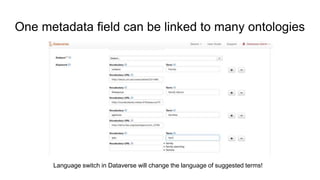
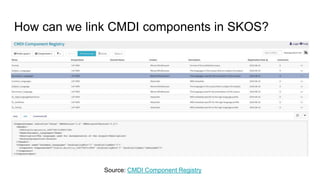
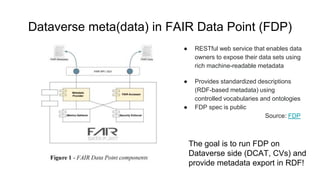
The document outlines the goals and functionalities of the DANS-KNAW initiative, focusing on enhancing interoperability in Dataverse through custom FAIR metadata schemas and linking metadata to controlled vocabularies and ontologies. It emphasizes the importance of standards, semantic relationships, and user-friendliness in metadata services for research communities. Additionally, it discusses technical and semantic interoperability, challenges in linked data integration, and the implementation of vocabulary based metadata structures to improve data accessibility and usability.










![What is semantics?
Semantics (from Ancient Greek: σημαντικός sēmantikós, "significant")[a][1] is the study of meaning. The term can be used to
refer to subfields of several distinct disciplines including linguistics, philosophy, and computer science.
Linguistics
In linguistics, semantics is the subfield that studies meaning. Semantics can address meaning at the levels of words,
phrases, sentences, or larger units of discourse. One of the crucial questions which unites different approaches to linguistic
semantics is that of the relationship between form and meaning.[2]
Computer science
In computer science, the term semantics refers to the meaning of language constructs, as opposed to their form (syntax).
According to Euzenat, semantics "provides the rules for interpreting the syntax which do not provide the meaning directly
but constrains the possible interpretations of what is declared."[14]
(from Wikipedia)](https://image.slidesharecdn.com/ontologiesanddataverse-201203165131/85/Ontologies-controlled-vocabularies-and-Dataverse-13-320.jpg)