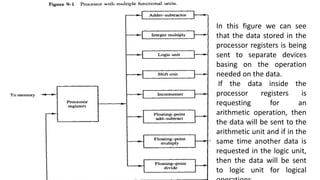
- Parallel processing systems can perform concurrent data processing using multiple ALUs and processors to achieve faster execution times. The goal is to increase throughput by processing more data within a given time interval.
- Parallelism can occur in the instruction stream, data stream, or both. Flynn's taxonomy classifies computers based on whether they have single or multiple instruction/data streams.
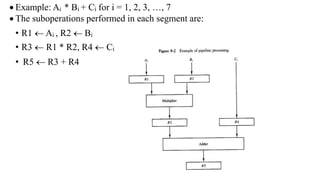
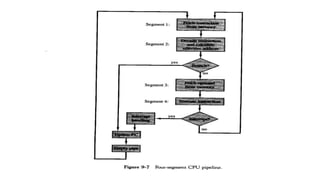
- Pipeline processing breaks operations into sequential sub-operations that can execute concurrently in dedicated pipeline stages. It is efficient for repetitive tasks and can achieve speedups close to the number of stages.