Download as PDF, PPTX





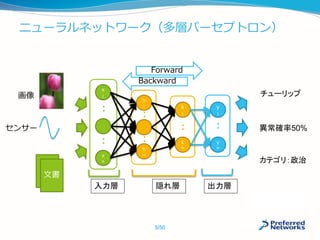
![ディープラーニング(DL:DeepLearning)とは
層が深く、幅も広いニューラルネットワークを利用した
機械学習手法
2012年の大ブレーク以来、研究コミュニティのみならず
産業界に多く使われてきた
2014〜2015年中に出された関連論文数は1500を超える*
画像認識、音声認識などで劇的な精度向上を果たし、その
多くが既に実用化されている
囲碁でもDeepMindの AlphaGoが大きな成果
あと40時間でLee Sedol (魔王)と戦う
2014年の一般画像認識コンテストで優勝した
22層からなるNNの例 [Google]
*http://memkite.com/deep-learning-bibliography/
2015年の一般画像認識コンテストで優勝した
152層からなるNNの例 [MSRA]
6/50](https://image.slidesharecdn.com/20160307ppl-160307053423/85/Chainer-6-320.jpg)
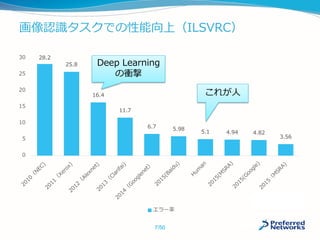








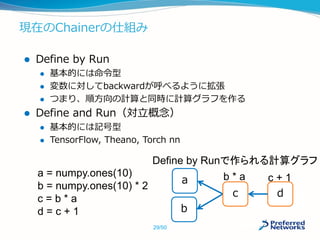
![命令型が有利:記述の自由度
プログラミング言語の制御構文を利用して書ける
複雑な分岐構造や、再帰構造の場合は命令型が有利
a = numpy.ones(10)
b = numpy.ones(10) * 2
c = b * a
d = 0
for i in range(c):
d += c[i] + i
26/50](https://image.slidesharecdn.com/20160307ppl-160307053423/85/Chainer-26-320.jpg)



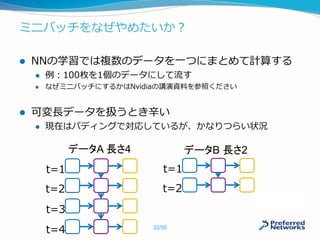





![CuPyはどのくらい早いの?
状況しだいですが、最大数十倍程度速くなります
def test(xp):
a = xp.arange(1000000).reshape(1000, -1)
return a.T * 2
test(numpy)
t1 = datetime.datetime.now()
for i in range(1000):
test(numpy)
t2 = datetime.datetime.now()
print(t2 -t1)
test(cupy)
t1 = datetime.datetime.now()
for i in range(1000):
test(cupy)
t2 = datetime.datetime.now()
print(t2 -t1)
時間
[ms]
倍率
NumPy 2929 1.0
CuPy 585 5.0
CuPy +
Memory Pool
123 23.8
Intel Core i7-4790 @3.60GHz,
32GB, GeForce GTX 970
38/50](https://image.slidesharecdn.com/20160307ppl-160307053423/85/Chainer-38-320.jpg)


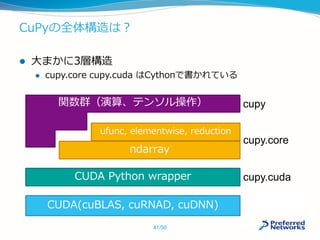
![テンソルの実体
Python側はndarray 、 C++側はCArray
template <typename T, //データ型
int ndim> //次元数
class CArray {
private:
T* data_; //GPUメモリへのポインタ
int size_; //CArray全体の要素数
int shape_[ndim]; //各次元の要素数
int strides_[ndim]; //各次元のストライド
} //不連続な領域を扱うため
42/50](https://image.slidesharecdn.com/20160307ppl-160307053423/85/Chainer-42-320.jpg)









PPL2016@岡山 ディープラーニングの研究開発時には、計算を支援するためのフレームワークが用いられる。ChainerはPython上で動くディープラーニングフレームワークの一つである。他の多くのフレームワークと異なり、順伝播処理を行った時の実行履歴情報をもとに逆伝播のグラフを動的に構築するdefine-by-runという方式を採用している。この方式により、分岐や再帰を含むような複雑な構造のネットワークも直感的に構築でき、加えてデバッグが容易である。また、CuPyと呼ばれるNumPyサブセットのCUDAによる行列演算ライブラリを作成し、バックエンドとして利用している。本講演では、ディープラーニングフレームワークの基礎と実装、そして課題についてChainerを通して説明する。






















![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)












![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)


![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)








