Downloaded 60 times



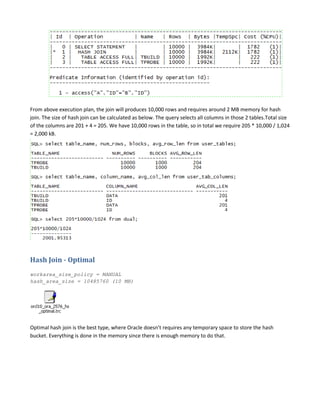

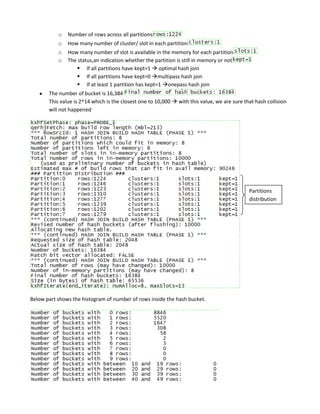
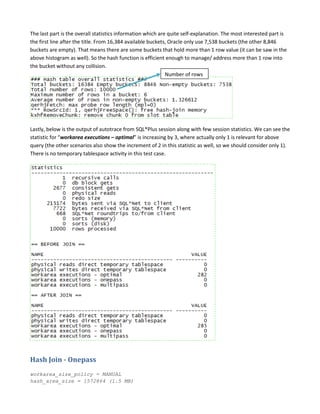


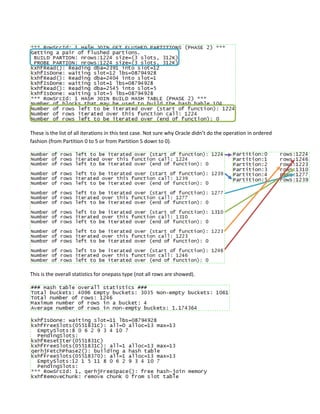

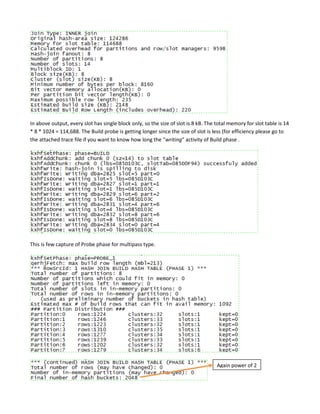
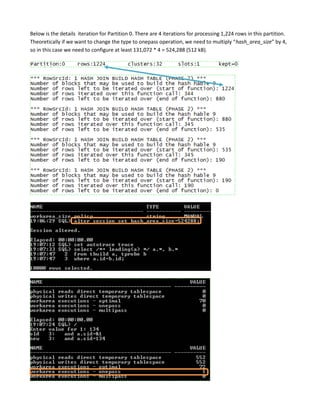



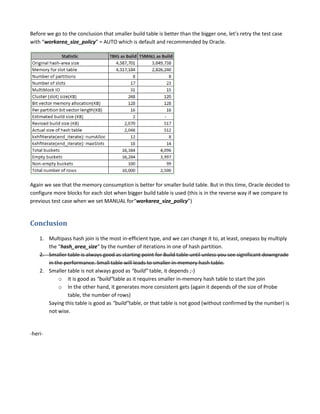

Hash join is a type of join operation that uses a hash table to perform the join. There are three types of hash joins - optimal, onepass, and multipass. Optimal hash join performs the join entirely in memory, while onepass and multipass hash joins spill data to temporary storage due to insufficient memory. The size of the build table can impact the performance and memory requirements of the hash join, with smaller build tables generally requiring less memory but potentially more disk reads. The best build table depends on the relative sizes of the tables and available memory.



















































































