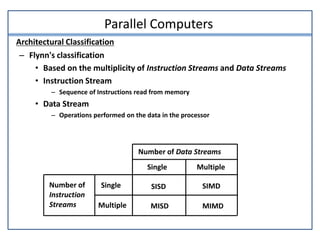
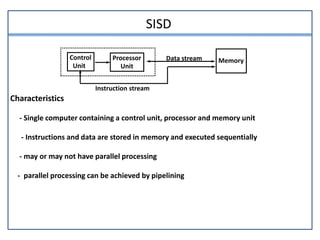
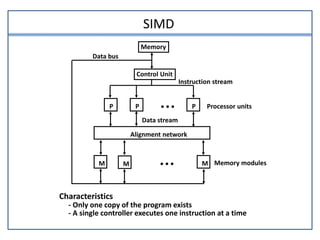
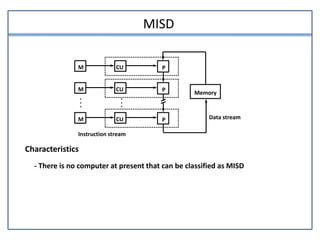
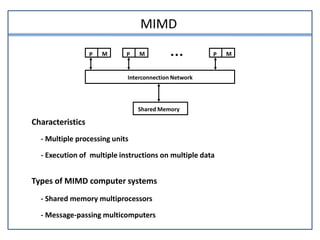
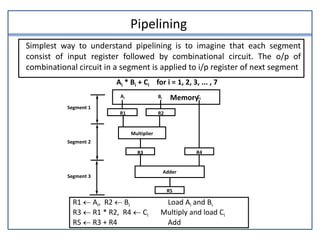
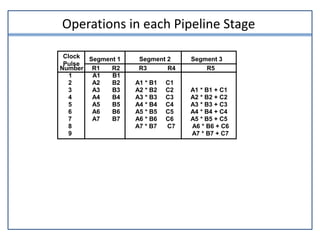
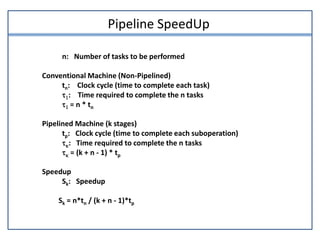
This document discusses parallel processing and pipelining. It describes different levels and types of parallel processing including job level, task level, inter-instruction level, and intra-instruction level parallelism. It also covers Flynn's classification of parallel computers as SISD, SIMD, MISD, and MIMD based on the number of instruction and data streams. Pipelining is defined as decomposing a process into sub-operations that execute concurrently. The key benefits of pipelining are that multiple computations can progress simultaneously through different pipeline stages.