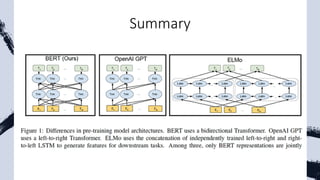
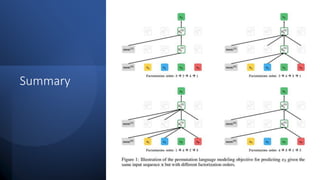
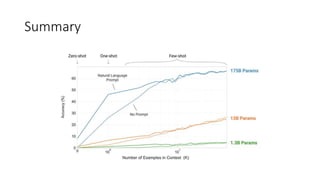
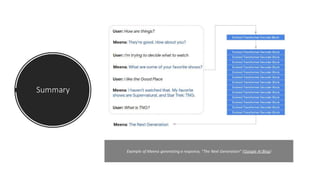
This document provides an overview of natural language processing (NLP) research trends presented at ACL 2020, including shifting away from large labeled datasets towards unsupervised and data augmentation techniques. It discusses the resurgence of retrieval models combined with language models, the focus on explainable NLP models, and reflections on current achievements and limitations in the field. Key papers on BERT and XLNet are summarized, outlining their main ideas and achievements in advancing the state-of-the-art on various NLP tasks.



















![What does the AI community think?
• The paper was accepted for oral presentation at NeurIPS 2019, the leading conference in
artificial intelligence.
• “The king is dead. Long live the king. BERT’s reign might be coming to an end. XLNet, a
new model by people from CMU and Google outperforms BERT on 20 tasks.” – Sebastian
Ruder, a research scientist at Deepmind.
• “XLNet will probably be an important tool for any NLP practitioner for a while…[it is] the
latest cutting-edge technique in NLP.” – Keita Kurita, Carnegie Mellon University.](https://image.slidesharecdn.com/nlpresearchpresentationfinal-210918032011/85/Nlp-research-presentation-21-320.jpg)































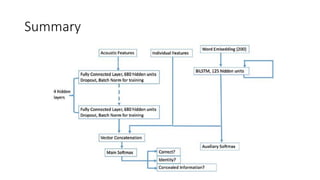






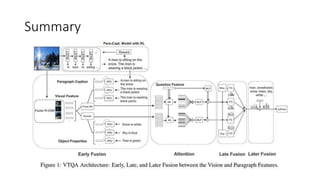































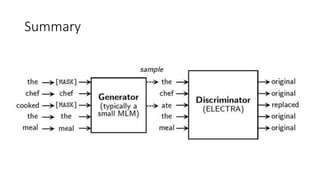
![15. ELECTRA: Pre-training Text Encoders as
Discriminators Rather Than Generators
• Original Abstract
• Masked language modeling(MLM) pre-trainingmethods such as BERT corrupt the input byreplacingsome tokens with
[MASK] and then train a model to reconstruct the original tokens.While they produce good results when transferred to
downstreamNLP tasks,theygenerallyrequire large amounts ofcompute to be effective.
• As an alternative,we propose a more sample-efficient pre-trainingtaskcalled replaced token detection.Instead of
maskingthe input,ourapproach corrupts it byreplacingsome tokens with plausible alternatives sampledfroma small
generator network.
• Then,instead oftraininga model that predicts the original identities ofthe corrupted tokens,we train a discriminative
model that predicts whether each token in the corrupted input was replaced bya generator sample or not.Thorough
experiments demonstrate this newpre-trainingtaskis more efficient than MLM because the task is defined overall
input tokens rather than just the small subset that was masked out.
• As a result,the contextual representations learned byourapproach substantiallyoutperform the ones learned byBERT
given the same model size, data,and compute.The gains are particularlystrongfor small models;for example, we train
a model on one GPU for 4 days that outperforms GPT (trained using30× more compute)on the GLUE naturallanguage
understandingbenchmark.Our approach also works well at scale, where it performs comparablyto RoBERTa and XLNet
while usingless than 1/4 of theircompute and outperforms them when usingthe same amount of compute.](https://image.slidesharecdn.com/nlpresearchpresentationfinal-210918032011/85/Nlp-research-presentation-100-320.jpg)
























































![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)














