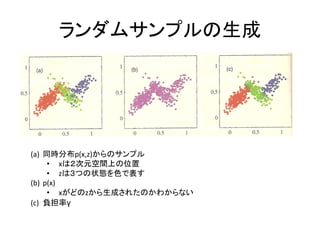
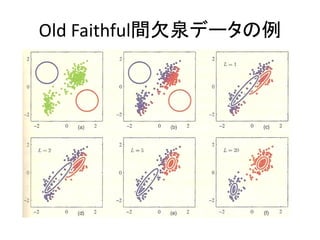
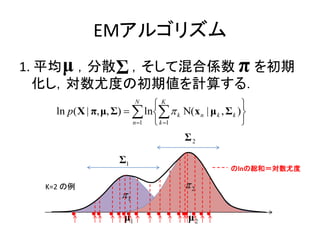
この章でやりたいこと
• ある観測データxが混合ガウス分布に従うときの最尤
推定を行いたい.
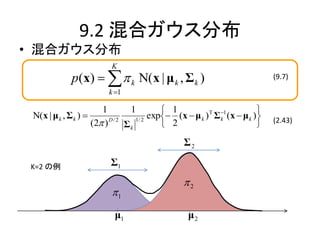
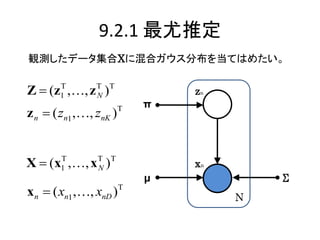
混合ガウス分布
K
p(x) k Ν( x | μ k , Σ k ) (9.7)
k 1
尤度関数
N
K
p( X | π, μ, Σ) k Ν(x n | μ k , Σ k )
n 1 k 1
観測データが与
えられたとき
こいつを最大化する こいつらを求めたい
そのための計算方法を求める = EMアルゴリズムの導出
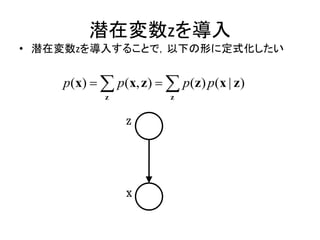
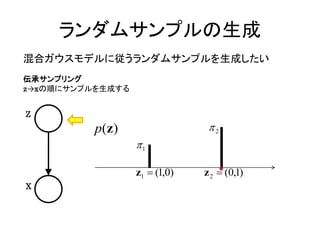
潜在変数z
z z1,, zk ,, zK
K
zk 0,1, zk 1
T
k 1
潜在変数の事前分布 P(z)
p ( z k 1) k
K
p(z )
zk K
k 0 k 1,
k 1
(9.10)
k 1 k 1
K=2 の例 p(z) 2
1
z1 (1,0) z 2 (0,1)
7.
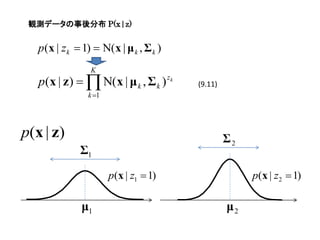
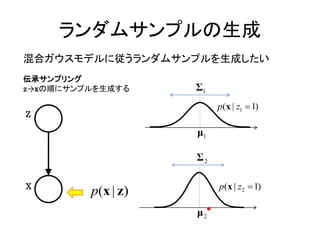
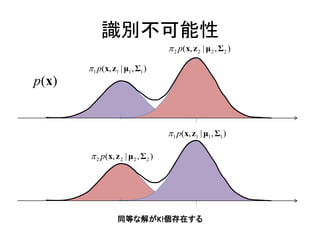
観測データの事後分布 P(x|z)
p(x | zk 1) Ν( x | μ k , Σ k )
K
p(x | z ) Ν( x | μ k , Σ k ) zk
(9.11)
k 1
p(x | z) Σ2
Σ1
p(x | z1 1) p(x | z2 1)
μ1 μ2
8.
演習9.3
K K
p(z ) zk
k (9.10) と p(x | z ) Ν( x | μ k , Σ k ) zk (9.11) から
k 1 k 1
K
p(x) k Ν( x | μ k , Σ k ) (9.7) を導く
k 1
答え:
p(x) p(x, z ) p(z) p(x | z )
z z
K K K
N(x | μ , Σ k ) k N( x | μ k , Σ k )
zk zk zk
k k
z k 1 k 1 z k 1
zは1-of-K表現なので,Ikj= (k==j)? 1 : 0 とすると
K K K
k N( x | μ k , Σ k ) kj k N( x | μ k , Σ k )
I
j 1 k 1 j 1
9.
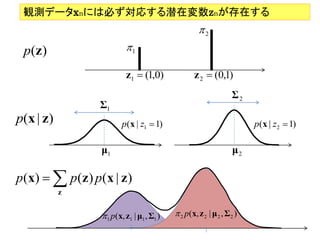
観測データxnには必ず対応する潜在変数znが存在する
2
p(z) 1
z1 (1,0) z 2 (0,1)
Σ2
Σ1
p(x | z) p(x | z1 1) p(x | z2 1)
μ1 μ2
p ( x) p ( z ) p ( x | z )
z
1 p(x, z1 | μ1 , Σ1 ) 2 p(x, z 2 | μ 2 , Σ 2 )
10.
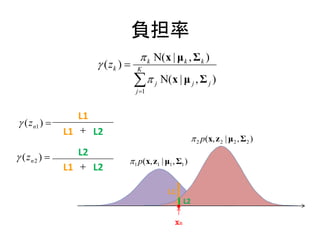
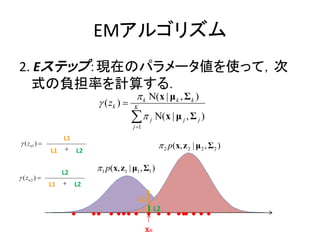
負担率
xが与えられた元でのzkの条件付き確率
k Ν( x | μ k , Σ k )
p( zk 1) p(x | zk 1)
( z k ) p ( z k 1 | x) K
p( z
j 1
k 1) p(x | zk 1)
k Ν(x | μ k , Σ k )
K
j 1
j Ν( x | μ j , Σ j )
『混合要素kがxの観測を「説明する」度合いを表す』
???
データxが混合要素kから発生したものである可能性
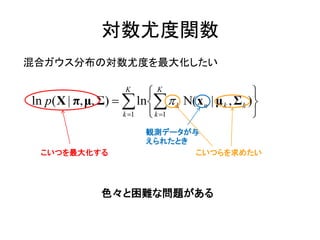
対数尤度関数
混合ガウス分布の対数尤度を最大化したい
K
K
ln p( X | π, μ, Σ) ln k Ν(x n | μ k , Σ k )
k 1 k 1
観測データが与
えられたとき
こいつを最大化する こいつらを求めたい
色々と困難な問題がある
18.
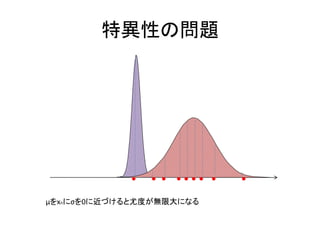
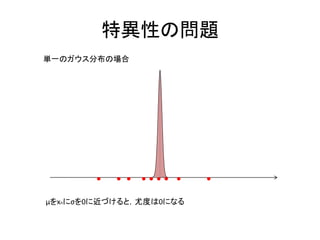
特異性の問題
Σ k σ k I の混合ガウス分布を例に
2
あるデータnについて μ j x n が成り立ったとする。
N( x n | μ n , σ 2 I ) N( x n | x n , σ 2 I )
j j
1 1 1 2 1
exp (x n x n ) (σ j ) (x n x n )
T
(2 ) D/2 2 1/ 2
σj 2
1 1
(2 ) D / 2 j
σ j 0 の時,無限大に発散してしまう
対数尤度関数
混合ガウス分布の対数尤度を用いた最尤推定の困難さ
N
K
ln p( X | π, μ, Σ) ln k Ν(x n | μ k , Σ k )
n 1 k 1
対数の中に和が入ってしまっ
ている
•特異性の問題
•識別不可能性
23.
9.2.2 混合ガウス分布のEMアルゴリ
ズム
対数尤度関数を最大化したい
対数尤度関数:
K
K
ln p( X | π, μ, Σ) ln k Ν(x n | μ k , Σ k )
k 1 k 1
極大値を求めるために,それぞれのパラメータ μ k , Σ k
の導関数が0となる値を求める
K
k については k 1 の制約のもとラグランジュ未定
k 1
係数法で解く
24.
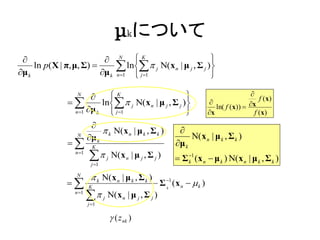
μkについて
N K
μ k
ln p( X | π, μ, Σ)
μ k
ln j Ν(xn | μ j , Σ j )
n 1 j 1
N
K
ln j Ν(x n | μ j , Σ j )
ln( f (x)) x
f ( x)
n 1 μ k j 1 x f ( x)
k Ν( x n | μ k , Σ k )
N
μ k N( x n | μ k , Σ k )
K μ k
n 1
j Ν(x n | μ j , Σ j ) Σ 1 (x μ ) N(x
j 1
k n k n | μk , Σk )
N
k Ν( x n | μ k , Σ k )
K
Σ 1 (x n k )
k
n 1
j 1
j Ν( x n | μ j , Σ j )
( z nk )
25.
μkについて
N
( znk ) Σ 1 (x n μ k ) 0
n 1
k
N N
(z
n 1
nk )μ k ( znk )x n
n 1
N
1 N
μk
Nk
(z
n 1
nk )x n ただし N k ( znk ) (9.17)
n 1
26.
Σkについて
ln p( X | π, μ, Σ) 0 の時
Σ k
N
1
Σk ( z nk )x n μ k x n μ k T となる (9.19)
Nk n 1
スイマセン!解き方がわかりませんでした!
27.
π kについて
K
ln p(X | π,μ,Σ) を
k 1
k 1 の制約のもとで最大化したい
ラグランジュ未定係数法
K
L( k , ) ln p( X | π,μ,Σ) k 1
k 1
N
K K
L( k , ) ln j Ν( x n | μ j , Σ j ) k 1
k n 1 π k j 1 π k k 1
N
Ν( x n | μ k , Σ k )
K 0
n 1
j Ν(x n | μ j , Σ j )
j 1
28.
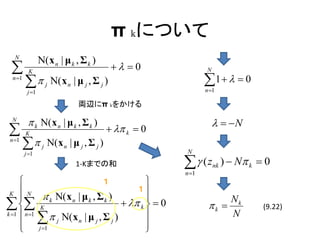
π kについて
N
Ν( x n | μ k , Σ k )
K
0 N
n 1
j Ν( x n | μ j , Σ j ) 1 0
n 1
j 1
両辺にπ kをかける
N
k Ν( x n | μ k , Σ k ) N
K
k 0
n 1
j 1
j Ν( x n | μ j , Σ j )
N
1-Kまでの和 (z
n 1
nk ) N k 0
1
K N
1
k Ν( x n | μ k , Σ k )
K k 0 k
Nk
(9.22)
k 1 n 1
j 1
j Ν(x n | μ j , Σ j )
N
29.
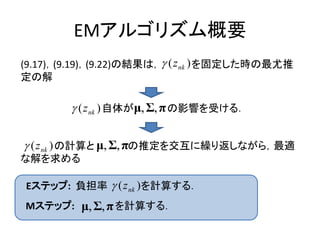
EMアルゴリズム概要
(9.17),(9.19),(9.22)の結果は, (z nk ) を固定した時の最尤推
定の解
( z nk ) 自体がμ, Σ, π の影響を受ける.
( z nk ) の計算と μ, Σ, πの推定を交互に繰り返しながら,最適
な解を求める
Eステップ: 負担率 ( z nk ) を計算する.
Mステップ: μ, Σ, π を計算する.
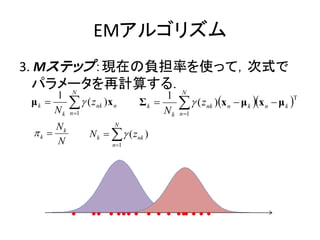
EMアルゴリズム
3. Mステップ:現在の負担率を使って,次式で
パラメータを再計算する.N
1 N 1
μk ( z nk )x n Σk ( z nk )x n μ k x n μ k T
Nk n 1 Nk n 1
Nk N
k N k ( znk )
N n 1
34.
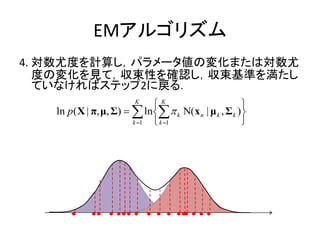
EMアルゴリズム
4. 対数尤度を計算し,パラメータ値の変化または対数尤
度の変化を見て,収束性を確認し,収束基準を満たし
ていなければステップ2に戻る.
K
K
ln p( X | π, μ, Σ) ln k Ν(x n | μ k , Σ k )
k 1 k 1









































![[DL輪読会]機械学習におけるカオス現象について](https://cdn.slidesharecdn.com/ss_thumbnails/20190419dlhacks-190510023936-thumbnail.jpg?width=640&height=640&fit=bounds)








































