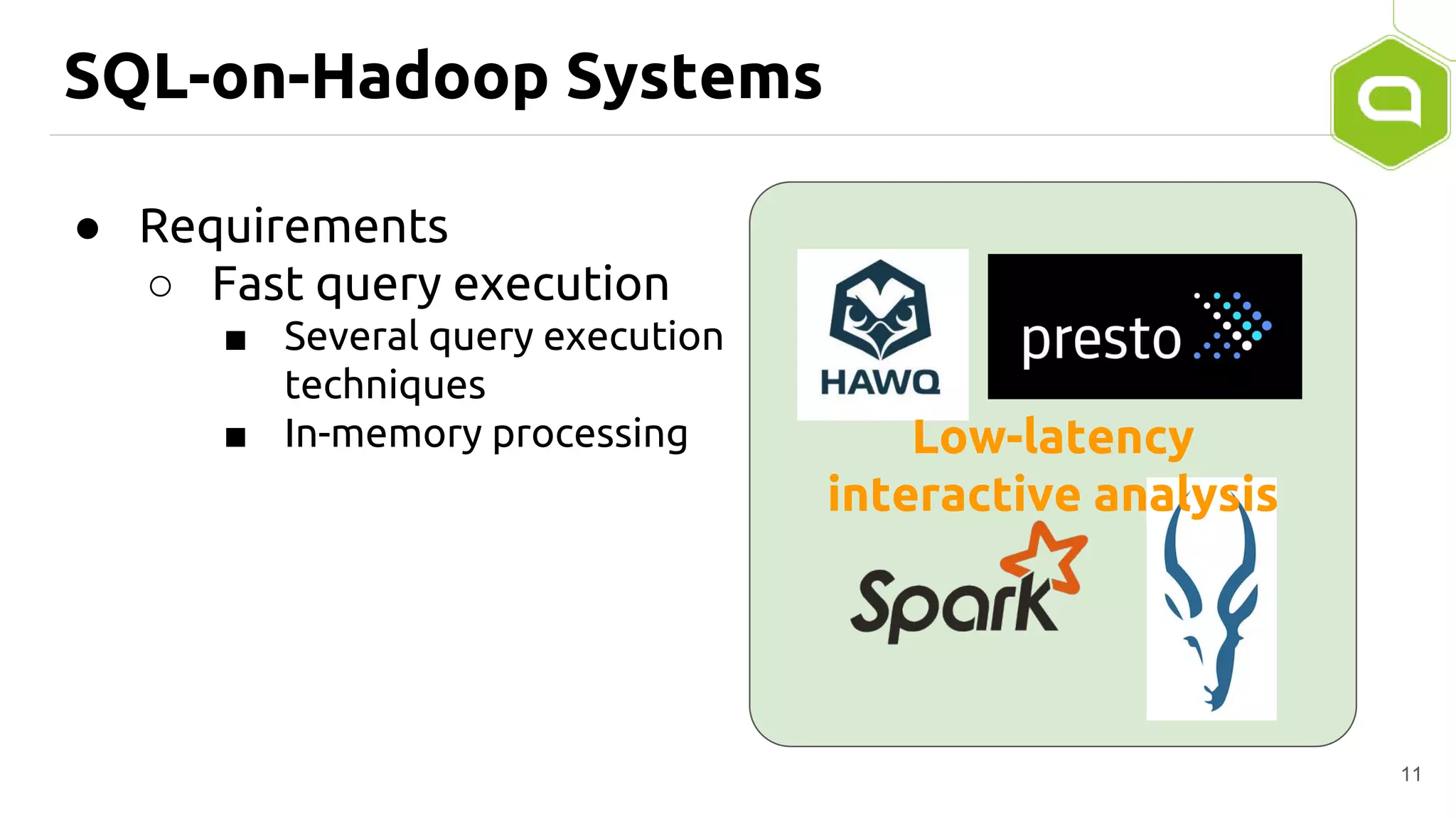
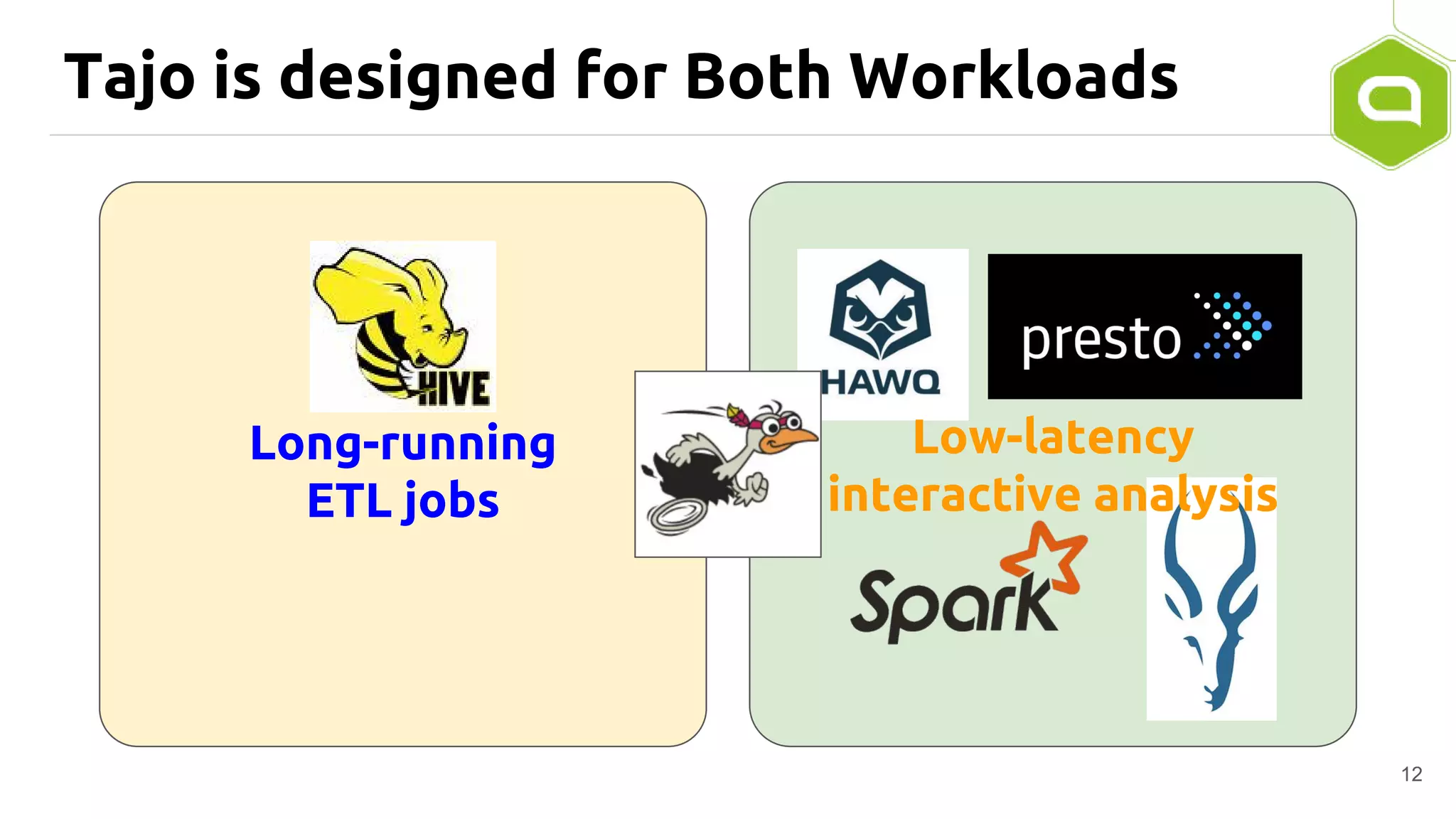


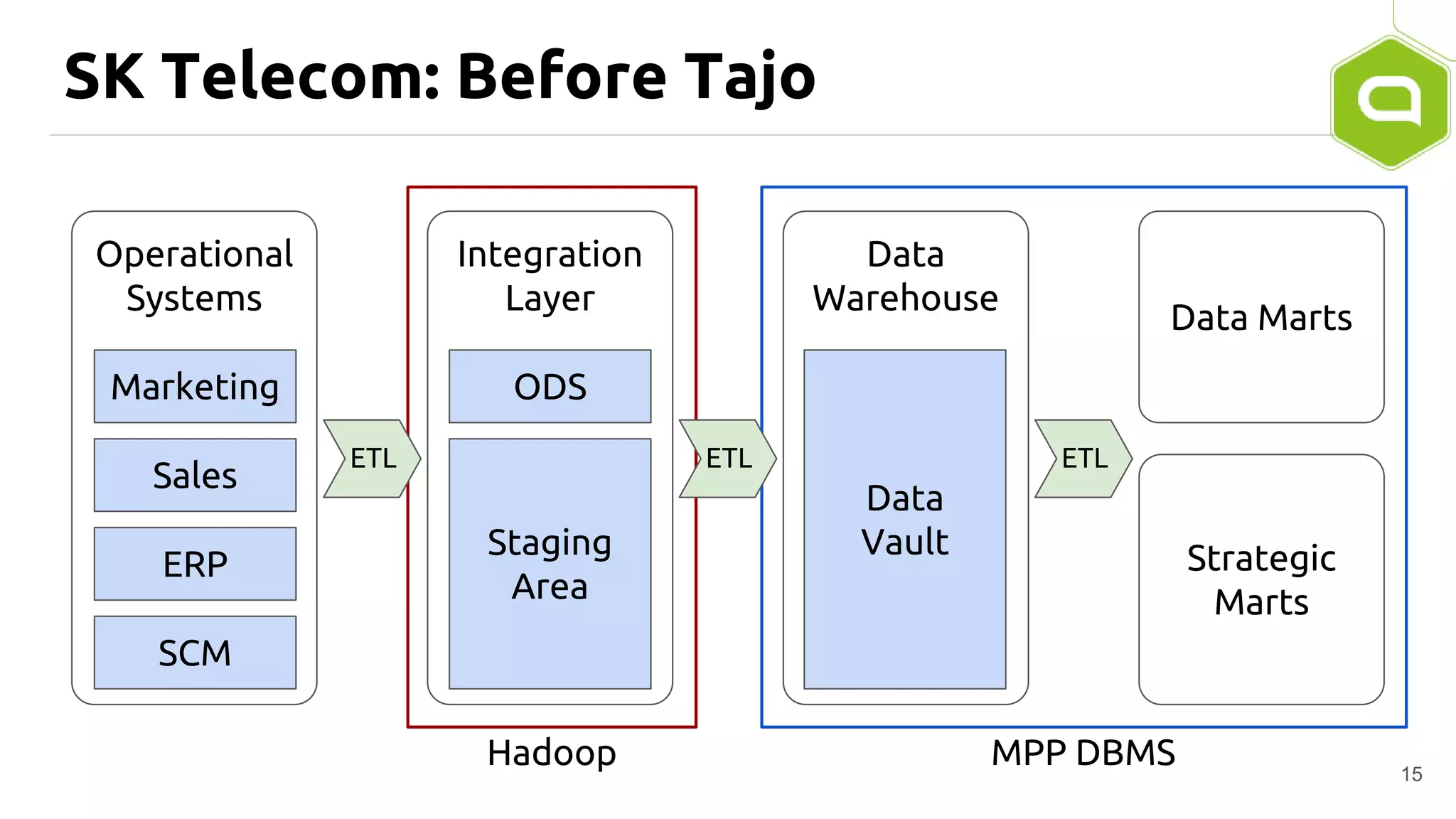
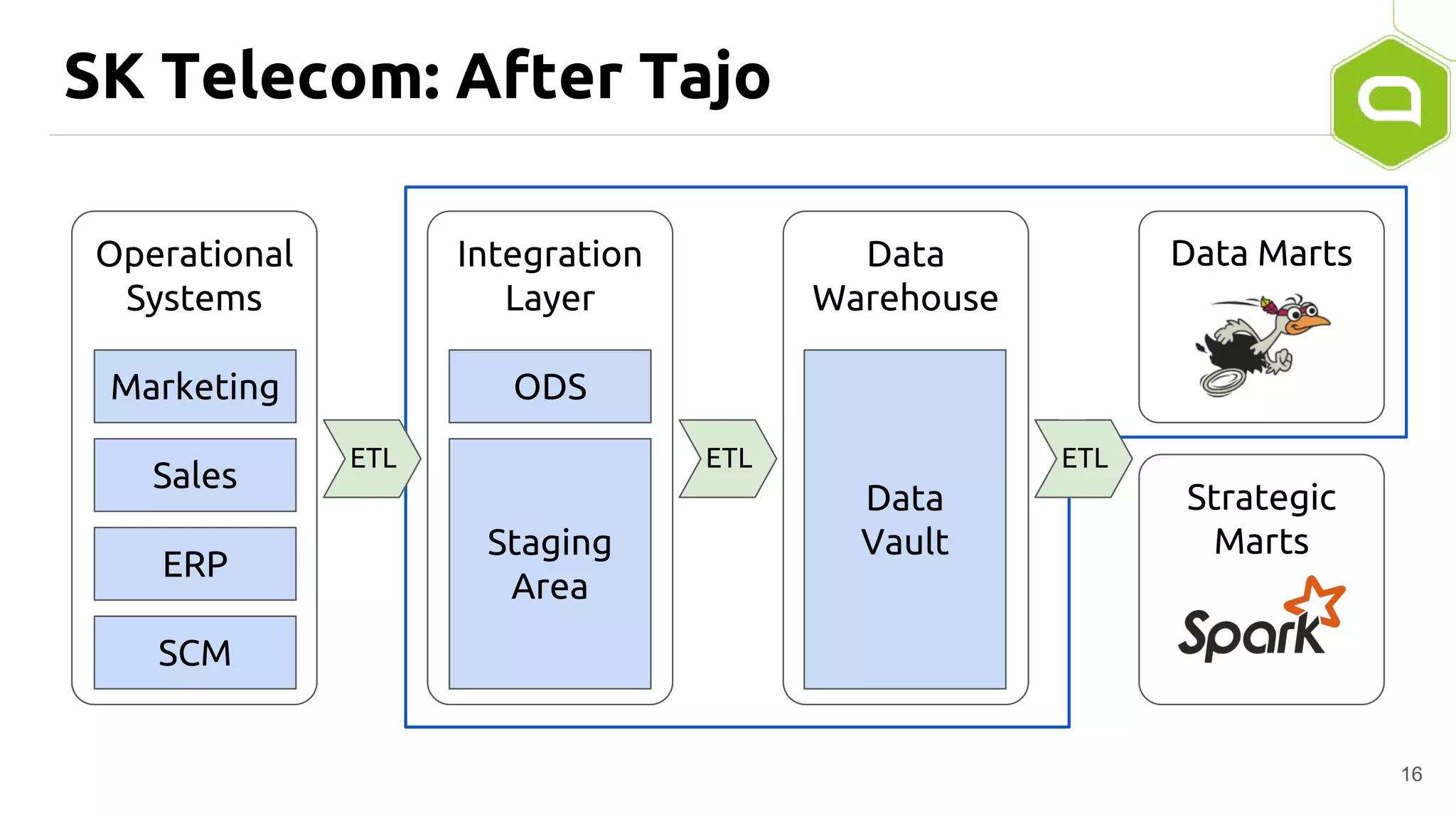
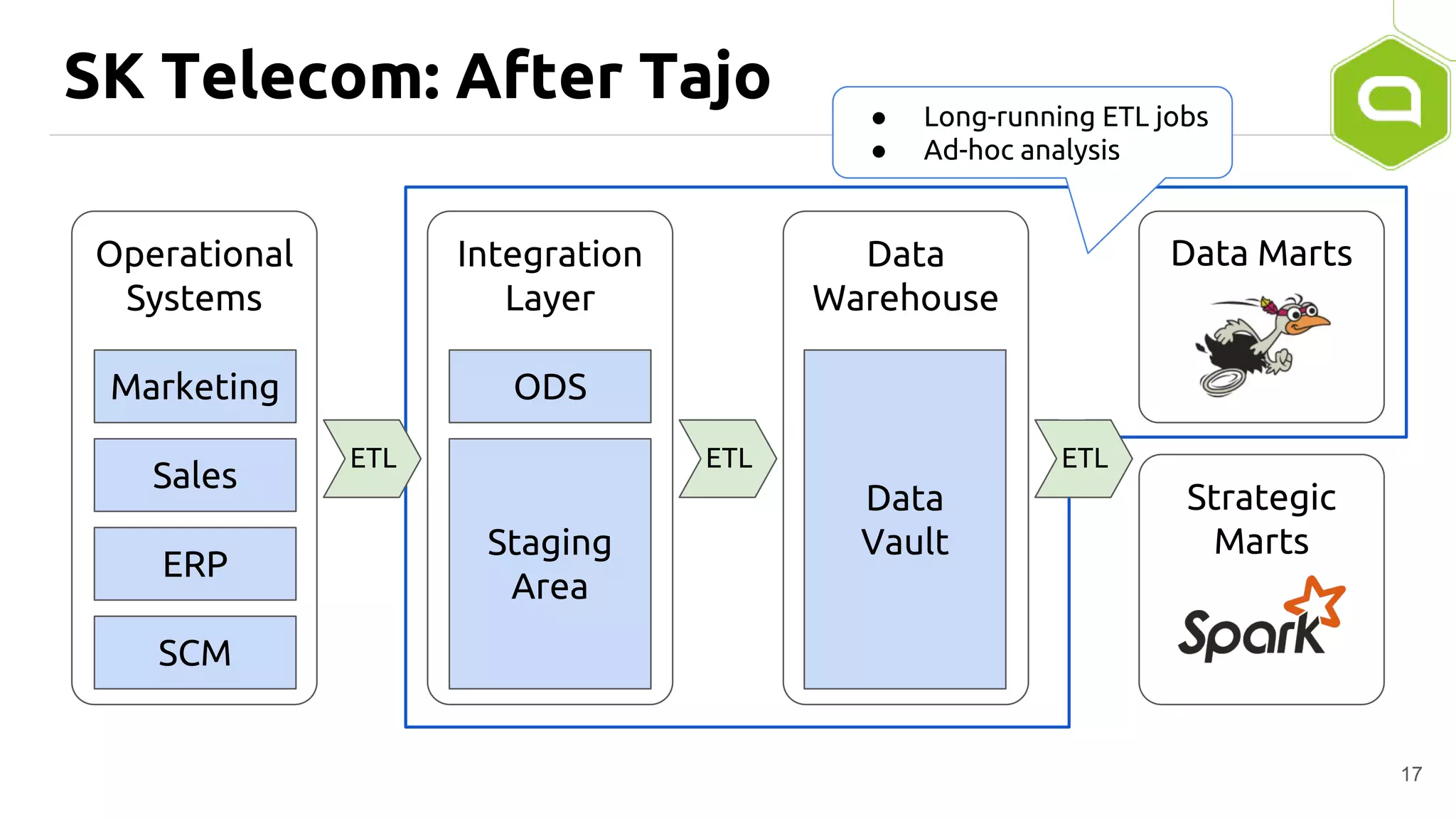


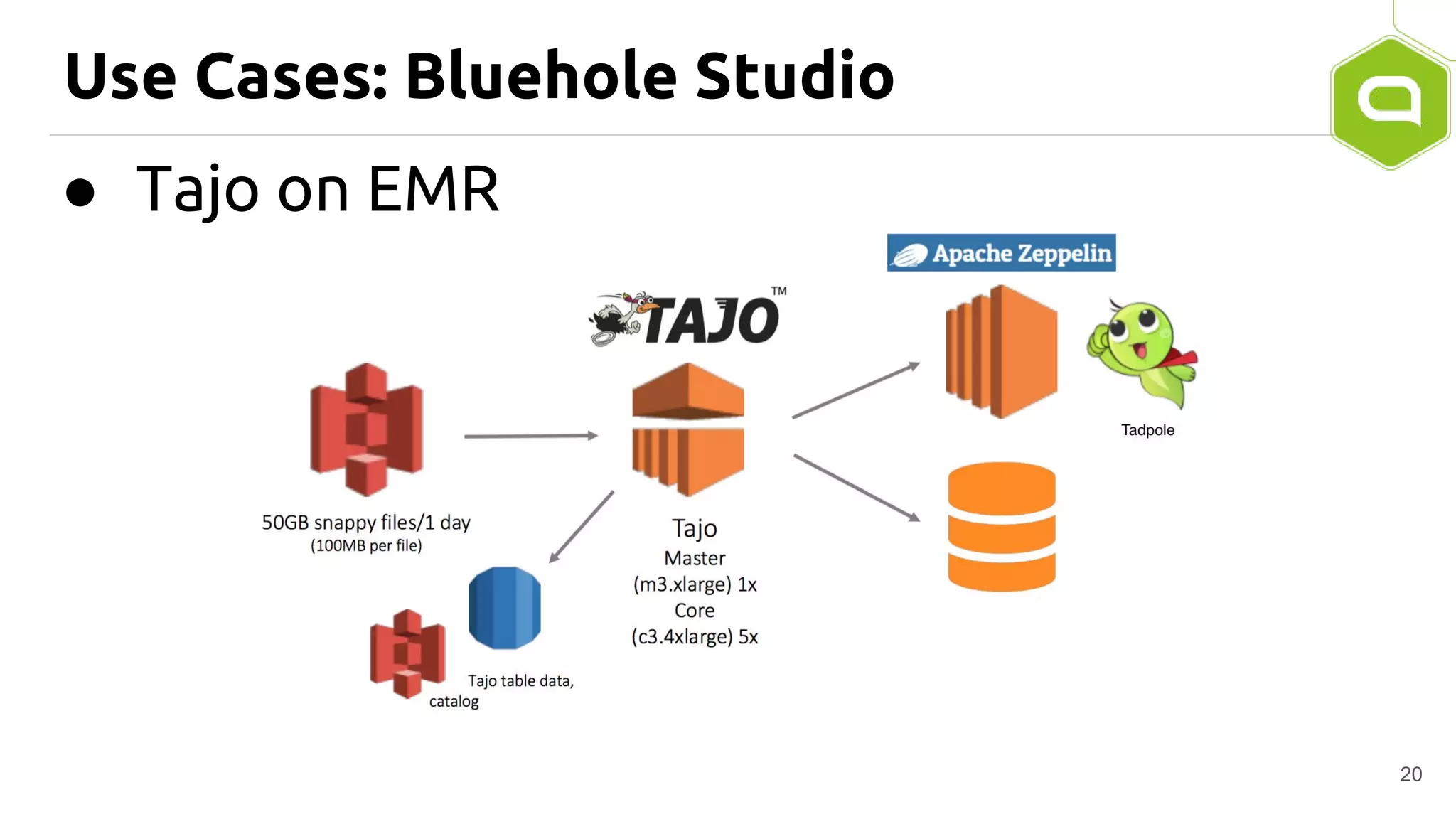













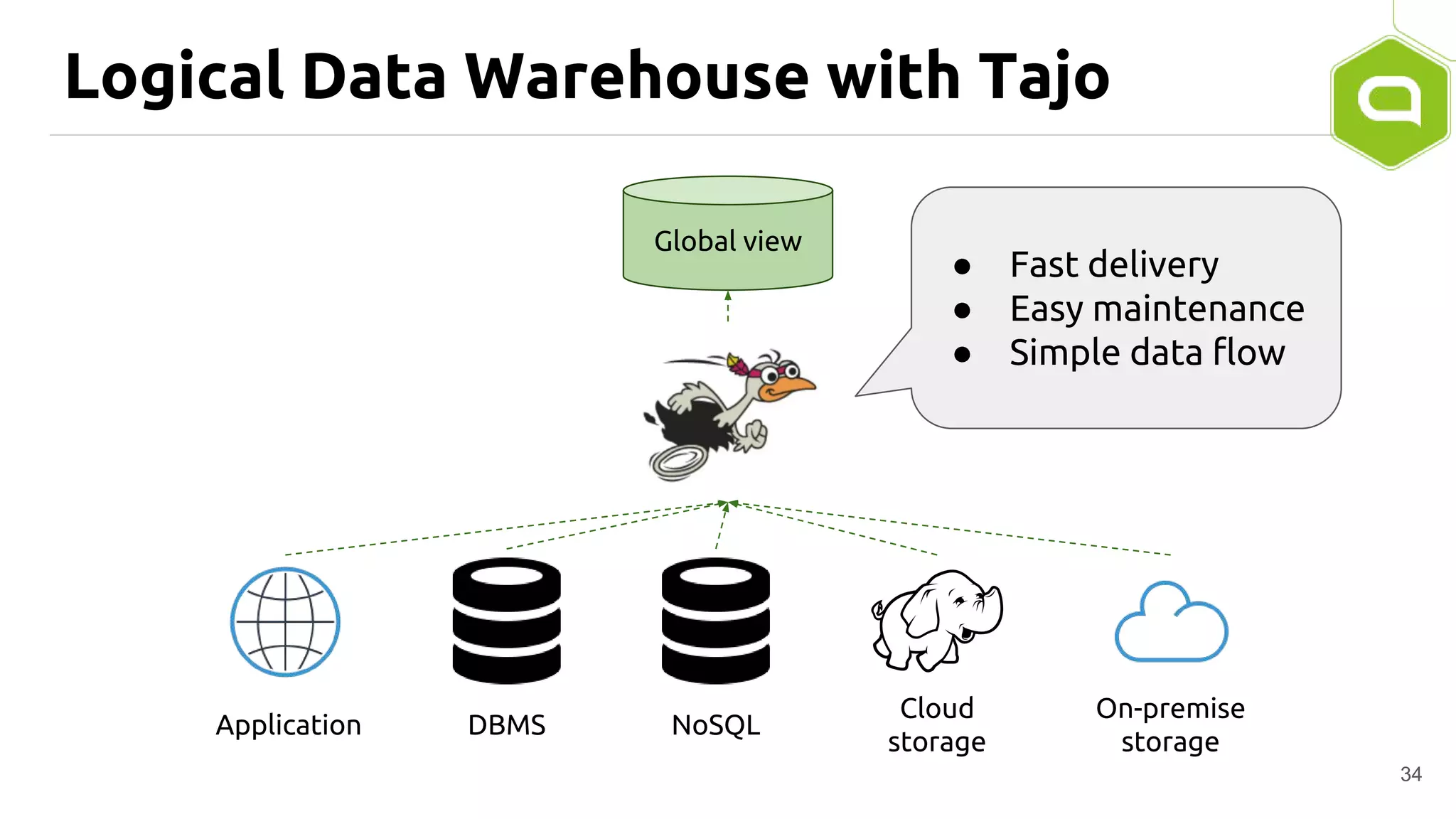





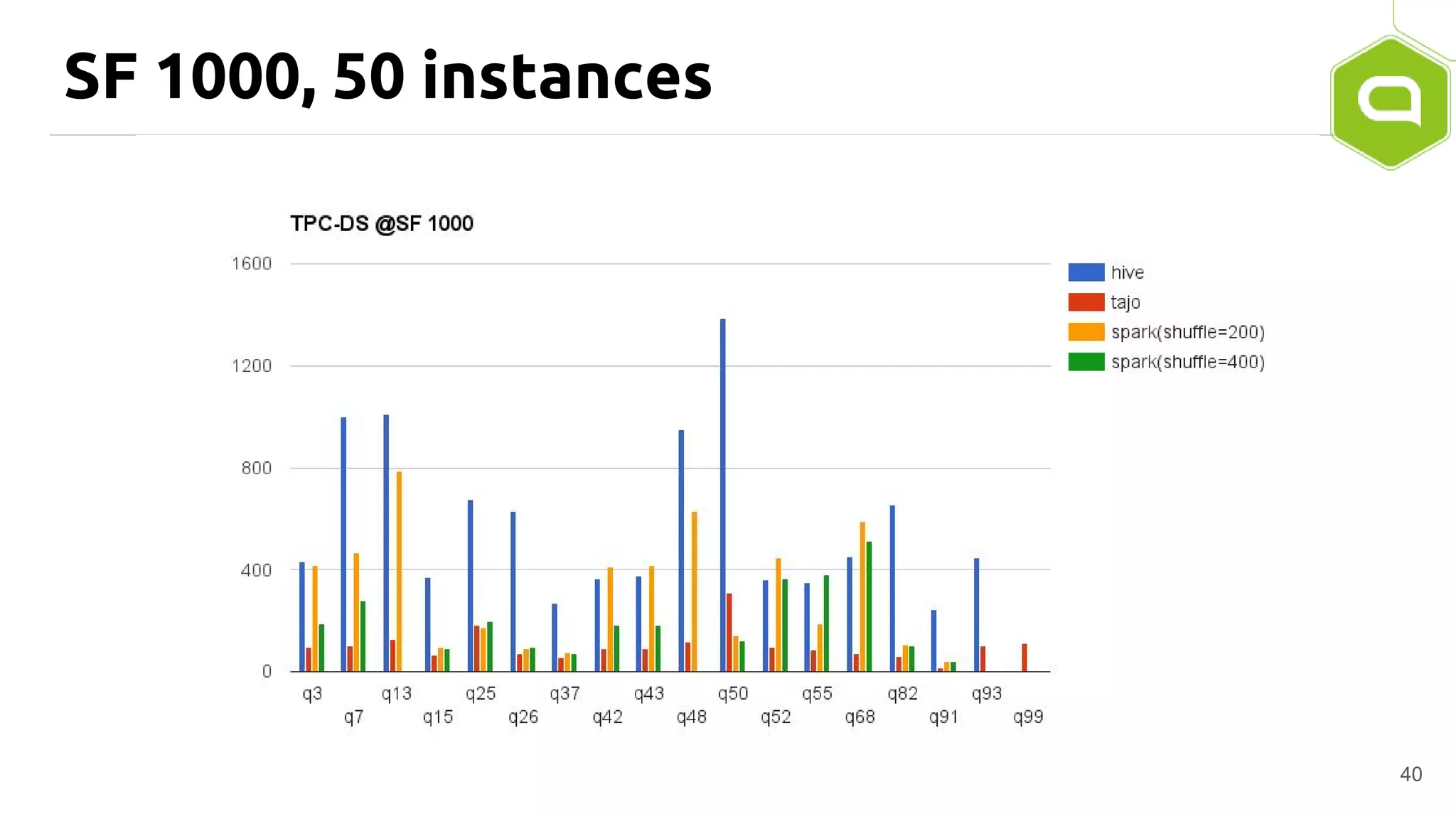
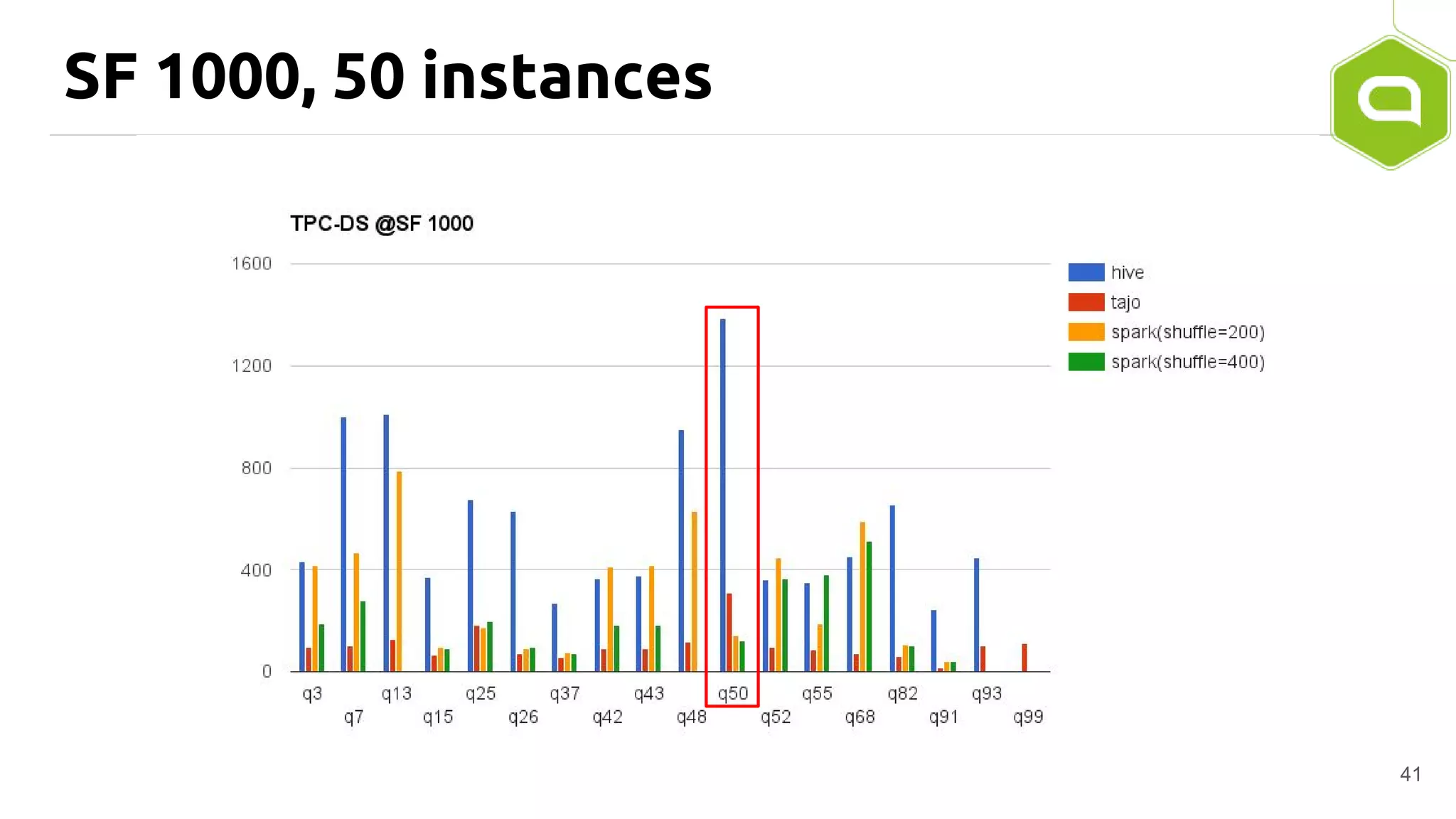
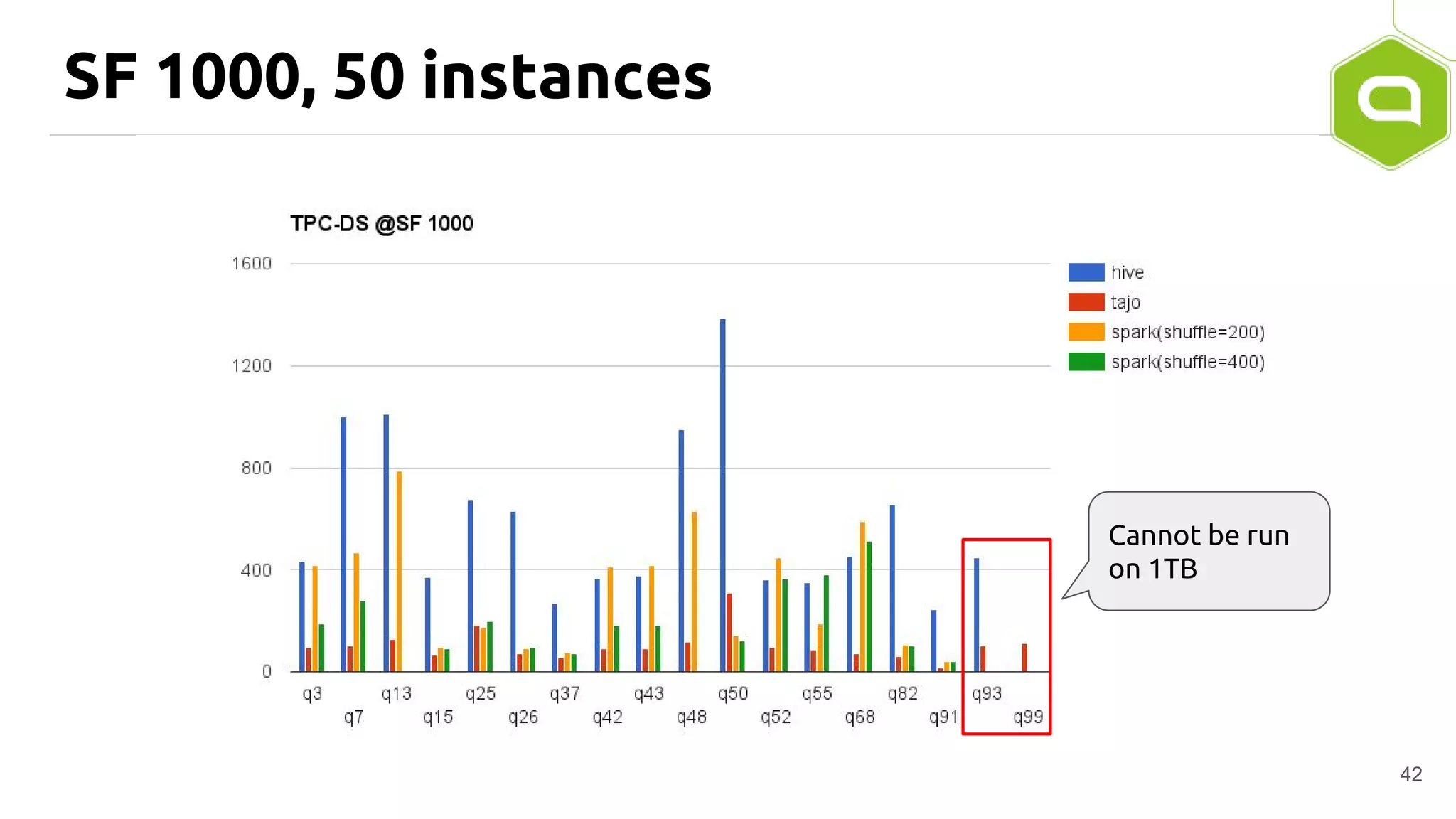
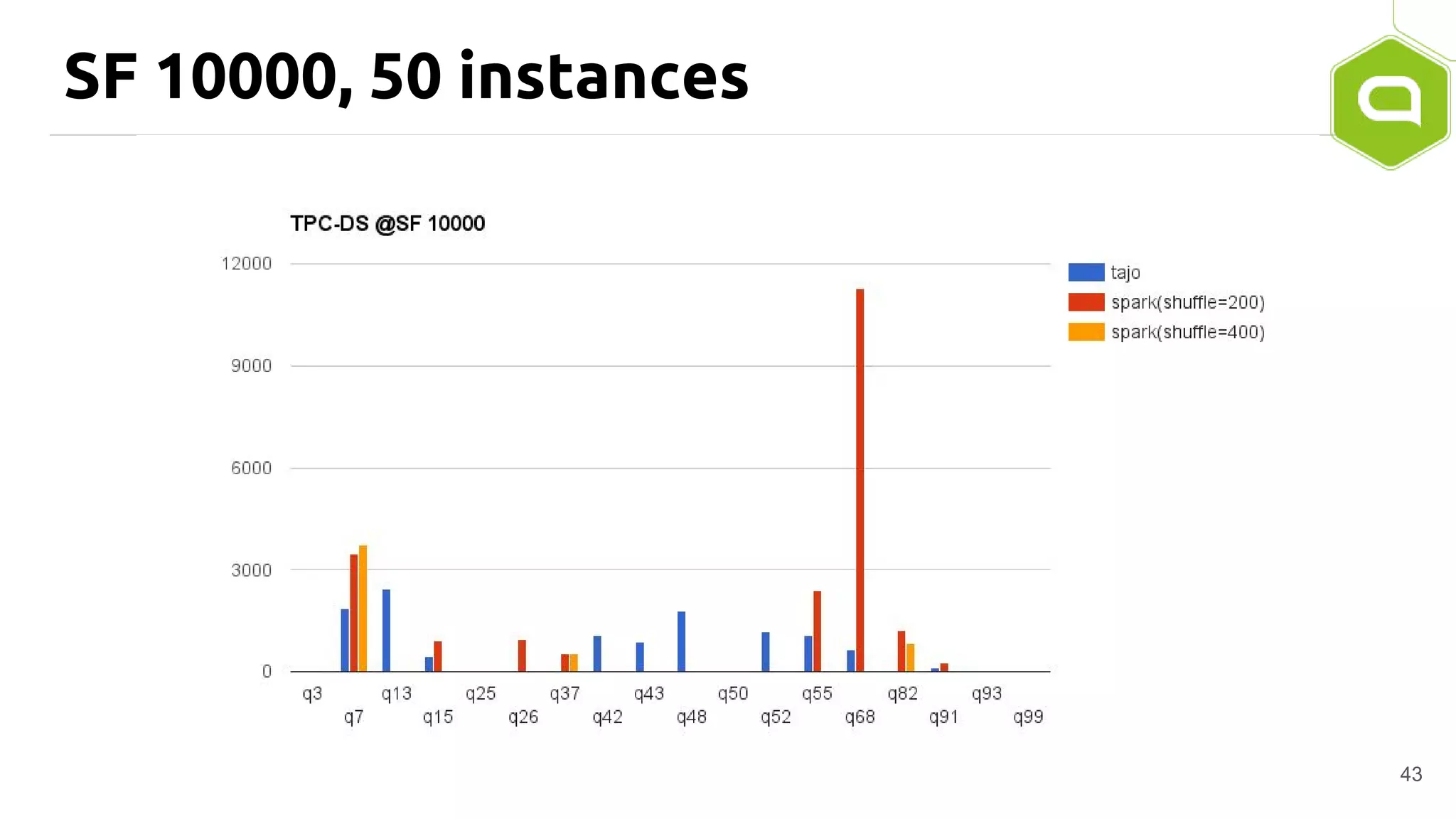
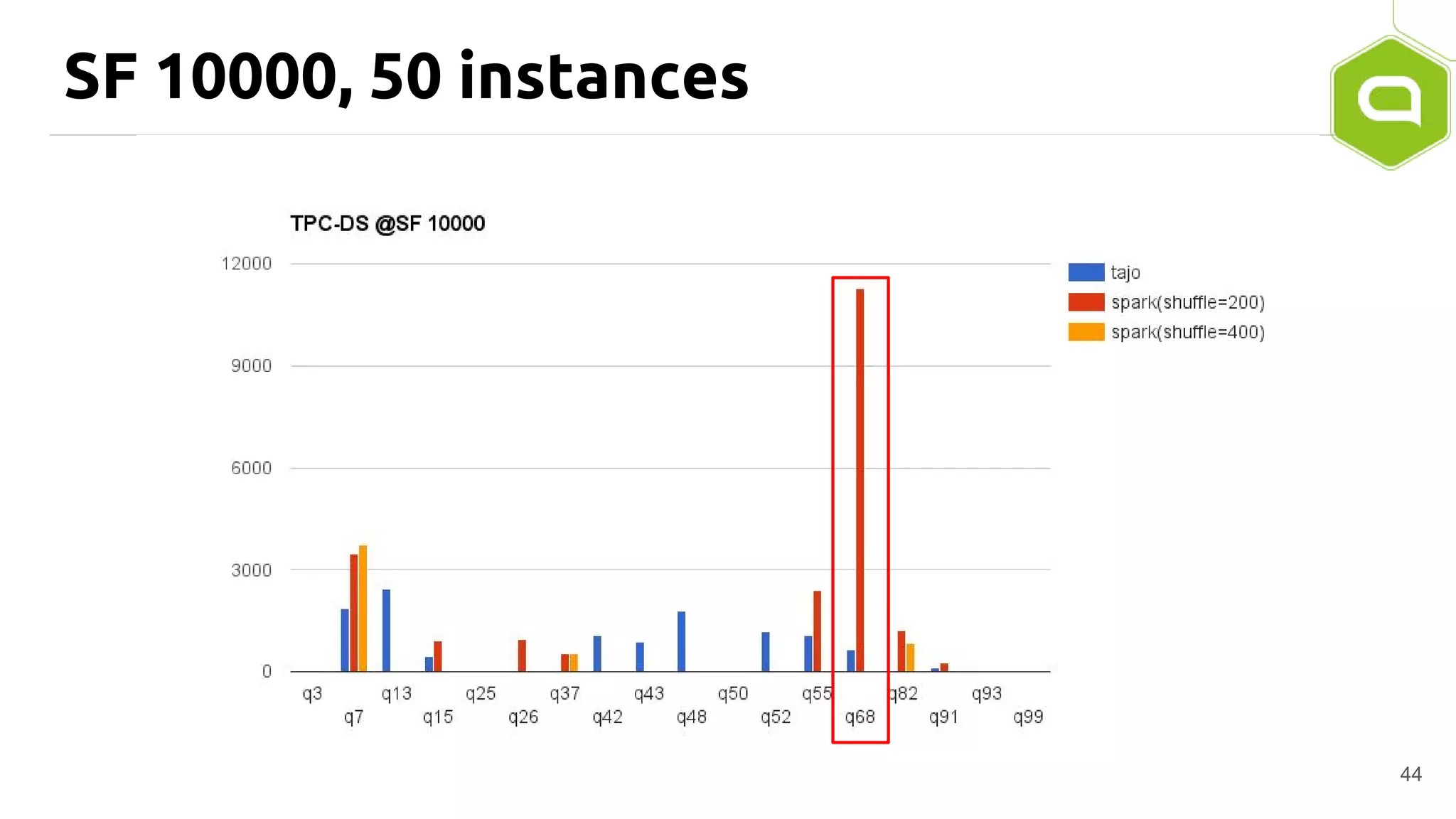



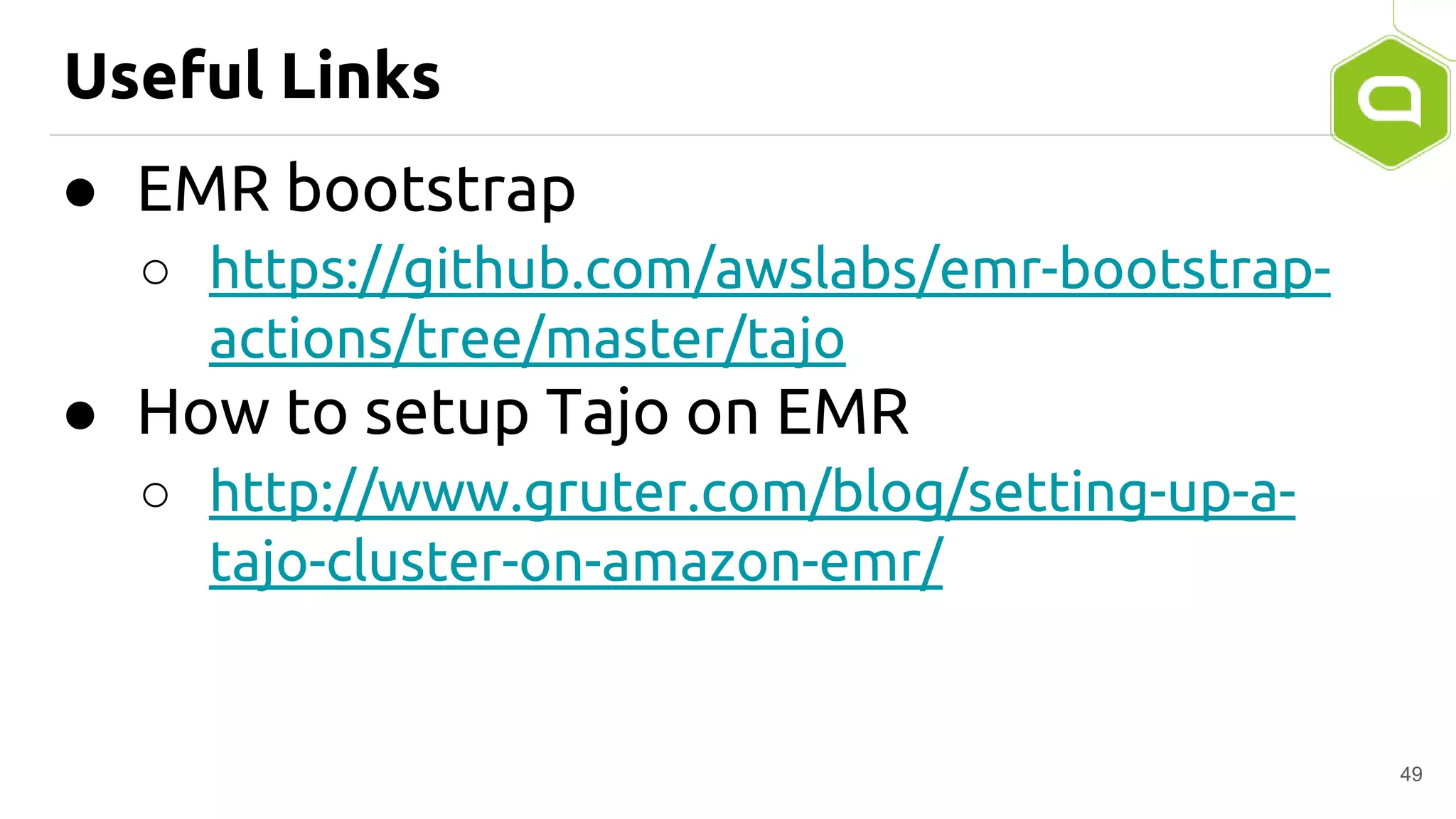


Apache Tajo is an SQL-on-Hadoop system designed for efficient data processing, specializing in both long-running ETL jobs and low-latency interactive analysis. It supports ANSI-SQL standard compliance and various data formats, offering optimized performance and query plan optimization. Tajo has use cases in significant organizations like SK Telecom and Bluehole Studio, demonstrating its effectiveness in reducing analysis time and facilitating data-driven decisions.









![[db tech showcase Tokyo 2017] C23: Lessons from SQLite4 by SQLite.org - Richa...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-sqlite4-20170906-170911071410-thumbnail.jpg?width=640&height=640&fit=bounds)











































![[FOSS4G 2015 SEOUL] Spatial tajo supporting spatial queries on Apache Tajo](https://cdn.slidesharecdn.com/ss_thumbnails/spatialtajo-supportingspatialqueriesonapachetajoenglish-final-150914191111-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)










