The document discusses the evolution of operating systems from mainframe to desktop and distributed systems. It describes [1] how mainframe systems used batch processing and multiprogramming to improve CPU utilization, [2] how time-sharing systems enabled interactive use by rapidly switching between users, [3] how personal computers led to single-user desktop systems like MS-DOS and Windows, and [4] how distributed systems employ client-server and multiprocessing architectures to share resources over networks.








































![state. If it will, the resources are allocated; otherwise, the process must wait until some
other releases enough resources.
Safety Algorithm
The algorithm for finding out the whether or not a system is in a safe state can be
described as follows:
1. Let work and Finish be vectors of length m and n, respectively. Initialize
Work: =Available and Finish[i]:=false for i=1,2,3,….., n.
2. Find an I such that both
a. Finish[i]=false
b. Need i Work.
If no such I exists, go to step 4.
3. Work: =Work + Allocation;
Finish[i]: =true
Go to step 2.
4. If Finish[i] = true for all I, then the system is in a safe state.
This algorithm may require an order of m x n operations to decide whether a state is safe.
Resource-Request Algorithm
Let Request i be the request vector for process Pi. If requesti[j] = k, then process pi wants
k instances of resource type Rj. When a request for resources is made by process Pi, the
following actions are taken:
1. If Requesti < Needi, go to step 2. Otherwise , raise an error condition, since the
process has exceeded its maximum claim.
2. If Requesti< Available, go to step 3. Otherwise, Pi must wait, since the resources
are not available.
3. Have the system pretend to have allocated the requested resources to process Pi
by modifying the state as follows:
Available: = Available – Requesti;
Allocationi :=Allocationi + Requesti;
Needi := Needi – Requesti;
If the resulting resource-allocation state is safe, the transaction is completed and process
Pi is allocated its resources. However, if the new state is unsafe, then Pi must wait for
Request and the old resource-allocation state is restored.
41](https://image.slidesharecdn.com/operatingsystemsprint-1282136354044-phpapp02/85/Operating-Systems-41-320.jpg)




![while (turn !=j);
critical section
turn = j;
remainder section
} while (1);
Fig. The structure of process Pi in algorithm 1.
The two processes P0, P1 share the common integer variable turn = 0 or 1. If turn == i,
then process Pi is allowed to execute in its critical section. The structure of Pi is shown in
fig. This solution ensures that only one process at a time can be in its critical section. But
it does not satisfy the progress requirement.
II. Algorithm 2
do{
flag[i] = true;
while (flag[j]);
Critical section
flag[i] = false;
Remainder section
{ while(1);
The remedy to algorithm 1 is we can replace the variable turn with the following array:
Boolean flag[2];
The elements of the array are initialized to false. If flag[i] is true, this value indicates that
Pi is ready to enter the critical section. The structure of Pi is shown in figure.
In this algorithm, process Pi first sets flag[i] to be true, signaling that it is ready to
enter its critical section. Then Pi checks to verify that process Pj is not also ready to enter
its critical section. If Pj were ready, then Pi would wait until Pj no need to be in critical
section. Then Pi will enter critical section and on exiting the critical section, Pi wouls set
flag[i] to be false, allowing the other process to enter its critical section.
In this mutual exclusion is satisfied. But progress is not satisfied. Consider the
following execution:
To: Po sets flag[0] = true
T1: P1 sets flag[1] = true
During time To the process Po is executed and a timing interrupt occurs after To is
executed, and the CPU switches from one process to another.
III. Algorithm 3:
46](https://image.slidesharecdn.com/operatingsystemsprint-1282136354044-phpapp02/85/Operating-Systems-46-320.jpg)
![By combining the key ideas of algorithm 1 and 2 we obtain the correct solution to the
critical section problem where all the three requirements is met.
The processes share the two variables:
Boolean flag[2];
int turn;
Fig. The structure of process Pi in algorithm 3.
do{
flag[i] = true;
turn = j;
while (flag[j] && turn == j);
critical section
flag[i] = false;
remainder section
} while (1);
Initially flag[o] = flag[1] = false, and the value of turn = 0 or 1.
To enter the critical section, process Pi first sets flag[i]=true and sets turn = j value(1). So
that the pother process wishes to enter the critical section can enter. If both process try to
enter at the same time then value of turn decides which of the two process to enter.
To proves solution is correct show:
1. Mutual exclusion is preserved
2. The progress requirement is satisfied
3. The bounded waiting requirement is met.
To prove property 1:
Pi enters its critical section only is either flag[j] ==false or turn==i. At the time,
flag[j]==true, and turn ==j, until this condition persist as long as Pj is in its critical
section, the result is mutual exclusion is followed.
To prove property 2:
The Process Pi can be prevented from entering the critical section when the condition
flag[j] ==true and turn==j;
If Pj is not ready to enter the critical section , then flag[j] == false and Pi an enter
the critical section.
If Pj has set flag[j] ==true and is and executing in the while loop then either
turn==I or turn==j; If turn==I then Pi will enter the critical section. If turn==j, then Pj
47](https://image.slidesharecdn.com/operatingsystemsprint-1282136354044-phpapp02/85/Operating-Systems-47-320.jpg)
![will enter the critical section. When Pj exists the critical section it will reset the
flag[j]==false allowing Pi to enter the critical section.
If Pj resets flag[j] == true then it must also set turn ==i. Thus, since Pi does not
change the value of the variable turn while executing the while statement, Pi will enter
the critical section(progress) which after at most one entry by Pj(bounded waiting).
CLASSIC PROBLEMS OF SYNCHRONIZATION
I. Bounded Buffer Problem:
This illustrates the concept of cooperating processes, consider the producer and
consumer problem. A producer process produces information that is consumed by a
consumer. Example, a print program produces characters that is consumed by the printer
device. We must have available buffer of items that can be filled by the producer and
emptied by the consumer. A producer can produce one item while the consumer is
consuming another item. The producer and the consumer must be synchronized so that
the consumer does not try to consume n item that has not yet been produced.
In unbounded buffer produce4r consumer problems has no problem on the limit
on the size of the buffer. The consumer have to wait for new items but the producer can
always produce new items.
In bounded buffer producer consumer problem assumes fixed buffer size. In this
case if consumer must wait if the buffer is empty, and the producer must wait if the buffer
is full.
In the bounded buffer problem , we assume the pool consists of n buffers, each
capable of holding one item. The mutex semaphore provides mutual exclusion for access
to the buffer pool and is initialized to the value 1. The empty and full semaphores count
the number of empty and full buffers. The semaphore empty is initialized to value n, and
full initialized to the value 0.
Fig. The structure of the producer process.
do{
….
Produce an item
….
wait(empty);
wait(mutex);
….
add to buffer
….
signal(mutex);
signal(full);
}while(1);
48](https://image.slidesharecdn.com/operatingsystemsprint-1282136354044-phpapp02/85/Operating-Systems-48-320.jpg)

![…
reading is performed
…
wait(mutex);
readcount --;
if(readcount ==0)
signal(wrt);
signal(mutex);
Fig. The structure of a writer process:
wait(wrt);
…
writing is performed
…
signal(wrt);
III. The Dining-Philosophers Problem:
Consider five philosophers who spend their lives thinking and eating. The philosophers
share a common circular table surrounded by five chairs each for the five philosophers. In
the center of the table is a bowl of rice, and the table is laid with five single chopsticks.
When a philosopher thinks, she does not interact with her colleagues. From time to time,
a philosopher gets hungry and tries to pick up the two chopsticks that are closest to her. A
philosopher may pick up only one chopstick at a time. She cannot pick up a chopstick
that is already in the hand of a neighbor. When a hungry philosopher has both her
chopsticks at the same time, she eats without releasing her chopsticks. When she is
finished eating, she puts down both of her chopsticks and starts thinking again.
The dining philosopher is a simple representation of the need to allocate
several resources among several processes in a deadlock and starvation free manner. One
simple solution is to represent each chopstick by a semaphore. A philosopher tries to grab
the chopstick by executing a wait operation on that semaphore. She releases her
chopsticks by executing the signal operation on appropriate semaphores. Thus the shared
data are:
Semaphore chopstick[5];
Where all the elements of chopstick are initialized to 1.
do{
wait(chopstick[I]);
wait(chopstick[(I+1)%5];
…
eat
…
signal(chopstick[I]);
signal(chopstick[(I+1)]%5);
…
think
50](https://image.slidesharecdn.com/operatingsystemsprint-1282136354044-phpapp02/85/Operating-Systems-50-320.jpg)



















































































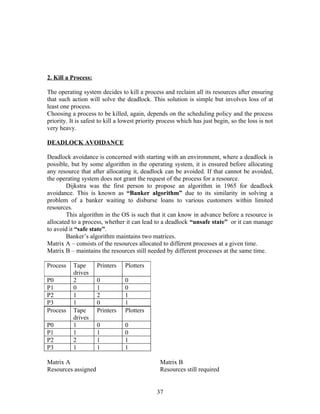
![OperatingSystem_UNIT_1_Introduction[1][1]](https://cdn.slidesharecdn.com/ss_thumbnails/osunit1introduction1-250820120255-fd2eb8b9-thumbnail.jpg?width=640&height=640&fit=bounds)










