Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Ryo Sakamoto
8,978 views
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
関東GPGPU勉強会#2 山田てるみ 「GPUが100倍速いという神話をぶち殺せたらいいな ver.2013 + Haswell and MIC fix」
Technology
◦
Read more
14
Save
Share
Embed
Embed presentation
1
/ 45
2
/ 45
3
/ 45
4
/ 45
5
/ 45
6
/ 45
7
/ 45
8
/ 45
9
/ 45
10
/ 45
11
/ 45
12
/ 45
13
/ 45
14
/ 45
15
/ 45
16
/ 45
17
/ 45
18
/ 45
19
/ 45
20
/ 45
21
/ 45
22
/ 45
23
/ 45
24
/ 45
25
/ 45
26
/ 45
27
/ 45
28
/ 45
29
/ 45
30
/ 45
31
/ 45
32
/ 45
33
/ 45
34
/ 45
35
/ 45
36
/ 45
37
/ 45
38
/ 45
39
/ 45
40
/ 45
41
/ 45
42
/ 45
43
/ 45
44
/ 45
45
/ 45
More Related Content
PPT
Glibc malloc internal
by
Motohiro KOSAKI
PPTX
画像処理ライブラリ OpenCV で 出来ること・出来ないこと
by
Norishige Fukushima
PDF
きつねさんでもわかるLlvm読書会 第2回
by
Tomoya Kawanishi
PDF
CTF for ビギナーズ バイナリ講習資料
by
SECCON Beginners
PDF
不遇の標準ライブラリ - valarray
by
Ryosuke839
PDF
プログラムを高速化する話
by
京大 マイコンクラブ
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
PDF
潜在ディリクレ配分法
by
y-uti
Glibc malloc internal
by
Motohiro KOSAKI
画像処理ライブラリ OpenCV で 出来ること・出来ないこと
by
Norishige Fukushima
きつねさんでもわかるLlvm読書会 第2回
by
Tomoya Kawanishi
CTF for ビギナーズ バイナリ講習資料
by
SECCON Beginners
不遇の標準ライブラリ - valarray
by
Ryosuke839
プログラムを高速化する話
by
京大 マイコンクラブ
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
潜在ディリクレ配分法
by
y-uti
What's hot
PDF
SAT/SMTソルバの仕組み
by
Masahiro Sakai
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
PDF
明日使えないすごいビット演算
by
京大 マイコンクラブ
PDF
プログラミングコンテストでの動的計画法
by
Takuya Akiba
PDF
暗号技術の実装と数学
by
MITSUNARI Shigeo
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
PDF
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
PDF
線形計画法入門
by
Shunji Umetani
PDF
初心者向けCTFのWeb分野の強化法
by
kazkiti
PDF
Pythonによる黒魔術入門
by
大樹 小倉
PPTX
画像処理の高性能計算
by
Norishige Fukushima
PDF
Docker Compose 徹底解説
by
Masahito Zembutsu
PDF
それはYAGNIか? それとも思考停止か?
by
Yoshitaka Kawashima
PDF
RSA暗号運用でやってはいけない n のこと #ssmjp
by
sonickun
PPTX
DockerコンテナでGitを使う
by
Kazuhiro Suga
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
PDF
マルチコアを用いた画像処理
by
Norishige Fukushima
PPTX
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
PDF
Rustに触れて私のPythonはどう変わったか
by
ShunsukeNakamura17
SAT/SMTソルバの仕組み
by
Masahiro Sakai
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
明日使えないすごいビット演算
by
京大 マイコンクラブ
プログラミングコンテストでの動的計画法
by
Takuya Akiba
暗号技術の実装と数学
by
MITSUNARI Shigeo
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
線形計画法入門
by
Shunji Umetani
初心者向けCTFのWeb分野の強化法
by
kazkiti
Pythonによる黒魔術入門
by
大樹 小倉
画像処理の高性能計算
by
Norishige Fukushima
Docker Compose 徹底解説
by
Masahito Zembutsu
それはYAGNIか? それとも思考停止か?
by
Yoshitaka Kawashima
RSA暗号運用でやってはいけない n のこと #ssmjp
by
sonickun
DockerコンテナでGitを使う
by
Kazuhiro Suga
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
マルチコアを用いた画像処理
by
Norishige Fukushima
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
Rustに触れて私のPythonはどう変わったか
by
ShunsukeNakamura17
Viewers also liked
PDF
Word2vecで大谷翔平の二刀流論争に終止符を打つ!
by
Takami Sato
PDF
AAをつくろう!
by
Takami Sato
PDF
High performance python computing for data science
by
Takami Sato
PDF
Data Science Bowl 2017 Winning Solutions Survey
by
Takami Sato
PPT
30分で博士号がとれる画像処理講座
by
Sakiyama Kei
PDF
NIPS2016論文紹介 Riemannian SVRG fast stochastic optimization on riemannian manif...
by
Takami Sato
PDF
Quoraコンペ参加記録
by
Takami Sato
PDF
Icml2015 論文紹介 sparse_subspace_clustering_with_missing_entries
by
Takami Sato
PDF
Scikit learnで学ぶ機械学習入門
by
Takami Sato
PDF
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
Word2vecで大谷翔平の二刀流論争に終止符を打つ!
by
Takami Sato
AAをつくろう!
by
Takami Sato
High performance python computing for data science
by
Takami Sato
Data Science Bowl 2017 Winning Solutions Survey
by
Takami Sato
30分で博士号がとれる画像処理講座
by
Sakiyama Kei
NIPS2016論文紹介 Riemannian SVRG fast stochastic optimization on riemannian manif...
by
Takami Sato
Quoraコンペ参加記録
by
Takami Sato
Icml2015 論文紹介 sparse_subspace_clustering_with_missing_entries
by
Takami Sato
Scikit learnで学ぶ機械学習入門
by
Takami Sato
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
Similar to GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
KEY
GPGPU deいろんな問題解いてみた
by
Ryo Sakamoto
PDF
機械学習とこれを支える並列計算 : 並列計算の現状と産業応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
PDF
【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
by
Yasuhiro Yoshimura
KEY
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
by
Computational Materials Science Initiative
PDF
Halide による画像処理プログラミング入門
by
Fixstars Corporation
PDF
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
PDF
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
PDF
Hello, DirectCompute
by
dasyprocta
KEY
CUDAを利用したPIV解析の高速化
by
翔新 史
PDF
HalideでつくるDomain Specific Architectureの世界
by
Fixstars Corporation
PPTX
GPUによる多倍長整数乗算の高速化手法の提案
by
Koji Kitano
KEY
GTC2011 Japan
by
Takuro Iizuka
PDF
第12回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
PDF
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
PDF
200625material naruse
by
RCCSRENKEI
PDF
Opencv object detection_takmin
by
Takuya Minagawa
PDF
2012-03-08 MSS研究会
by
Kimikazu Kato
PDF
Slide
by
Takefumi MIYOSHI
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
GPGPU deいろんな問題解いてみた
by
Ryo Sakamoto
機械学習とこれを支える並列計算 : 並列計算の現状と産業応用について
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
by
Yasuhiro Yoshimura
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
by
Computational Materials Science Initiative
Halide による画像処理プログラミング入門
by
Fixstars Corporation
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
Hello, DirectCompute
by
dasyprocta
CUDAを利用したPIV解析の高速化
by
翔新 史
HalideでつくるDomain Specific Architectureの世界
by
Fixstars Corporation
GPUによる多倍長整数乗算の高速化手法の提案
by
Koji Kitano
GTC2011 Japan
by
Takuro Iizuka
第12回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
200625material naruse
by
RCCSRENKEI
Opencv object detection_takmin
by
Takuya Minagawa
2012-03-08 MSS研究会
by
Kimikazu Kato
Slide
by
Takefumi MIYOSHI
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
1.
100倍をぶち殺せたらいいな 関東GPGPU勉強会 #2 山田てるみ
2.
自己紹介 • 山田てるみ • @telmin_orca •
なんちゃってGPUプログラマ
3.
2012∼2013
4.
2012∼2013 • Fermi ->
Kepler http://en.wikipedia.org/wiki/File:Nvidia_logo.svg http://www.nvidia.co.jp/page/home.html
5.
2012∼2013 • GCN Architecture
6.
Mali OpenCL 2012∼2013
7.
2010
8.
Debunking the 100X GPU
vs. CPU Myth GPUが100倍速いという神話をぶち殺す
9.
3 years later... あれから3年が過ぎた…
10.
NVIDIA • Kepler Architecture •
GK110 • SM -> SMX • 32(48) -> 192!! • 1.03TFLOPS -> 3.5TFLOPS!!
12.
の造りし
も の
14.
M I C 、襲来
15.
Xeon Phi • MIC
Architecture • 60 Core / 4 Threads • 32KB / L1 cache • 512KB / L2 cache • 512-bit vector unit!
16.
Debunking the 100X GPU
vs. CPU Myth? ver.2013
17.
大事なこと • 以下の測定結果にはHost <->device間の データ転送時間は含まれていません •
元論文に準拠しました • Haswellのデータも追加しました
18.
SAXPY • y =
Ax+y • かけてたす • 演算量少なすぎてメモリ律速
19.
SAXPY • 実験条件 • 要素数:10000000
20.
SAXPY void simpleSaxpy(double* x,
double* y, const double A, const size_t num) { for(size_t i = 0; i < num; ++i) { y[i] = a * x[i] + y[i]; } }
21.
SAXPY OpenMP + AVX void
avxSaxpy(const double* x, double* y, const double a, const size_t num) { __m256d v_a = _mm256_set1_pd(a); #pragma omp parallel for for(int i = 0 ; i < num / 4; ++i) { __m256d v_x0 = _mm256_loadu_pd(&x[i * 4]); __m256d v_y0 = _mm256_loadu_pd(&y[i * 4]); __m256d v01 = _mm256_mul_pd(v_a, v_x0); __m256d v02 = _mm256_add_pd(v01, v_y0); _mm256_storeu_pd(&y[i * 4], v02); } }
22.
SAXPY CUDA __global__ void cudaSaxpyKernel(const
double* x, double* y, const double a, const int num_elements) { const int id = blockDim.x * blockIdx.x + threadIdx.x; if(id < num_elements) { y[id] = a * x[id] + y[id]; } }
23.
SAXPY MIC void micSaxpy(const
double* x, double* y, const double a, const size_t num) { __m512d v_a = _mm512_set1_pd(a); #pragma omp parallel for for(int i = 0; i < num / 8; ++i) { __m512d v_x = _mm512_load_pd(&x[i * 8]); __m512d v_y = _mm512_load_pd(&y[i * 8]); __m512d res = _mm512_fmadd_pd(v_x, v_a, v_y); _mm512_storenr_pd(&y[i * 8], res); } }
24.
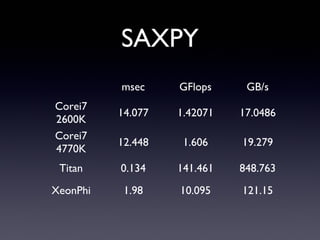
SAXPY msec GFlops GB/s Corei7 2600K 14.077
1.42071 17.0486 Corei7 4770K 12.448 1.606 19.279 Titan 0.134 141.461 848.763 XeonPhi 1.98 10.095 121.15
25.
Histogram • ヒストグラム
26.
Histogram
27.
Histogram • 実験条件 • 1920x1080画像 •
bin: 256
28.
Histogram void simpleHistogram(const unsigned
char* src, std::vector<int>& dst, const size_t width, const size_t height) { // grayscale for(size_t y = 0; y < height; ++y) { for(size_t x = 0; x < width; ++x) { unsigned char val = src[y * width + x]; dst[val]++; } } }
29.
Histogram OpenMP void openMPHistogram(const
unsigned char* src, std::vector<int>& dst, const size_t width, const size_t height) { #pragma omp parallel { std::vector<int> local_dst(256); #pragma omp for for(size_t y = 0; y < height; ++y) { for(size_t x = 0; x < width; ++x) { unsigned char val = src[y * width + x]; local_dst[val]++; } } #pragma omp critical { for(size_t i = 0; i < 256; ++i) { dist[i] += local_dist[i]; } } } }
30.
Histogram CUDA __global__ void histogram_cuda_kernel(const
unsigned char* src, int* dst, const unsigned int width, const unsigned int height, const unsigned int num_elements) { int idx = blockDim.x * blockIdx.x + threadIdx.x; int x = idx % width; int y = idx / width; if(idx < num_elements) { unsigned char val = src[y * width + x]; atomicAdd(&dst[val], 1); } }
31.
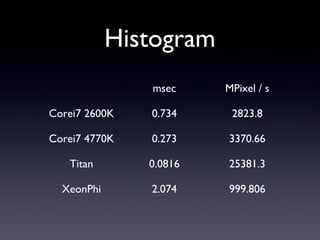
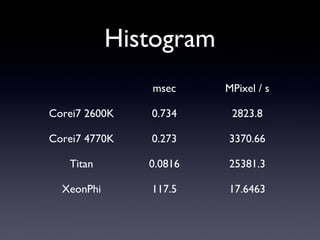
Histogram msec MPixel /
s Corei7 2600K 0.734 2823.8 Corei7 4770K 0.273 3370.66 Titan 0.0816 25381.3 XeonPhi 117.5 17.6463
32.
Histogram MIC void micHistogram_240(const
unsigned char* src, int* dst, const size_t width, const size_t height) { #pragma omp parallel num_threads(240) { const size_t thread_id = omp_get_thread_num(); const size_t num_threads = omp_get_num_threads(); size_t local_height = height / num_threads; local_height += (thread_id % 2)? 0 : 1; const size_t offset = 5 * thread_id -‐ (thread_id / 2); std::vector<int> local_dst(256); std::vector<unsigned char> local_src(local_height * width); memcpy(&local_src[0], &src[offset * width], sizeof(unsigned char) * local_height * width); for(size_t y = 0; y < local_height; ++y) { for(size_t x = 0; x < width; ++x) { size_t val = local_src[y * width + x]; local_dst[val]++; } } #pragma omp critical { for(size_t i = 0; i < 256; ++i) { dst[i] += local_dst[i]; } } } }
33.
Histogram msec MPixel /
s Corei7 2600K 0.734 2823.8 Corei7 4770K 0.273 3370.66 Titan 0.0816 25381.3 XeonPhi 2.074 999.806
34.
NL-means • Non-local Algorithm •
A non-local algorithm for image denoising • http://bengal.missouri.edu/~kes25c/nl2.pdf • バイラテラルフィルタの親戚
35.
NL-means • エッジキープ型のフィルタ • ノイズを除去しつつもボケにくい! •
Aviutilとかにプラグインがある
36.
NL-means http://opencv.jp/opencv2-x-samples/non-local-means-filter by fukushima1981.
37.
NL-means
38.
NL-means • 実験条件 • 1920x1080画像 •
Window size : 7x7 • Template size : 3x3
39.
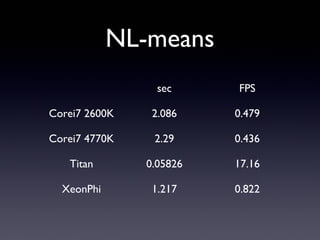
NL-means sec FPS Corei7 2600K
2.086 0.479 Corei7 4770K 2.29 0.436 Titan 0.05826 17.16 XeonPhi 1.217 0.822
40.
Aobench • Ambient Occlution •
前回もやった • Intelもサンプルに 使用 http://software.intel.com/en-us/articles/data-and-thread-parallelism/
41.
Aobench • 実験条件 • 512x512画像 •
NSUBSAMPLE: 2 • NTHETA: 16 • NPHI: 16
42.
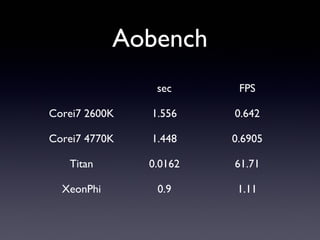
Aobench sec FPS Corei7 2600K
1.556 0.642 Corei7 4770K 1.448 0.6905 Titan 0.0162 61.71 XeonPhi 0.9 1.11
43.
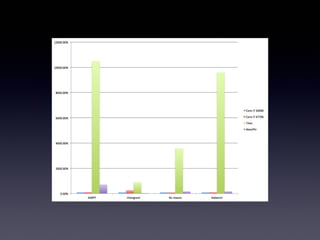
0.00%$ 2000.00%$ 4000.00%$ 6000.00%$ 8000.00%$ 10000.00%$ 12000.00%$ SAXPY$ Histogram$ NL:means$
Aobench$ Core$i7$2600K$ Core$i7$4770K$ Titan$ XeonPhi$
44.
結論 • CPUがGPUを倒す未来は もう少し先の物語…




















![SAXPY
void
simpleSaxpy(double*
x,
double*
y,
const
double
A,
const
size_t
num)
{
for(size_t
i
=
0;
i
<
num;
++i)
{
y[i]
=
a
*
x[i]
+
y[i];
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-20-320.jpg)
![SAXPY OpenMP +
AVX
void
avxSaxpy(const
double*
x,
double*
y,
const
double
a,
const
size_t
num)
{
__m256d
v_a
=
_mm256_set1_pd(a);
#pragma
omp
parallel
for
for(int
i
=
0
;
i
<
num
/
4;
++i)
{
__m256d
v_x0
=
_mm256_loadu_pd(&x[i
*
4]);
__m256d
v_y0
=
_mm256_loadu_pd(&y[i
*
4]);
__m256d
v01
=
_mm256_mul_pd(v_a,
v_x0);
__m256d
v02
=
_mm256_add_pd(v01,
v_y0);
_mm256_storeu_pd(&y[i
*
4],
v02);
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-21-320.jpg)
![SAXPY CUDA
__global__
void
cudaSaxpyKernel(const
double*
x,
double*
y,
const
double
a,
const
int
num_elements)
{
const
int
id
=
blockDim.x
*
blockIdx.x
+
threadIdx.x;
if(id
<
num_elements)
{
y[id]
=
a
*
x[id]
+
y[id];
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-22-320.jpg)
![SAXPY MIC
void
micSaxpy(const
double*
x,
double*
y,
const
double
a,
const
size_t
num)
{
__m512d
v_a
=
_mm512_set1_pd(a);
#pragma
omp
parallel
for
for(int
i
=
0;
i
<
num
/
8;
++i)
{
__m512d
v_x
=
_mm512_load_pd(&x[i
*
8]);
__m512d
v_y
=
_mm512_load_pd(&y[i
*
8]);
__m512d
res
=
_mm512_fmadd_pd(v_x,
v_a,
v_y);
_mm512_storenr_pd(&y[i
*
8],
res);
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-23-320.jpg)


![Histogram
void
simpleHistogram(const
unsigned
char*
src,
std::vector<int>&
dst,
const
size_t
width,
const
size_t
height)
{
//
grayscale
for(size_t
y
=
0;
y
<
height;
++y)
{
for(size_t
x
=
0;
x
<
width;
++x)
{
unsigned
char
val
=
src[y
*
width
+
x];
dst[val]++;
}
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-28-320.jpg)
![Histogram OpenMP
void
openMPHistogram(const
unsigned
char*
src,
std::vector<int>&
dst,
const
size_t
width,
const
size_t
height)
{
#pragma
omp
parallel
{
std::vector<int>
local_dst(256);
#pragma
omp
for
for(size_t
y
=
0;
y
<
height;
++y)
{
for(size_t
x
=
0;
x
<
width;
++x)
{
unsigned
char
val
=
src[y
*
width
+
x];
local_dst[val]++;
}
}
#pragma
omp
critical
{
for(size_t
i
=
0;
i
<
256;
++i)
{
dist[i]
+=
local_dist[i];
}
}
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-29-320.jpg)
![Histogram CUDA
__global__
void
histogram_cuda_kernel(const
unsigned
char*
src,
int*
dst,
const
unsigned
int
width,
const
unsigned
int
height,
const
unsigned
int
num_elements)
{
int
idx
=
blockDim.x
*
blockIdx.x
+
threadIdx.x;
int
x
=
idx
%
width;
int
y
=
idx
/
width;
if(idx
<
num_elements)
{
unsigned
char
val
=
src[y
*
width
+
x];
atomicAdd(&dst[val],
1);
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-30-320.jpg)
![Histogram MIC
void
micHistogram_240(const
unsigned
char*
src,
int*
dst,
const
size_t
width,
const
size_t
height)
{
#pragma
omp
parallel
num_threads(240)
{
const
size_t
thread_id
=
omp_get_thread_num();
const
size_t
num_threads
=
omp_get_num_threads();
size_t
local_height
=
height
/
num_threads;
local_height
+=
(thread_id
%
2)?
0
:
1;
const
size_t
offset
=
5
*
thread_id
-‐
(thread_id
/
2);
std::vector<int>
local_dst(256);
std::vector<unsigned
char>
local_src(local_height
*
width);
memcpy(&local_src[0],
&src[offset
*
width],
sizeof(unsigned
char)
*
local_height
*
width);
for(size_t
y
=
0;
y
<
local_height;
++y)
{
for(size_t
x
=
0;
x
<
width;
++x)
{
size_t
val
=
local_src[y
*
width
+
x];
local_dst[val]++;
}
}
#pragma
omp
critical
{
for(size_t
i
=
0;
i
<
256;
++i)
{
dst[i]
+=
local_dst[i];
}
}
}
}](https://image.slidesharecdn.com/gpgpu2-130606102328-phpapp02/85/GPU-100-ver-2013-32-320.jpg)