CuPyの簡単な解説を行います。NumPyと比較してCuPyによりどのくらい早くなるかや、利用上の注意点(メモリプール)について説明します。 ElementwiseKenrnel, ReductionKernelの使い方も解説します。 CuPyの実装のすごーくざっくーりした全体概要にも触れます。






![CuPyってどのくらい早くなるの?
状況によりけりですが、最大数十倍程度速くなります
def test(xp):
a = xp.arange(1000000).reshape(1000, -1)
return a.T * 2
test(numpy)
t1 = datetime.datetime.now()
for i in range(1000):
test(numpy)
t2 = datetime.datetime.now()
print(t2 -t1)
test(cupy)
t1 = datetime.datetime.now()
for i in range(1000):
test(cupy)
t2 = datetime.datetime.now()
print(t2 -t1)
時間[ms] 倍率
NumP
y
2929 1
CuPy 585 5
6](https://image.slidesharecdn.com/20151219-151219062257/85/CuPy-6-320.jpg)
![5倍しかなってない!もっと早くならないの?
なります
メモリープールを有効にしましょう
cupy.cuda.set_allocator(cupy.cuda.MemoryPool().malloc)
面倒であれば「import chainer」でもOK
なぜ早くなるか?
CUDAではmalloc, freeの実行時にCPUとGPUが同期する
CuPyでは一度mallocした領域を使いまわすことで同期を回避
cupy.cuda.set_allocator(cupy.cuda.MemoryPool().malloc)
test(cupy)
t1 = datetime.datetime.now()
for i in range(cnt):
test(cupy)
t2 = datetime.datetime.now()
print(t2 -t1)
時間[ms] 倍率
NumPy 2929 1
CuPy 585 5
CuPy
メモリプール
123 24
7](https://image.slidesharecdn.com/20151219-151219062257/85/CuPy-7-320.jpg)




![配列に自由にアクセスしたい時は?
例えば、bincountがしたいときは?
「raw」をつけると配列の添え字アクセスができる
for x in arr_x:
bin[x] += 1
cupy.ElementwiseKernel(
'S x',
'raw U bin',
'atomicAdd(&bin[x], 1)',
'bincount_kernel')
12](https://image.slidesharecdn.com/20151219-151219062257/85/CuPy-12-320.jpg)



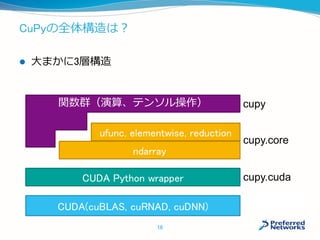

![ndarray の実体ってどうなっているの?
Cython側の実装:cupy/core/core.pyx
CUDA側の実装:cupy/core/carray.cuh
メンバとしては以下のようなものを持っている
詳しく説明しません
template <typename T, int ndim>
class CArray {
private:
T* data_;
int size_;
int shape_[ndim];
int strides_[ndim];
18](https://image.slidesharecdn.com/20151219-151219062257/85/CuPy-18-320.jpg)




![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)














![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
















































