


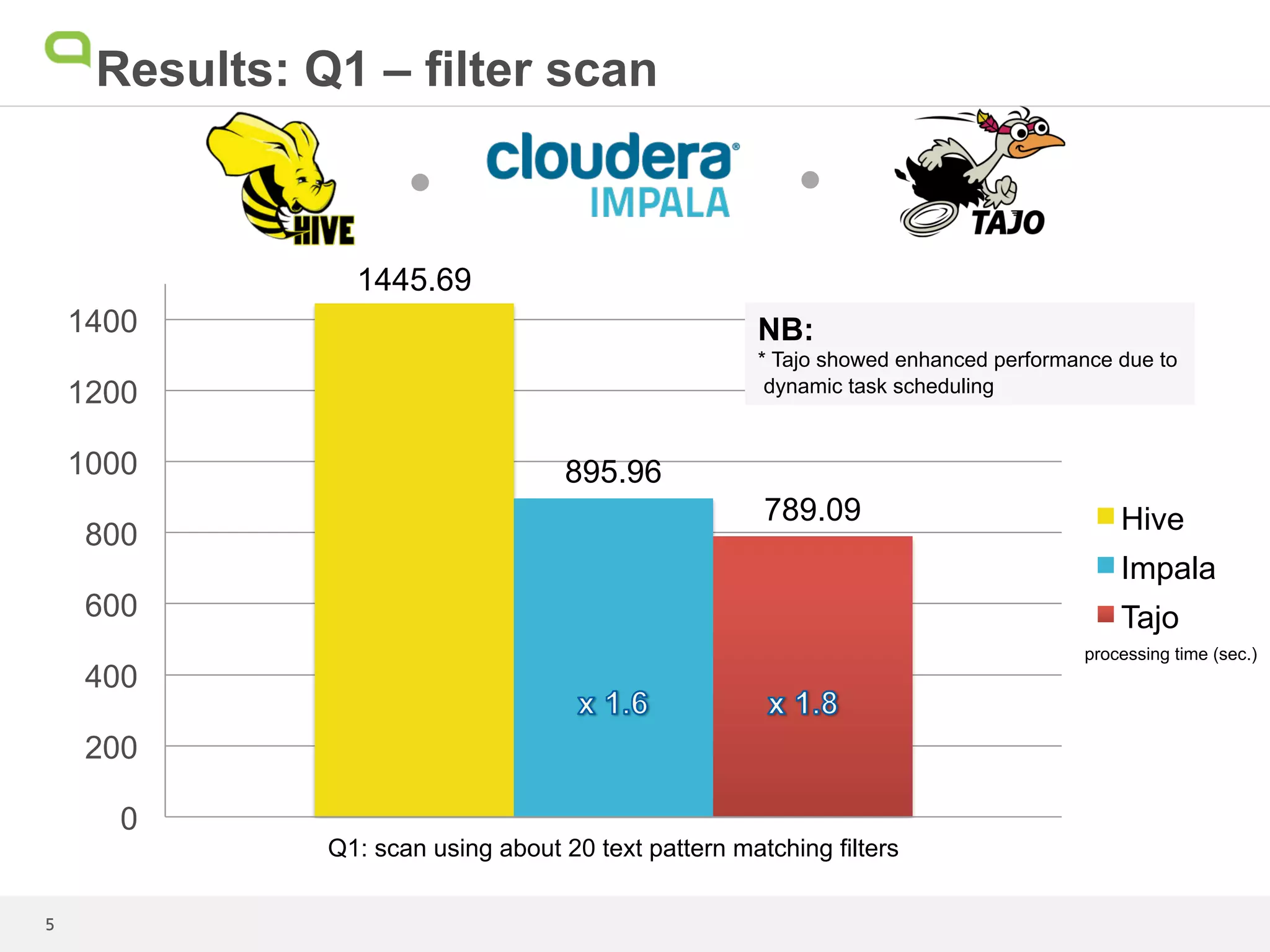
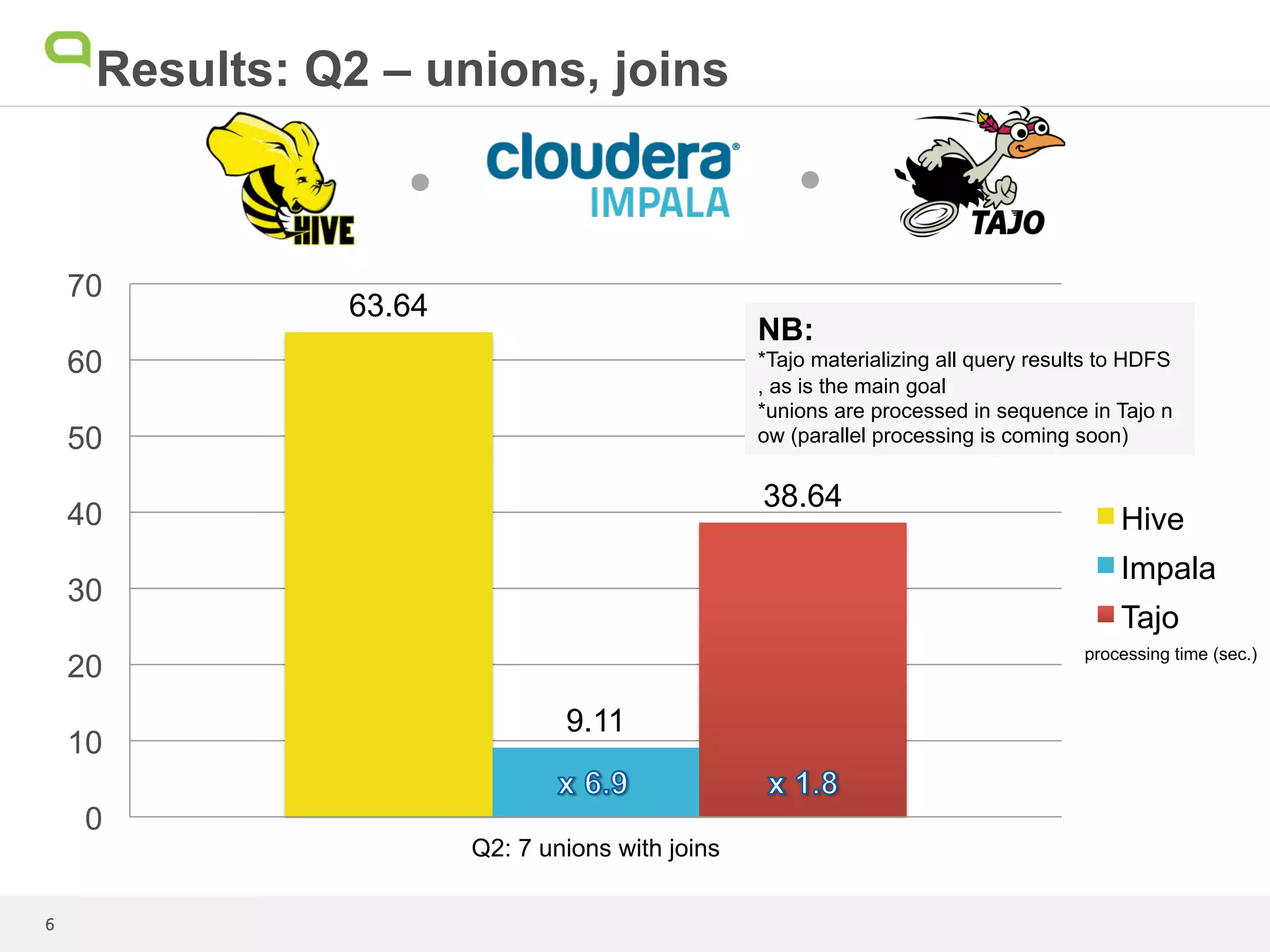
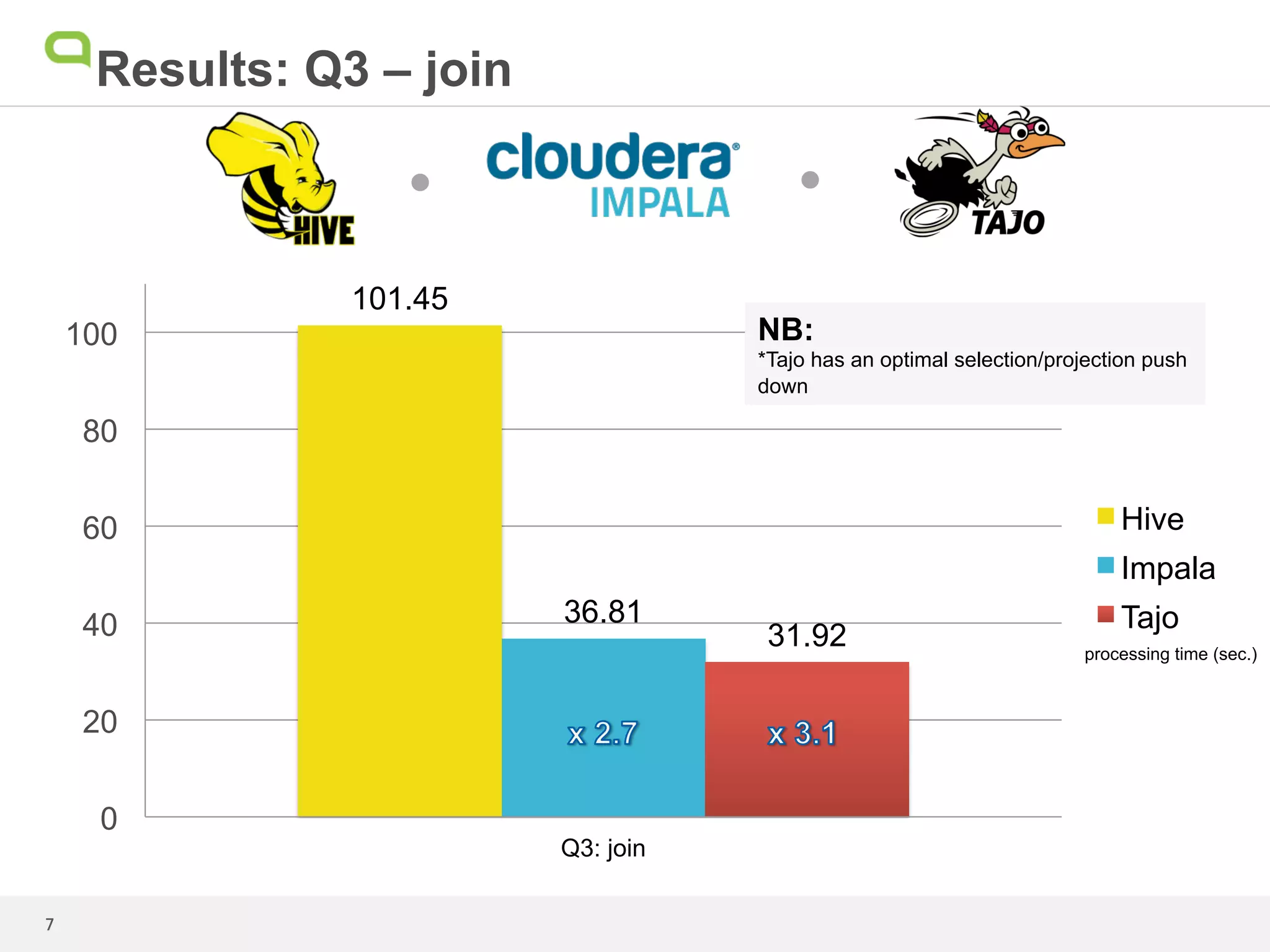
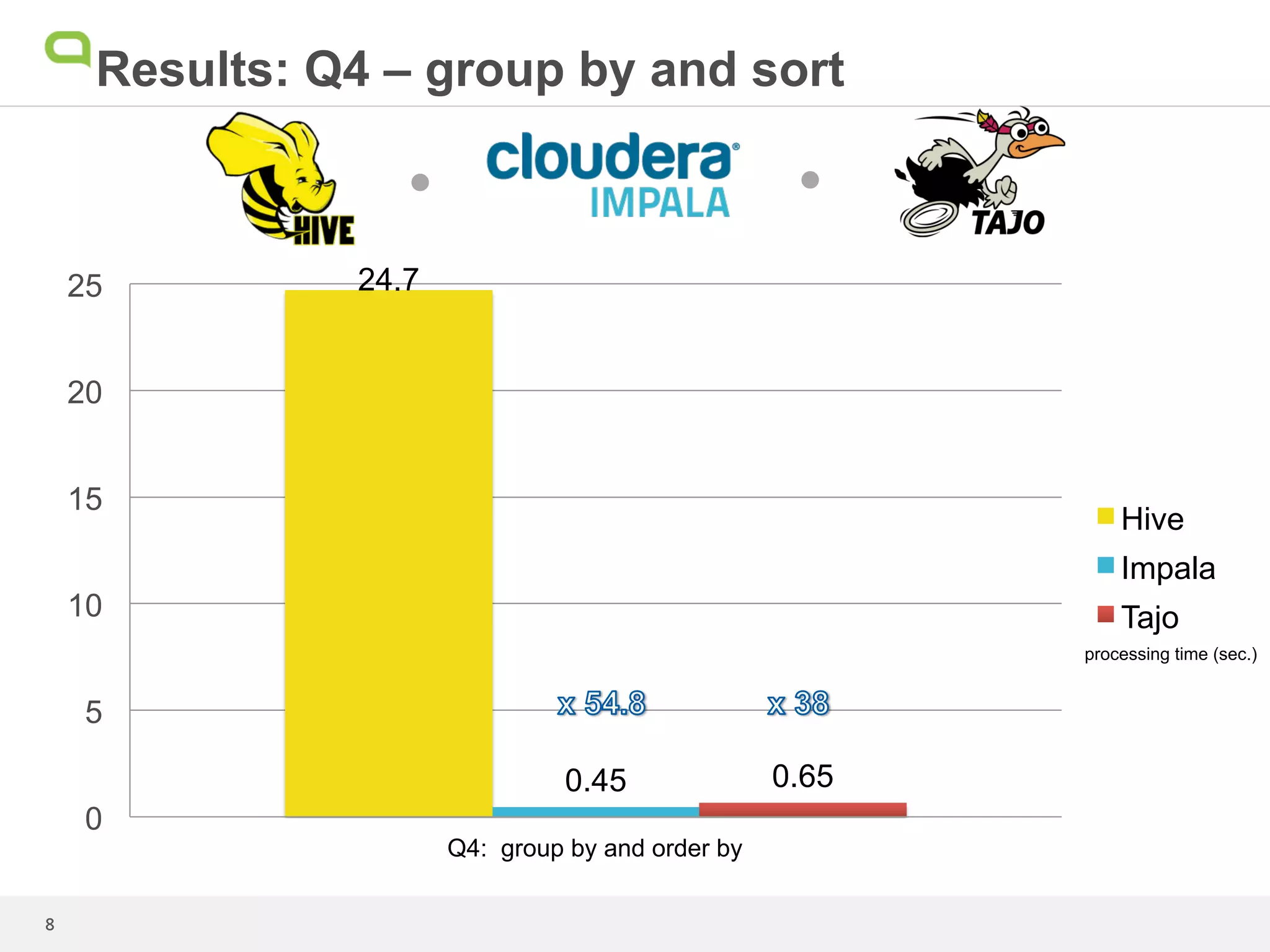
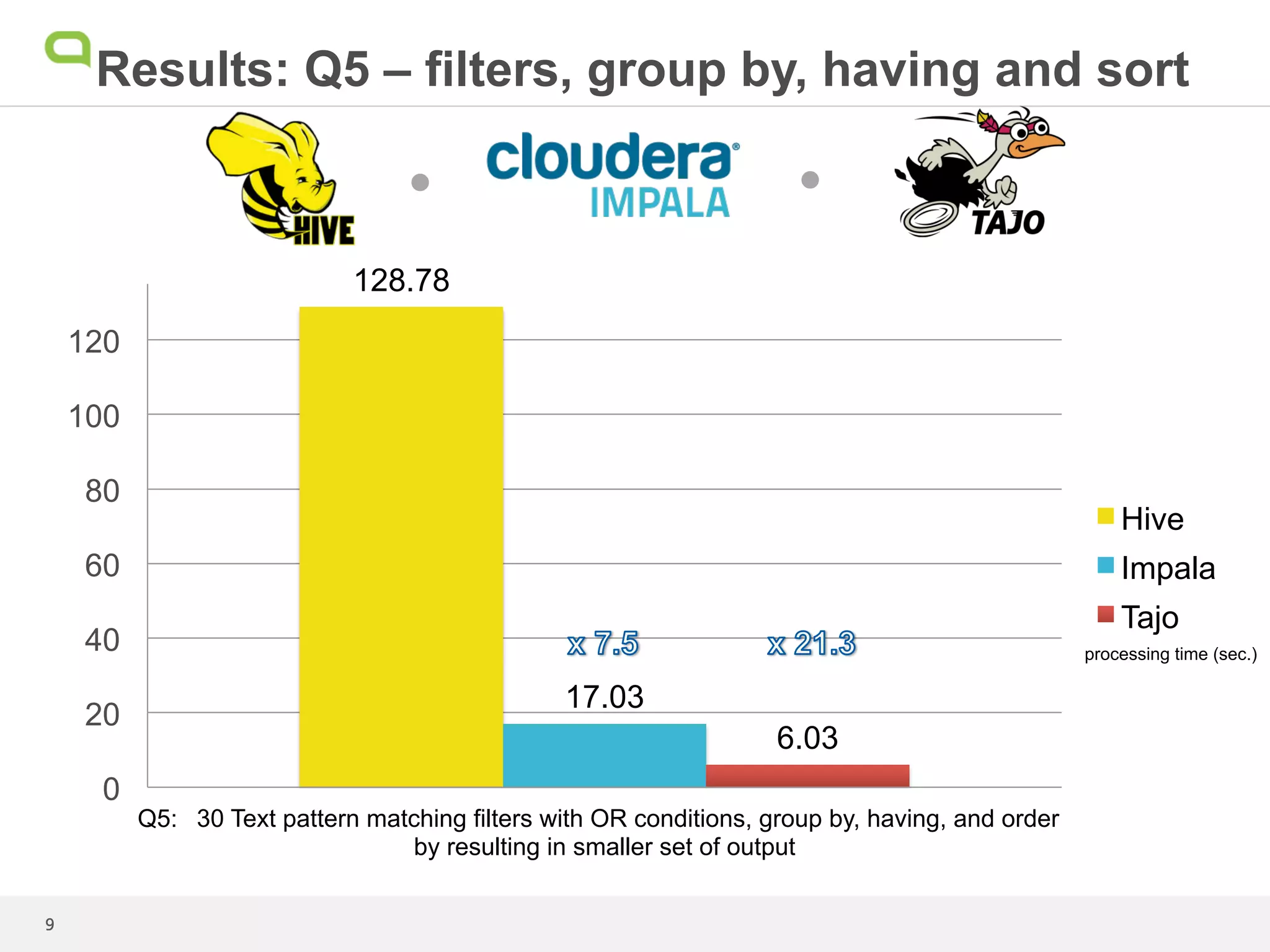



This document summarizes the results of a performance test comparing Hive, Impala, and Tajo on queries against a 1.7TB dataset. Tajo outperformed Hive and Impala on scans with filters and joins. For queries with grouping, aggregation, and sorting, Tajo was faster than Hive and similar to or faster than Impala. The author concludes that even though Tajo materializes all results to HDFS, its performance is promising compared to Impala due to its dynamic task scheduling. Further performance enhancements are expected as the Tajo project continues.
![[Paper Reading] Efficient Query Processing with Optimistically Compressed Has...](https://cdn.slidesharecdn.com/ss_thumbnails/icde-2020-220209161641-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[Td 2015]너에게만 나는 반응해 반응형 응용프로그램(이규원)](https://cdn.slidesharecdn.com/ss_thumbnails/td2015-151104051723-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




























































