Downloaded 55 times





![Notation
Discount Factor γ
Assume episodic with 0 ≤ γ ≤ 1 or non-episodic with 0 ≤ γ < 1
States st ∈ S, Actions at ∈ A, Rewards rt ∈ R, ∀t ∈ {0, 1, 2, . . .}
State Transition Probabilities Pa
s,s = Pr(st+1 = s |st = s, at = a)
Expected Rewards Ra
s = E[rt|st = s, at = a]
Initial State Probability Distribution p0 : S → [0, 1]
Policy Func Approx π(s, a; θ) = Pr(at = a|st = s, θ), θ ∈ Rk
PGT coverage will be quite similar for non-episodic, by considering
average-reward objective (so we won’t cover it)
Ashwin Rao Policy Gradient Theorem September 1, 2018 6 / 23](https://image.slidesharecdn.com/policygradient-180901184813/85/Policy-Gradient-Theorem-6-320.jpg)
![“Expected Returns” Objective
Now we formalize the “Expected Returns” Objective J(πθ)
J(πθ) = E[
∞
t=0
γt
rt|π]
Value Function V π(s) and Action Value function Qπ(s, a) defined as:
V π
(s) = E[
∞
t=k
γt−k
rt|sk = s, π], ∀k ∈ {0, 1, 2, . . .}
Qπ
(s, a) = E[
∞
t=k
γt−k
rt|sk = s, ak = a, π], ∀k ∈ {0, 1, 2, . . .}
Advantage Function Aπ
(s, a) = Qπ
(s, a) − V π
(s)
Also, p(s → s , t, π) will be a key function for us - it denotes the
probability of going from state s to s in t steps by following policy π
Ashwin Rao Policy Gradient Theorem September 1, 2018 7 / 23](https://image.slidesharecdn.com/policygradient-180901184813/85/Policy-Gradient-Theorem-7-320.jpg)
![Discounted State Visitation Measure
J(πθ) = E[
∞
t=0
γt
rt|π] =
∞
t=0
γt
E[rt|π]
=
∞
t=0
γt
S
(
S
p0(s0) · p(s0 → s, t, π) · ds0)
A
π(s, a; θ) · Ra
s · da · ds
=
S
(
S
∞
t=0
γt
· p0(s0) · p(s0 → s, t, π) · ds0)
A
π(s, a; θ) · Ra
s · da · ds
Definition
J(πθ) =
S
ρπ
(s)
A
π(s, a; θ) · Ra
s · da · ds
where ρπ(s) = S
∞
t=0 γt · p0(s0) · p(s0 → s, t, π) · ds0 is the key function
(for PGT) that we refer to as the Discounted State Visitation Measure.
Ashwin Rao Policy Gradient Theorem September 1, 2018 8 / 23](https://image.slidesharecdn.com/policygradient-180901184813/85/Policy-Gradient-Theorem-8-320.jpg)












![Fisher Information Matrix
Denoting [∂ log π(s,a;θ)
∂θi
], i = 1, . . . , n as the score column vector SC(s, a; θ)
and denoting ∂J(πθ)
∂θ as θJ(πθ), assuming compatible linear-approx critic:
θJ(πθ) =
S
ρπ
(s)
A
π(s, a; θ) · (SC(s, a; θ) · SC(s, a; θ)T
· w) · da · ds
= Es∼ρπ,a∼π[SC(s, a; θ) · SC(s, a; θ)T
] · w
= FIMρπ,π(θ) · w
where FIMρπ,π(θ) is the Fisher Information Matrix w.r.t. s ∼ ρπ, a ∼ π.
Ashwin Rao Policy Gradient Theorem September 1, 2018 22 / 23](https://image.slidesharecdn.com/policygradient-180901184813/85/Policy-Gradient-Theorem-22-320.jpg)


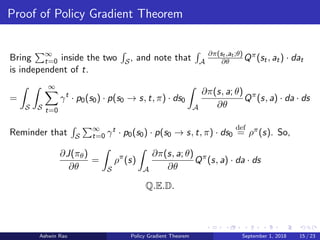
The document summarizes the policy gradient theorem, which provides a way to perform policy improvement in reinforcement learning using gradient ascent on the expected returns with respect to the policy parameters. It begins by motivating policy gradients as a way to do policy improvement when the action space is large or continuous. It then defines the necessary notation, expected returns objective function, and discounted state visitation measure. The main part of the document proves the policy gradient theorem, which expresses the policy gradient as an expectation over the discounted state visitation measure and action-value function. It notes that in practice the action-value function must be estimated, and proves the compatible function approximation theorem, which ensures the policy gradient is computed correctly when using an estimated action-value
















![Q-Learning Algorithm: A Concise Introduction [Shakeeb A.]](https://cdn.slidesharecdn.com/ss_thumbnails/q-learningshakeebabuzarmustafasneha-200921155609-thumbnail.jpg?width=640&height=640&fit=bounds)























































![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)



