Downloaded 48 times







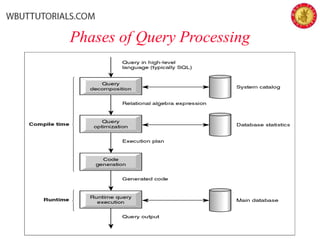



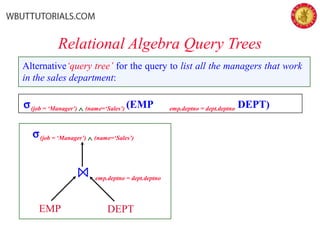
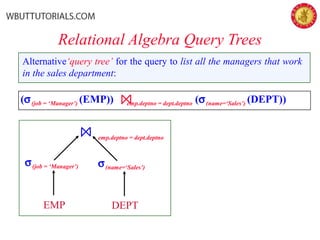














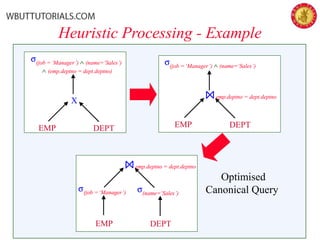










The document outlines the key phases and concepts in query optimization: 1) Parsing the SQL query into an internal representation like a query tree, 2) Applying transformation rules to put the query in canonical form, 3) Estimating the costs of different execution plans, and 4) Selecting the lowest cost plan. Key topics covered include relational algebra trees, transformation rules, heuristic strategies like pushing down selections, and using statistics and cost models to choose the most efficient query execution plan.































































































