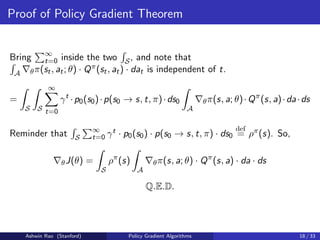
The document provides an overview of policy gradient algorithms. It begins by motivating policy gradients as a way to perform policy improvement with gradient ascent instead of argmax when the action space is large or continuous. It then defines key concepts like the policy gradient theorem, which shows the gradient of expected returns with respect to the policy parameters can be estimated by sampling simulation paths. It presents the policy gradient algorithm REINFORCE, which uses Monte Carlo returns to estimate the action-value function and perform policy gradient ascent updates. It also discusses canonical policy function approximations like the softmax policy for finite actions and Gaussian policy for continuous actions.






![Notation
Discount Factor γ
Assume episodic with 0 ≤ γ ≤ 1 or non-episodic with 0 ≤ γ 1
States st ∈ S, Actions at ∈ A, Rewards rt ∈ R, ∀t ∈ {0, 1, 2, . . .}
State Transition Probabilities Pa
s,s0 = Pr(st+1 = s0|st = s, at = a)
Expected Rewards Ra
s = E[rt|st = s, at = a]
Initial State Probability Distribution p0 : S → [0, 1]
Policy Func Approx π(s, a; θ) = Pr(at = a|st = s, θ), θ ∈ Rk
PG coverage will be quite similar for non-discounted non-episodic, by
considering average-reward objective (so we won’t cover it)
Ashwin Rao (Stanford) Policy Gradient Algorithms 7 / 33](https://image.slidesharecdn.com/rlunit5part1-231222060534-8f75379b/85/RL-unit-5-part-1-pdf-7-320.jpg)
![“Expected Returns” Objective
Now we formalize the “Expected Returns” Objective J(θ)
J(θ) = Eπ[
∞
X
t=0
γt
rt]
Value Function V π(s) and Action Value function Qπ(s, a) defined as:
V π
(s) = Eπ[
∞
X
k=t
γk−t
rk|st = s], ∀t ∈ {0, 1, 2, . . .}
Qπ
(s, a) = Eπ[
∞
X
k=t
γk−t
rk|st = s, at = a], ∀t ∈ {0, 1, 2, . . .}
Advantage Function Aπ
(s, a) = Qπ
(s, a) − V π
(s)
Also, p(s → s0, t, π) will be a key function for us - it denotes the
probability of going from state s to s0 in t steps by following policy π
Ashwin Rao (Stanford) Policy Gradient Algorithms 8 / 33](https://image.slidesharecdn.com/rlunit5part1-231222060534-8f75379b/85/RL-unit-5-part-1-pdf-8-320.jpg)
![Discounted-Aggregate State-Visitation Measure
J(θ) = Eπ[
∞
X
t=0
γt
rt] =
∞
X
t=0
γt
Eπ[rt]
=
∞
X
t=0
γt
Z
S
(
Z
S
p0(s0) · p(s0 → s, t, π) · ds0)
Z
A
π(s, a; θ) · Ra
s · da · ds
=
Z
S
(
Z
S
∞
X
t=0
γt
· p0(s0) · p(s0 → s, t, π) · ds0)
Z
A
π(s, a; θ) · Ra
s · da · ds
Definition
J(θ) =
Z
S
ρπ
(s)
Z
A
π(s, a; θ) · Ra
s · da · ds
where ρπ(s) =
R
S
P∞
t=0 γt · p0(s0) · p(s0 → s, t, π) · ds0 is the key function
(for PG) we’ll refer to as Discounted-Aggregate State-Visitation Measure.
Ashwin Rao (Stanford) Policy Gradient Algorithms 9 / 33](https://image.slidesharecdn.com/rlunit5part1-231222060534-8f75379b/85/RL-unit-5-part-1-pdf-9-320.jpg)

![Canonical π(s, a; θ) for finite action spaces
For finite action spaces, we often use Softmax Policy
θ is an n-vector (θ1, . . . , θn)
Features vector φ(s, a) = (φ1(s, a), . . . , φn(s, a)) for all s ∈ S, a ∈ A
Weight actions using linear combinations of features: θT · φ(s, a)
Action probabilities proportional to exponentiated weights:
π(s, a; θ) =
eθT ·φ(s,a)
P
b eθT ·φ(s,b)
for all s ∈ S, a ∈ A
The score function is:
∇θ log π(s, a; θ) = φ(s, a)−
X
b
π(s, b; θ)·φ(s, b) = φ(s, a)−Eπ[φ(s, ·)]
Ashwin Rao (Stanford) Policy Gradient Algorithms 11 / 33](https://image.slidesharecdn.com/rlunit5part1-231222060534-8f75379b/85/RL-unit-5-part-1-pdf-11-320.jpg)











![TD Error as estimate of Advantage Function
Consider TD error δπ for the true Value Function V π(s)
δπ
= r + γV π
(s0
) − V π
(s)
δπ is an unbiased estimate of Advantage function Aπ(s, a)
Eπ[δπ
|s, a] = Eπ[r+γV π
(s0
)|s, a]−V π
(s) = Qπ
(s, a)−V π
(s) = Aπ
(s, a)
So we can write Policy Gradient in terms of Eπ[δπ|s, a]
∇θJ(θ) =
Z
S
ρπ
(s)
Z
A
∇θπ(s, a; θ) · Eπ[δπ
|s, a] · da · ds
In practice, we can use func approx for TD error (and sample):
δ(s, r, s0
; v) = r + γV (s0
; v) − V (s; v)
This approach requires only one set of critic parameters v
Ashwin Rao (Stanford) Policy Gradient Algorithms 24 / 33](https://image.slidesharecdn.com/rlunit5part1-231222060534-8f75379b/85/RL-unit-5-part-1-pdf-24-320.jpg)







![Fisher Information Matrix
Denoting [∂ log π(s,a;θ)
∂θi
], i = 1, . . . , n as the score column vector SC(s, a; θ)
and assuming compatible linear-approx critic:
∇θJ(θ) =
Z
S
ρπ
(s)
Z
A
π(s, a; θ) · (SC(s, a; θ) · SC(s, a; θ)T
· w) · da · ds
= Es∼ρπ,a∼π[SC(s, a; θ) · SC(s, a; θ)T
] · w
= FIMρπ,π(θ) · w
where FIMρπ,π(θ) is the Fisher Information Matrix w.r.t. s ∼ ρπ, a ∼ π.
Ashwin Rao (Stanford) Policy Gradient Algorithms 32 / 33](https://image.slidesharecdn.com/rlunit5part1-231222060534-8f75379b/85/RL-unit-5-part-1-pdf-32-320.jpg)
















































