Download as PDF, PPTX


![Motivation for understanding Value Function Geometry
Helps us better understand transformations of Value Functions (VFs)
Across the various DP and RL algorithms
Particularly helps when VFs are approximated, esp. with linear approx
Provides insights into stability and convergence
Particularly when dealing with the “Deadly Triad”
Deadly Triad := [Bootstrapping, Func Approx, Off-Policy]
Leads us to Gradient TD
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 3 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-3-320.jpg)
![Notation
Assume state space S consists of n states: {s1, s2, . . . , sn}
Action space A consisting of finite number of actions
This exposition extends easily to continuous state/action spaces too
This exposition is for a fixed (often stochastic) policy denoted π(a|s)
VF for a policy π is denoted as vπ : S → R
m feature functions φ1, φ2, . . . , φm : S → R
Feature vector for a state s ∈ S denoted as φ(s) ∈ Rm
For linear function approximation of VF with weights
w = (w1, w2, . . . , wm), VF vw : S → R is defined as:
vw(s) = wT
· φ(s) =
m
j=1
wj · φj (s) for any s ∈ S
µπ : S → [0, 1] denotes the states’ probability distribution under π
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 4 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-4-320.jpg)
![VF Vector Space and VF Linear Approximations
n-dimensional space, with each dim corresponding to a state in S
A vector in this space is a specific VF (typically denoted v): S → R
Wach dimension’s coordinate is the VF for that dimension’s state
Coordinates of vector vπ for policy π are: [vπ(s1), vπ(s2), . . . , vπ(sn)]
Consider m vectors where jth vector is: [φj (s1), φj (s2), . . . , φj (sn)]
These m vectors are the m columns of n × m matrix Φ = [φj (si )]
Their span represents an m-dim subspace within this n-dim space
Spanned by the set of all w = [w1, w2, . . . , wm] ∈ Rm
Vector vw = Φ · w in this subspace has coordinates
[vw(s1), vw(s2), . . . , vw(sn)]
Vector vw is fully specified by w (so we often say w to mean vw)
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 5 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-5-320.jpg)
![Some more notation
Denote r(s, a) as the Expected Reward upon action a in state s
Denote p(s, s , a) as the probability of transition s → s upon action a
Define
R(s) =
a∈A
π(a|s) · r(s, a)
P(s, s ) =
a∈A
π(a|s) · p(s, s , a)
Denote R as the vector [R(s1), R(s2), . . . , R(sn)]
Denote P as the matrix [P(si , si )], 1 ≤ i, i ≤ n
Denote γ as the MDP discount factor
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 6 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-6-320.jpg)



![4 VF vectors of interest in the Φ subspace (continued)
3 Projected Bellman Error (PBE)-minimizing:
wPBE = arg minw d((ΠΦ · Bπ)vw, vw)
The minimum is 0, i.e., Φ · wPBE is the fixed point of operator ΠΦ · Bπ
This fixed point is the solution to a linear system (covered later)
Alternatively, if we start with an arbitrary vw and repeatedly apply
ΠΦ · Bπ, we will converge to Φ · wPBE
This is a DP-like process with approximation - repeatedly thrown out of
the Φ subspace (applying Bellman operator Bπ), followed by landing
back in the Φ subspace (applying Projection operator ΠΦ)
In model-free setting, Gradient TD Algorithms (covered later)
4 Temporal Difference Error (TDE)-minimizing:
wTDE = arg minw Eπ[δ2]
δ is the TD error
Minimizes the expected square of the TD error when following policy π
Naive Residual Gradient TD Algorithm (covered later)
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 10 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-10-320.jpg)
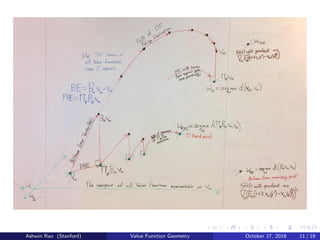




![Residual Gradient Algorithm to solve for wBE
We defined wBE as the vector in the Φ subspace that minimizes BE
But BE for a state is the expected TD error in that state
So we want to do SGD with gradient of square of expected TD error
∆w = −
1
2
α · w (Eπ[δ])2
= −α · Eπ[r + γ · wT
· φ(s ) − wT
· φ(s)] · w Eπ[δ]
= α · (Eπ[r + γ · wT
· φ(s )] − wT
· φ(s)) · (φ(s) − γ · Eπ[φ(s )])
This is called the Residual Gradient algorithm
Requires two independent samples of s transitioning from s
In that case, converges to wBE robustly (even for non-linear approx)
But it is slow, and doesn’t converge to a desirable place
Cannot learn if we can only access features, and not underlying states
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 16 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-16-320.jpg)

![TDC Algorithm to solve for wPBE
We derive the TDC Algorithm based on wL(w)
wL(w) = 2 · ( w(ΦT
· D · δw)T
) · (ΦT
· D · Φ)−1
· (ΦT
· D · δw)
Now we express each of these 3 terms as expectations of model-free
transitions s
µ
−→ (r, s ), denoting r + γ · wT · φ(s ) − wT · φ(s) as δ
ΦT · D · δw = E[δ · φ(s)]
w(ΦT · D · δw)T = w(E[δ · φ(s)])T = E[( wδ) · φ(s)T ] =
E[(γ · φ(s ) − φ(s)) · φ(s)T ]
ΦT · D · Φ = E[φ(s) · φ(s)T ]
Substituting, we get:
wL(w) = 2 · E[(γ · φ(s ) − φ(s)) · φ(s)T
] · E[φ(s) · φ(s)T
]−1
· E[δ · φ(s)]
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 18 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-18-320.jpg)
![Weight Updates of TDC Algorithm
∆w = −
1
2
α · wL(w)
= α · E[(φ(s) − γ · φ(s )) · φ(s)T
] · E[φ(s) · φ(s)T
]−1
· E[δ · φ(s)]
= α · (E[φ(s) · φ(s)T
] − γ · E[φ(s ) · φ(s)T
]) · E[φ(s) · φ(s)T
]−1
· E[δ · φ(s)]
= α · (E[δ · φ(s)] − γ · E[φ(s ) · φ(s)T
] · E[φ(s) · φ(s)T
]−1
· E[δ · φ(s)])
= α · (E[δ · φ(s)] − γ · E[φ(s ) · φ(s)T
] · θ)
where θ = E[φ(s) · φ(s)T ]−1 · E[δ · φ(s)] is the solution to a weighted
least-squares linear regression of Bπv − v against Φ, with weights as µπ.
Cascade Learning: Update both w and θ (θ converging faster)
∆w = α · δ · φ(s) − α · γ · φ(s ) · (θT · φ(s))
∆θ = β · (δ − θT · φ(s)) · φ(s)
Note: θT · φ(s) operates as estimate of TD error δ for current state s
Ashwin Rao (Stanford) Value Function Geometry October 27, 2018 19 / 19](https://image.slidesharecdn.com/valuefunctiongeometry-181028043446/85/Value-Function-Geometry-and-Gradient-TD-19-320.jpg)

The document discusses the geometry of value functions in reinforcement learning, focusing on how understanding this geometry enhances the evaluation and transformation of value functions across various algorithms. It covers concepts like vector space representations, projection operators, and solutions to linear systems relevant in model-free learning contexts. Additionally, it presents algorithms such as gradient temporal difference methods and their applications in approximating value functions.























































































