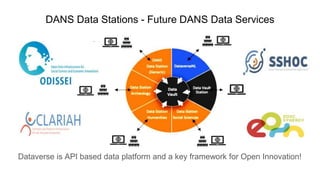
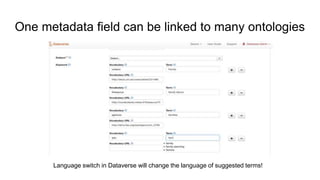
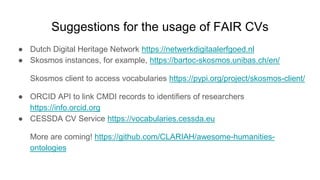
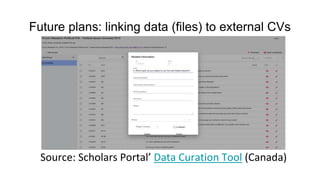
The document outlines upcoming features in the Dataverse release, particularly focusing on controlled vocabulary (CV) support, which enhances semantic interoperability and metadata management. Key improvements include a new JSON-LD API for dataset metadata handling and integration with external vocabularies like Wikidata and ORCID. Future plans involve making external CVs available out-of-the-box and simplifying their use in data management for providers.