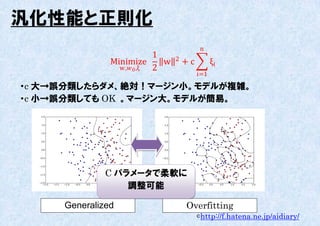
マージン最大化の双対問題
元のマージン最大化問題
n
1 2
Minimize w +c ξi (M.1)
w , 0 ,ξ 2
i=1
subject to ∀i, yi x + 0 − 1 − ξi ≥ 0
(M.2)
∀i, ξi ≥ 0
の双対問題を考える。
この最適化問題をとくためのラグランジュ関数は、
n n n
1
L , 0 , ξ, , μ = w 2
+c ξi − i yi w + w0 − 1 + ξi − μi ξ i (M.3)
2
i=1 i=1 i=1
となる。
13.
ラグランジュ関数を w, 0, ξi で微分したものを 0 でおいて、以下の結果を得る。
n
∂L
=0 ⇒ w= i yi xi (M.4)
∂
i=1
n
∂L
=0 ⇒ i yi = 0 (M.5)
∂0
i=1
∂L
= 0 ⇒ i = c − μn (M.6)
∂ξi
14.
これをもとのラグランジュ関数に代入すると、以下の双対表現が得られる。
双対表現(dual representation)
n n n
1
L = i − i j yi yj xi t xj (81 改)
2
i=1 i=1 j=1
subject to
0 ≤ i ≤ c, i = 1, … , n
n
i yi = 0
i=1
ただし、最初の制約条件はn = c − μn とμn ≥ 0を用いた。
この双対問題の解き方については後述。
15.
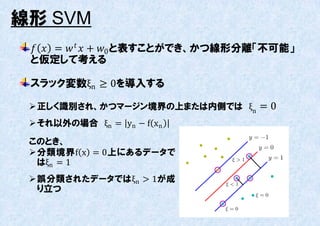
双対問題を解き、i が求まったとして、分類規則は次のようになる。
n
w= i yi xi (83)
i=1
w0 = yi − w t x i
(84)
(但し、xi はi > 0なる任意のxi )
n
f(x) = w t x + w0 = i yi (xi, x) + w0 (85)
i=1
16.
対応する KKT 条件は以下
KKT 条件
i ≥ 0, i = 1, … , n (M.7)
yi w xi + w0 − 1 + ξi ≥ 0 (M.8)
i yi w xi + w0 − 1 + ξi = 0 (M.9)
μi ≥ 0 (M.10)
ξi ≥ 0 (M.11)
μn ξn = 0 (M.12)
よって、全ての訓練データに対し、n = 0またはyi w xi + w0 − 1 + ξi = 0が
成立する。(85)より、n = 0の点は新しいデータ点の予測に寄不しない。
それ以外のn ≠ 0となる点を Support Vector と呼び、マージンの縁に存在す
る。
17.
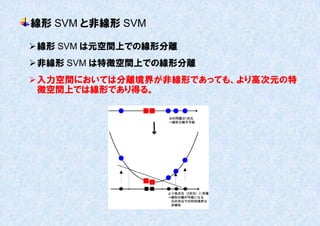
非線形 SVM
d 次元からD 次元への写像φを考え、d 次元ベクトルxi の代わりに、D 次元ベク
トルφ(xi )を新しい n 個の学習パターン(特徴ベクトル)とみなしてみる。
計算式は線形 SVM の場合とほぼ同様になり、マージン最大化を表す式は以下
のようになる。
n
1 2
Minimize w +c ξi (N.1)
w , 0 ,ξ 2
i=1
subject to ∀i, yi φ(xi ) + 0 − 1 − ξi ≥ 0
(N.2)
∀i, ξi ≥ 0
18.
対応するラグランジュ関数は、
L ,0 , ξ, , μ
n n n
1 (N.3)
= w 2
+c ξi − i yi φ(xi ) + w0 − 1 + ξi − μi ξ i
2
i=1 i=1 i=1
これを, 0 , ξi について微分して 0 とおき、以下の双対表現が得られる。
n n n
1
L = i − i j yi yj φ(xi )t φ(xj ) (N.4)
2
i=1 i=1 j=1
19.
d 次元ベクトルxi ,xj を入力とするカーネル関数 k(x,y)があって、k(xi , xj ) ≡
φ(xi )t φ(xj ) が成立するとすれば、以下のようにも表せる。
双対表現(dual representation)
n n n
1
L = i − i j yi yj k(xi , xj ) (89 改)
2
i=1 i=1 j=1
subject to
0 ≤ i ≤ c, i = 1, … , n
n
i yi = 0
i=1
これを解いて、識別関数は
n
f x = i yi k(x, xn ) + 0 (91)
i=1
SMO(sequential minimal optimization)
アイデア
全ての n ではなく、2個のi だけを選び、逐次更新する。
アルゴリズム概略
動かす対象を1 , 2 の2点とする。
このとき、(89)の制約式より以下が成立する。
1 y1 + new y2 = 1 y1 + old y2
new
2
old
2
これと制約式 0 ≤ n ≤ cから以下の新たな制約式が導きだせる。
y1 = y2 の場合
U ≤ new ≤ V
2
where U = max 0, 1 + old − c , V = min
old
2 c, 1 + old
old
2
y1 ≠ y2 の場合
U ≤ new ≤ V
2
where U = max 0, C − 1 + old , V = min
old
2 C, old − 1
2
old
25.
また、目的関数(89)は1 , 2に関連する部分だけに注目して、以下のように
整理できる。
1 1
W 1 , 2 = 1 + 2 − K11 1 − K 22 2 2 − y1 y2 K12 1 2 − y1 ν1 1 − y2 ν2 2 + const.
2
2 2
where
K ij = k xi , xj
n
νi = yj j k xi , xj
j=3
目的関数を2 で微分して=0 とおくことで、更新式が求まる。
new old
y2 f x1 − y1 − f x2 − y2
2 = 2 +
K11 + K 22 − 2K12
この更新式に対して、前述の制約式を適用したものをnew の更新値とする。 2
(1 は1 y1 + new y2 = 1 y1 + old y2 から求まる。)
new new
2
old
2
なお、各部分問題で動かす 2 点の選び方には、いくつかのヒューリスティック
が存在する。