次元の呪い
決定理論
情報理論
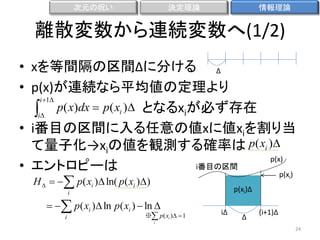
多重度とエントロピー(2/3)
• エントロピーは多重度W
の対数を適当に定数倍
(1/N倍)したもの
H
1
1
1
ln W ln N! ln ni !
N
N
N i
• ni/Nを一定に保ったま
ま、N→∞という極限を考
ln N
え、近似式(1.96)! N ln N N
を用いると教科書(1.97)
n n
H i ln i pi ln pi
N N i
i N
が導出できる
H
1
1
1
ln W ln N !
N
N
N
ln n !
i
i
1
N
( N ln N N ) (ni ln ni ni )
i
1
N
( N ln N N ) ni ln ni ni
i
i
1
N ln N ni ln ni
N
i
1
ln N ni ln ni
N i
n
i ln ni ln N
i N
n
n
i ln ni i ln N
i N
i N
n n
i ln i pi ln pi
N N i
i N
21











![次元の呪い
決定理論
情報理論
損失関数の最小化(2/2)
• 損失関数
E[ L] Lkj p( x, Ck )dx
k
j
j=0
癌
Rj
j=1
正常
0 1000 k=0 癌
L
1
0 k=1正常
損失行列
(誤識別率と比較すると)
p(誤り Lkj p( x, Ck )dx
)
k
j=0
癌
j
Rj
j=1
正常
0 1
L
1 0
k=0 癌
k=1 正常
12](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-12-320.jpg)



![次元の呪い
決定理論
情報理論
情報量とは
• 情報の量は、事象xの値を得た際の驚き度h(x)
「まじで?」 ←h(x)高い
「あっそう」 ←h(x)低い
→h(x)は確率p(x)に関して単調減尐な関数
また、事象xと事象yが無関係なら
h( x, y) h( x) h( y) 、 p( x, y) p( x) p( y) が成立
h( x) log 2 p( x)
単位:[bit]
16](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-16-320.jpg)

![次元の呪い
決定理論
情報理論
エントロピーとは(2/2)
例) 8個の取り得る変数{a, b, c, d, e, f, g, h}の中
から変数の値を1つ伝える時のエントロピー
発生確率全て同じ
=何が起こるかわからない
case1 それぞれの確率{1/8, 1/8 , 1/8 , 1/8 , 1/8 , 1/8 , 1/8 , 1/8 }
→エントロピーは
1
1
H [ x] 8 log 2 3
発生確率偏りあり
8
8
=だいたいaかbだろうと予想つく
case2 それぞれの確率{1/2, 1/4 , 1/8 , 1/16 , 1/64 , 1/64 , 1/64 , 1/64}
→エントロピーは
1
1 1
1 1
1 1
1 1
1
H [ x] log 2 log 2 log 2 log 2 log 2
2
2
2 4
4 8
8 16
16 64
64
18](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-18-320.jpg)
![次元の呪い
決定理論
情報理論
h( x) log 2 p( x)
単位:[bit]
h( x) ln p( x)
単位:[nat]
19](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-19-320.jpg)


![次元の呪い
決定理論
情報理論
多重度とエントロピー(3/3)
• 確率変数Xのエントロピーが定義できる
H pi ln pi
i
H [ p] p( xi ) ln p( xi )
p( X xi ) pi
i
分布が広いほど
エントロピー大
(30個の箱うち)xi番目の箱に割り当てられる確率p(xi)の分布
22](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-22-320.jpg)
![次元の呪い
決定理論
情報理論
エントロピー最大となる分布は?
離散変数ver.
• 問題設定の確認
p( xi ) 1 0
制約 p( xi ) 1
i
i
のもと、 H [ p] p( xi ) ln p( xi ) を最大化
i
• ラグランジュの未定乗数法を使う
~
H p( xi ) ln p( xi ) p( xi ) 1
i
i
• 一様分布
1
p( xi )
M
~
~
H
H
0
p( xi )
のときにエントロピー最大
23](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-23-320.jpg)




![次元の呪い
決定理論
情報理論
KLダイバージェンス≧0
• 凸関数はイェンセンの不等式を満たす
M
M
f i xi i f xi
i 1
i 1
• λi=p(xi)と見ると
f
f E[ x] f ( x)
xp( x)dx f ( x) p( x)dx
• KLダイバージェンスに適用すると
q( x)
KL( p || q) p( x) ln
dx ln q( x)dx 0
p( x)
※q(x)=p(x)のとき0
※ q( x)dx 1
29](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-29-320.jpg)


![次元の呪い
決定理論
情報理論
相互情報量(1/2)
• 変数集合xとyの同時分布p(x, y)を考える
• 変数の集合が独立であれば同時分布は周辺
分布の積 p(x, y)=p(x)p(y)
• 変数が独立でなければ、独立に近いかどうか
を知るために、同時分布と周辺分布の積の
間のKLダイバージェンスを考えることができる
I [ x, y ] KL( p( x, y ) || p( x) p( y ))
=相互情報量
p ( x) p ( y )
p( x, y ) ln
p( x, y ) dxdy
32](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-32-320.jpg)
![次元の呪い
決定理論
情報理論
相互情報量(2/2)
I [ x, y] H [ x] H [ x | y] H [ y] H [ y | x]
• 相互情報量はyの値を知ることによってxに関
する不確実性がどれだけ減尐するかを表す.
• ベイズ的に言えばp(x)をxの事前分布、p(x|y)
は新たなデータyを観測した後の事後分布と
考えられる。したがって、新たにyを観測した
結果として、xに関する不確実性が減尐した
度合いを表している
33](https://image.slidesharecdn.com/prmlchp1latter-131128043525-phpapp02/85/PRML-at-1-33-320.jpg)



















![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)








































