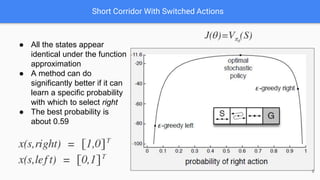
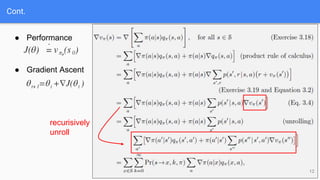
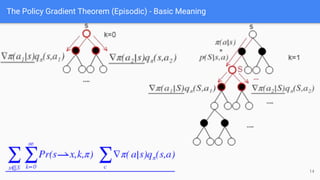
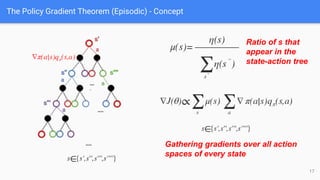
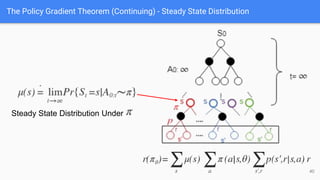
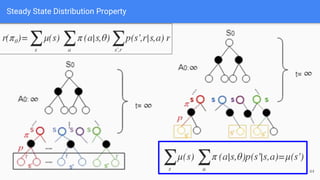
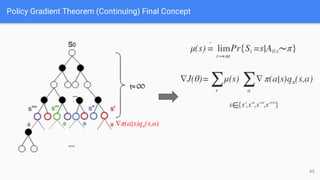
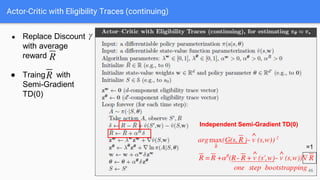
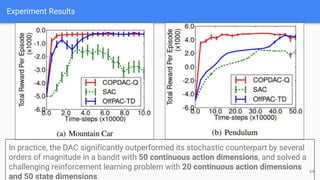
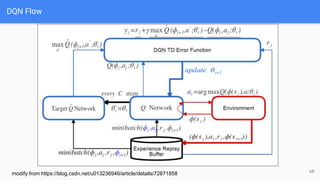
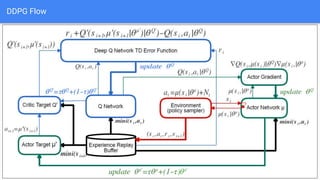
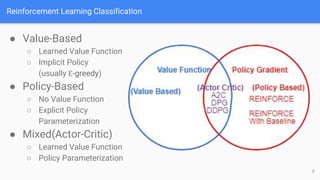
The document provides an extensive overview of policy gradient methods in reinforcement learning, detailing various algorithms such as REINFORCE, actor-critic methods, and deterministic policy gradient. It emphasizes the advantages of policy gradients over value-based methods, particularly in their ability to handle continuous action spaces and specific action probabilities. Key topics include the policy gradient theorem, exploration strategies, and the integration of state-value functions to improve learning efficiency and reduce variance.


![Agenda
Reinforcement Learning:An Introduction
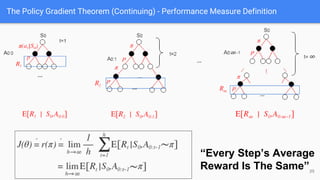
● Policy Gradinet Theorem
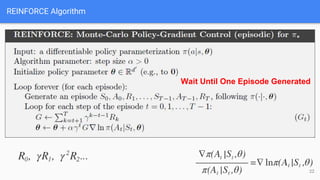
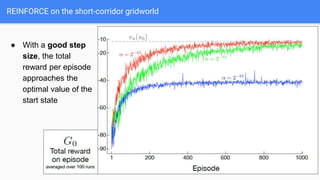
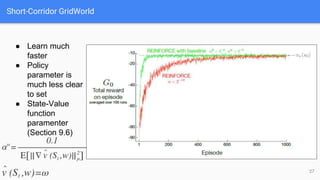
● REINFORCE: Monte -Carlo Policy Gradient
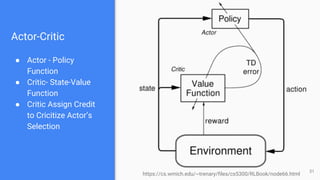
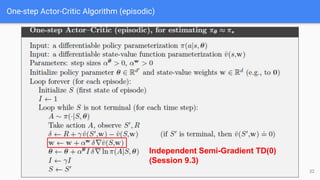
● One-Step Actor Critic
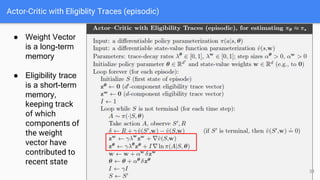
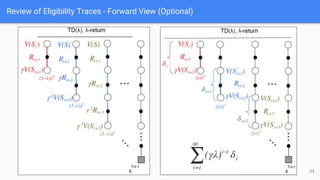
● Actor Critic with Eligibility Trace (Eposodic and Continuing Case)
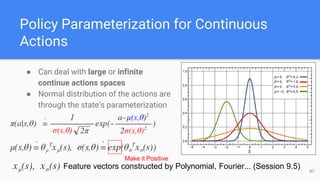
● Policy Parameterization for Continuous Actions
DeepMind (Richard Sutton、David Silver)
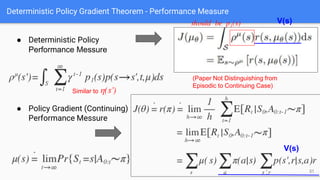
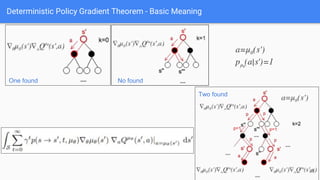
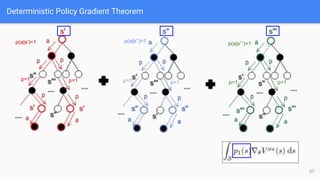
● Determinstic Policy Gradient (DPG(2014)、DDPG(2016)、MADDPG(2018)[part 2])
● Distributed Proximal Policy Optimization(DPPO 2017.07) [part 2]
OpenAI (Pieter Abbeel、John Schulman)
● Trust Region Policy Gradient (TRPO(2016)) [part 2]
● Proximal Policy Optimization (PPO(2017.07)) [part 2]
2](https://image.slidesharecdn.com/reinforcementlearning-policygradientpart1-180829082458/85/Reinforcement-learning-policy-gradient-part-1-2-320.jpg)
![Policy Gradient Method
Goal:
Performance Messure:
Optimization:Gradient Ascent
[Actor-Critic Method]:Learn approximation to both policy and value
function
4](https://image.slidesharecdn.com/reinforcementlearning-policygradientpart1-180829082458/85/Reinforcement-learning-policy-gradient-part-1-4-320.jpg)