Download as PDF, PPTX




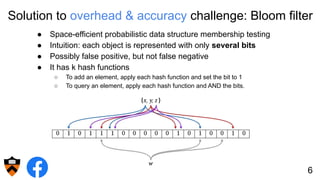


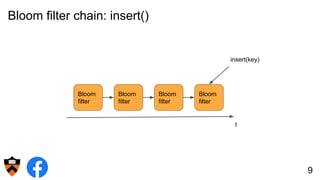
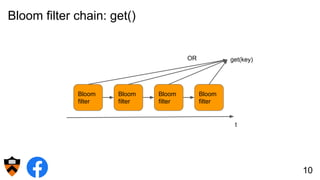
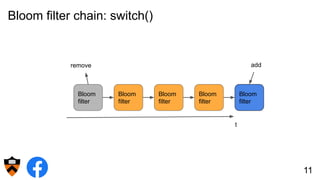
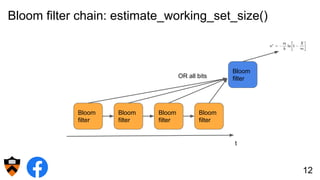
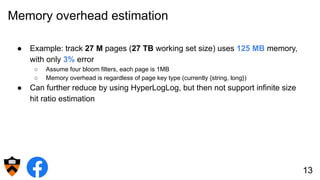




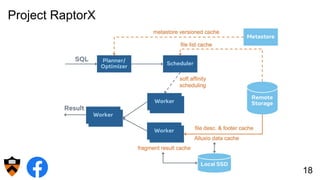

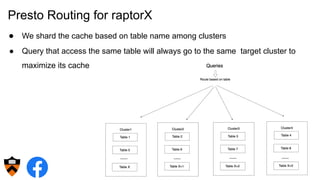
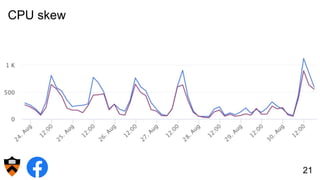


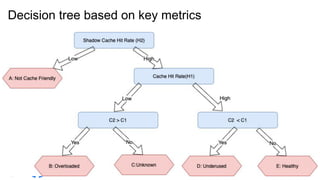


The document discusses the design and implementation of a shadow cache, a lightweight Alluxio component aimed at tracking the working set size and infinite cache hit ratio. It utilizes a chain of Bloom filters to efficiently manage cache operations, addressing challenges such as memory overhead and accuracy in dynamic updates. Additionally, the project explores optimizing cache utilization and routing algorithms within Facebook's environment for improved query performance.


































![[B5]memcached scalability-bag lru-deview-100](https://cdn.slidesharecdn.com/ss_thumbnails/b5memcached-scalability-baglru-deview-100-120919013502-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Hanoi-August 13] Tech Talk on Caching Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/nitecocachingsolution-130826204343-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































