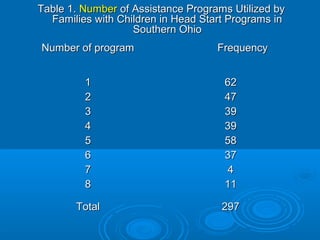
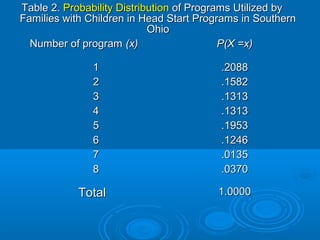
This document discusses probability distributions and provides examples of calculating probabilities using binomial distributions. It begins by defining a probability distribution as a table, graph or formula used to specify the possible values and probabilities of a discrete random variable. It then gives examples of probability distributions for number of assistance programs used by families and calculates related probabilities. The document introduces binomial distribution and provides two examples of calculating probabilities of outcomes for binomial processes, such as number of full term births out of total births. It describes key concepts like Bernoulli trials, processes and use of combinations and factorials to calculate probabilities for larger sample sizes.




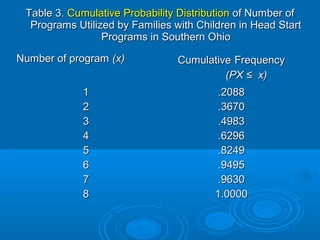
![ Cumulative Probability forCumulative Probability for xxii is written asis written as F (xF (xii)) == P(XP(X ≤ x≤ xii))
[[ XX is less than or equal to a specified value,is less than or equal to a specified value, xxii
eg.eg. FF (2) =(2) = PP (( XX ≤ 2) ]≤ 2) ]
The graph of a cumulativeThe graph of a cumulative probability distribution is called ‘probability distribution is called ‘OgiveOgive’’..
(See text)(See text)
By consulting the cumulativeBy consulting the cumulative probability distribution we canprobability distribution we can
answer the following questionsanswer the following questions
Q 3Q 3: What is the probability that a family picked at random will be: What is the probability that a family picked at random will be
one who used twoone who used two oror fewer programs?fewer programs?
Q 4Q 4: What is the probability that a family picked at random will be: What is the probability that a family picked at random will be
one who used fewer than four programs?one who used fewer than four programs?
Q 5Q 5: What is the probability that a family picked at random will be: What is the probability that a family picked at random will be
one who used fiveone who used five oror more programs?more programs?
Q 6Q 6: What is the probability that a family picked at random will be: What is the probability that a family picked at random will be
one who used between three and five programs, inclusive?one who used between three and five programs, inclusive?](https://image.slidesharecdn.com/probdistribution-170623040550/85/Probablity-distribution-7-320.jpg)


![II. The binomial distributionII. The binomial distribution
- Derived from a- Derived from a BernoulliBernoulli trial or process [Swiss Mathematiciantrial or process [Swiss Mathematician
James Bernoulli (1654-1705)]James Bernoulli (1654-1705)]
- When a random process or experiment or a trial can result in- When a random process or experiment or a trial can result in
only one of two mutually exclusive outcomes such as dead oronly one of two mutually exclusive outcomes such as dead or
alive, sick or well, full-term or premature, the trial is known as aalive, sick or well, full-term or premature, the trial is known as a
BernoulliBernoulli trial.trial.](https://image.slidesharecdn.com/probdistribution-170623040550/85/Probablity-distribution-10-320.jpg)



![ Large sample procedure: Use of ‘combination’Large sample procedure: Use of ‘combination’
If a set consists ofIf a set consists of nn objects, and we wish to form a subset ofobjects, and we wish to form a subset of xx
objects from theseobjects from these nn objects, without regard to the order of theobjects, without regard to the order of the
objects in the subset, the result is called aobjects in the subset, the result is called a combinationcombination
Definition of combination: ADefinition of combination: A combinationcombination ofof nn objects takenobjects taken xx atat
a time is an unordered subset ofa time is an unordered subset of xx ofof nn objectsobjects
nn CC xx == nn ! /! / xx ! (! ( nn –– xx) ! ( ! is read factorial)) ! ( ! is read factorial)
55 CC 33 = 5= 5 ! / 3 ! ( 5 – 3) !! / 3 ! ( 5 – 3) !
= 5 · 4 ·3 · 2 · 1 / 3 · 2 · 1 · 2 · 1= 5 · 4 ·3 · 2 · 1 / 3 · 2 · 1 · 2 · 1
= 120 / 12= 120 / 12
= 10= 10
[Note 1: 0[Note 1: 0 ! = 1]! = 1]](https://image.slidesharecdn.com/probdistribution-170623040550/85/Probablity-distribution-14-320.jpg)



![ Example 4 usingExample 4 using Table BTable B: 55 % of residents said ‘childhood: 55 % of residents said ‘childhood
obesity is a serious problem’. If a random sample of 12obesity is a serious problem’. If a random sample of 12
residents is selected, what is the probability thatresidents is selected, what is the probability that exactly sevenexactly seven
of 12 residents (sample) said the statement is ‘a seriousof 12 residents (sample) said the statement is ‘a serious
problem’?problem’?
P ( X = xP ( X = x || n , p > .5n , p > .5) =) = P ( X = n – xP ( X = n – x | n| n , 1- p, 1- p))
P ( X = 7P ( X = 7 || 12 , p > .5512 , p > .55) =) = P ( X = 5P ( X = 5 | 12| 12 , p =.45, p =.45))
P ( X = 5P ( X = 5 | 12| 12 , p =.45, p =.45) = P (X ≤ 5) - P (X ≤ 4)) = P (X ≤ 5) - P (X ≤ 4)
= .5269 - .3044= .5269 - .3044 ←← [From Table B][From Table B]
== .2225.2225](https://image.slidesharecdn.com/probdistribution-170623040550/85/Probablity-distribution-18-320.jpg)

![[Note 2: How to calculate 12[Note 2: How to calculate 12 !! // 7 ! 5 ! by an easier method ?7 ! 5 ! by an easier method ?
1212 !! // 7 ! 5 ! = 12·11·10·9·8·7·6·5·4·3·2·17 ! 5 ! = 12·11·10·9·8·7·6·5·4·3·2·1// (7·6·5·4·2·3·2·1) 5·4·3·2·1(7·6·5·4·2·3·2·1) 5·4·3·2·1
= 12·11·10·9·8= 12·11·10·9·8 7 !7 ! // 7 !7 ! 5·4·3·2·15·4·3·2·1
= 12·11·10·9·8= 12·11·10·9·8 // 5·4·3·2·15·4·3·2·1
= 792 ]= 792 ]
[Note 3: mean of binomial distribution =[Note 3: mean of binomial distribution = μμ == npnp
variancevariance of binomial distribution =of binomial distribution = σσ 22
== np (1-p)np (1-p) ]]](https://image.slidesharecdn.com/probdistribution-170623040550/85/Probablity-distribution-20-320.jpg)
![ III. The Poisson DistributionIII. The Poisson Distribution
[French Mathematician Denis Poisson (1781 – 1840)][French Mathematician Denis Poisson (1781 – 1840)]
IfIf xx is the number of occurrences of some random event in anis the number of occurrences of some random event in an
interval of time or space (or some volume of matter), theinterval of time or space (or some volume of matter), the
probability thatprobability that xx will occur is given by:will occur is given by:
f (x) = ef (x) = e--λλ
λλ xx
/ x/ x !!
(( λλ = a parameter of the distribution, the average number of= a parameter of the distribution, the average number of
occurrences of the random event in the interval or volume;occurrences of the random event in the interval or volume;
e = a constant , 2.7183)e = a constant , 2.7183)](https://image.slidesharecdn.com/probdistribution-170623040550/85/Probablity-distribution-21-320.jpg)





![ IV. The Normal DistributionIV. The Normal Distribution
The Gaussian distribution [Carl Friedrich Gauss (1777-1855)]The Gaussian distribution [Carl Friedrich Gauss (1777-1855)]
The normal density is:The normal density is:
f (x) = (1/f (x) = (1/√√ 22ππσσ ) e) e-(x--(x- µµ)2/2)2/2σσ22
( -( -∞∞< x << x < ∞)∞)
Characteristics of the normal distributionCharacteristics of the normal distribution
1. It is symmetrical about the mean,1. It is symmetrical about the mean, µ . The curve on either side ofµ . The curve on either side of
µ is mirror image of the other sideµ is mirror image of the other side
2. The mean, the median and mode are all equal.2. The mean, the median and mode are all equal.
3. The total area under the curve above the x axis is3. The total area under the curve above the x axis is one squareone square
unitunit. Normal distribution is probability distribution. 50% of the. Normal distribution is probability distribution. 50% of the
area is to the right of a perpendicular erected at the mean andarea is to the right of a perpendicular erected at the mean and
50% is to the left.50% is to the left.
4. 1 SD from the mean in both directions, the area is 68%.4. 1 SD from the mean in both directions, the area is 68%.
For 2 SD and 3 SD, areas are 95% and 99.7% respectivelyFor 2 SD and 3 SD, areas are 95% and 99.7% respectively](https://image.slidesharecdn.com/probdistribution-170623040550/85/Probablity-distribution-27-320.jpg)









































![ch_5-8_probability155[1].ppt](https://cdn.slidesharecdn.com/ss_thumbnails/ch5-8probability1551-231116061842-b428d0bc-thumbnail.jpg?width=640&height=640&fit=bounds)




















































