Downloaded 26 times





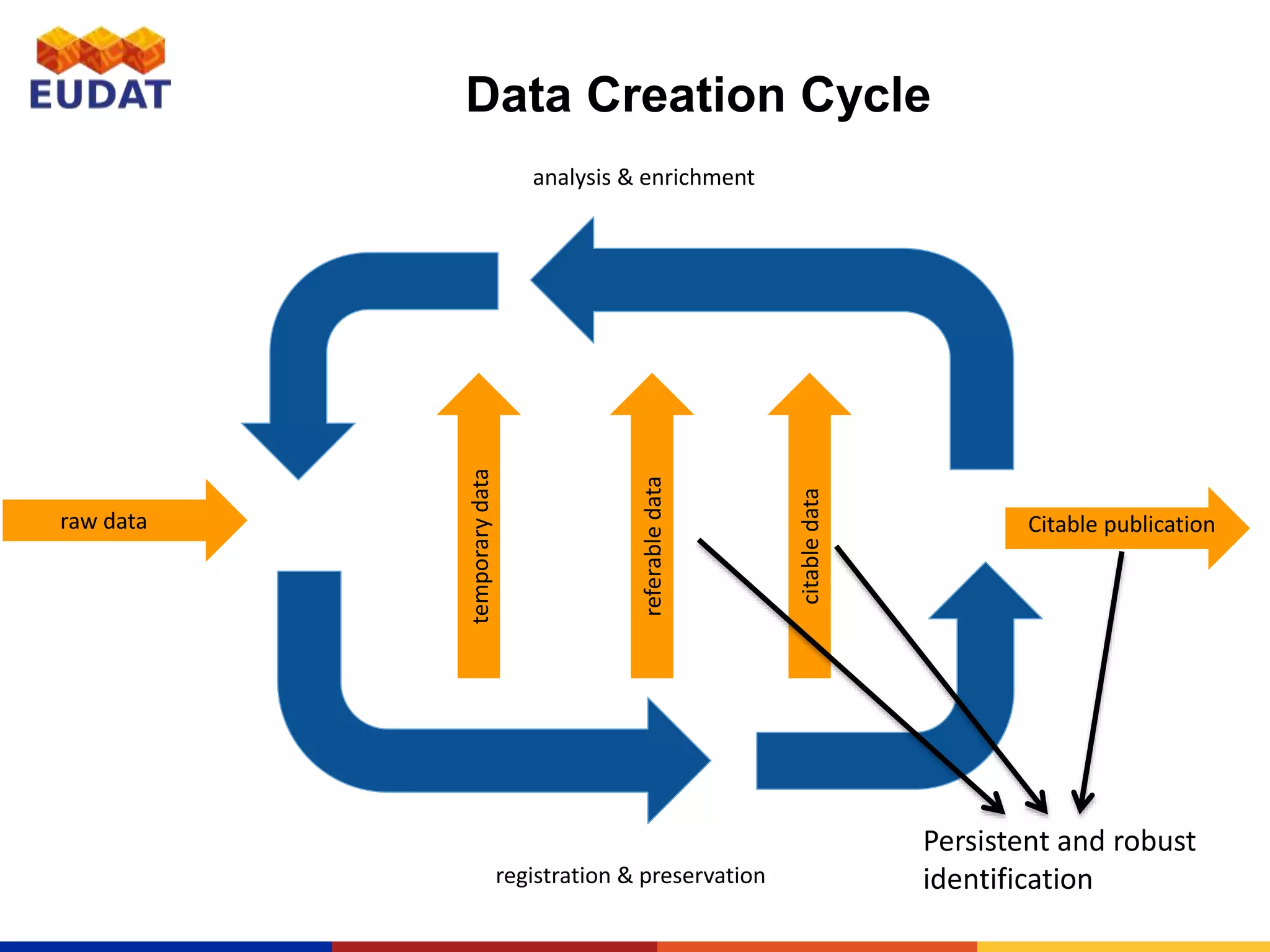

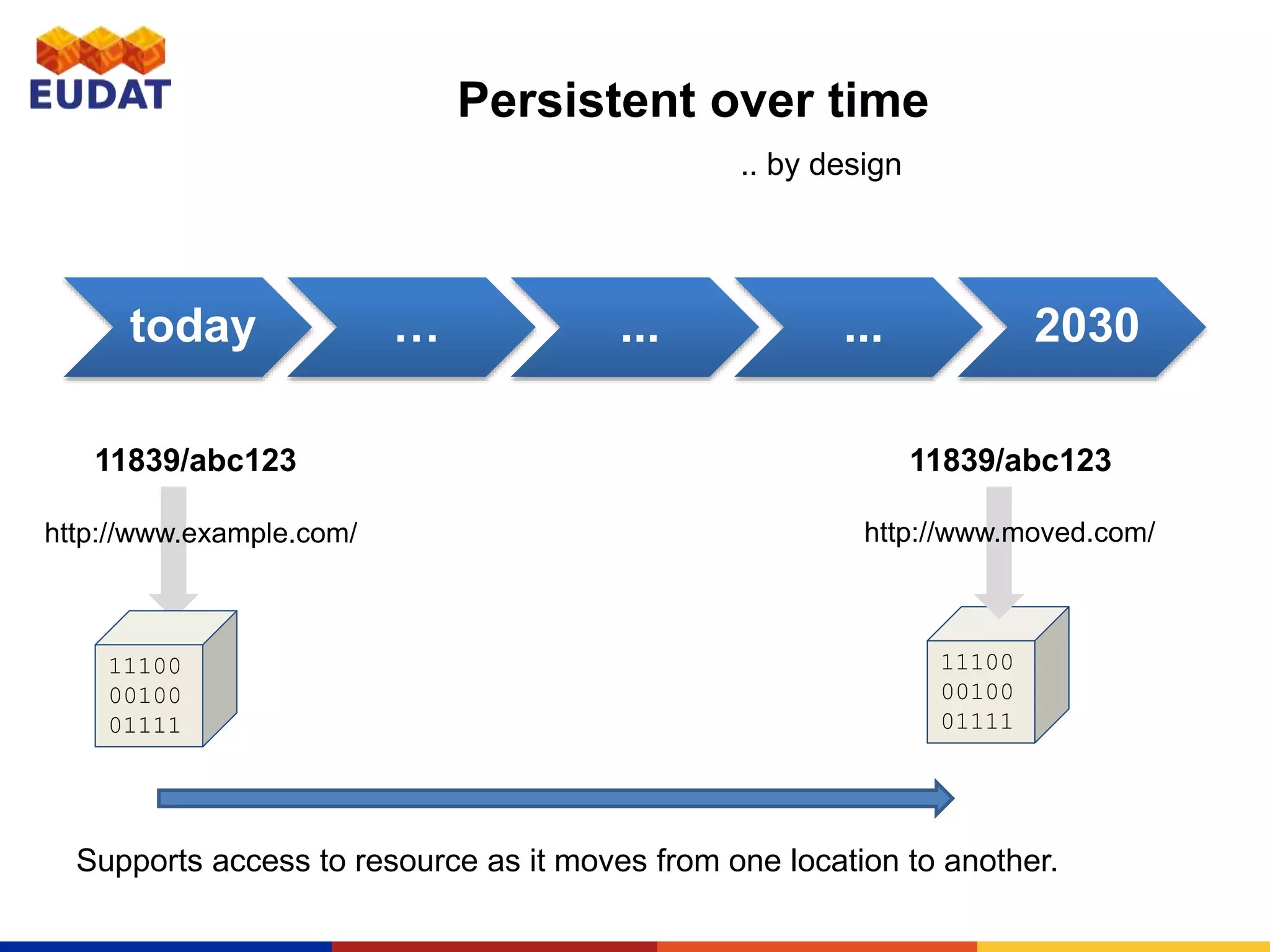

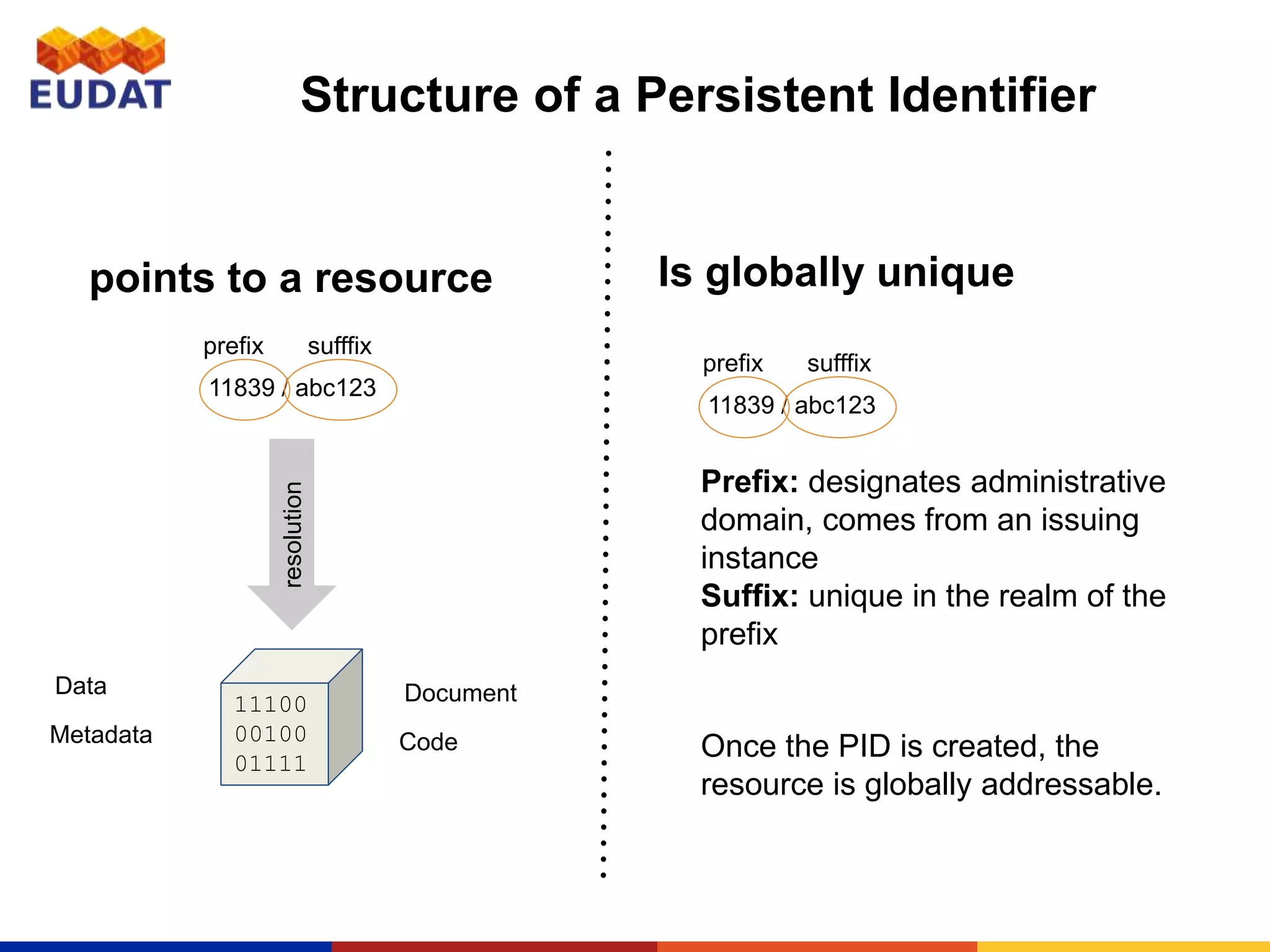
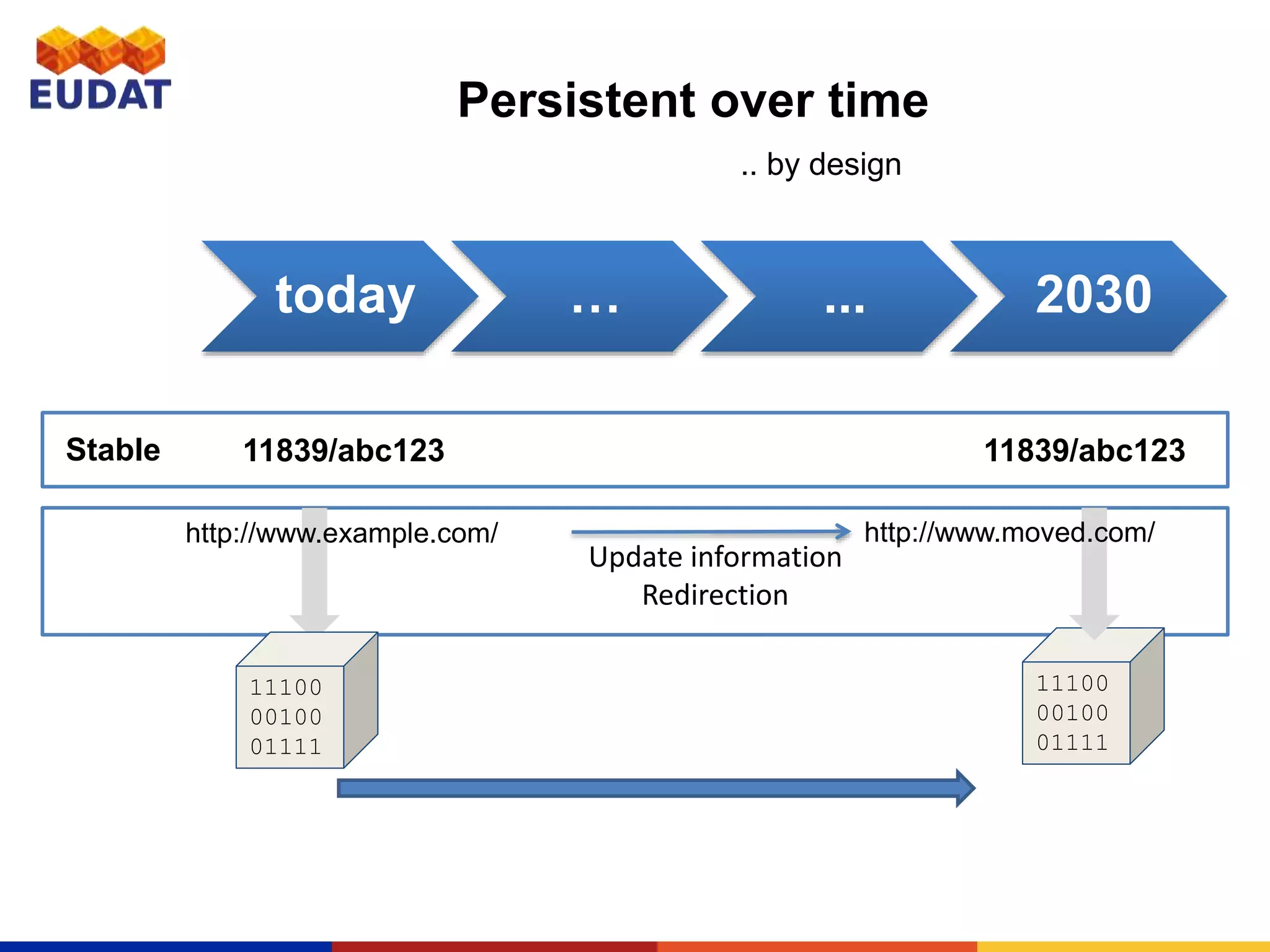












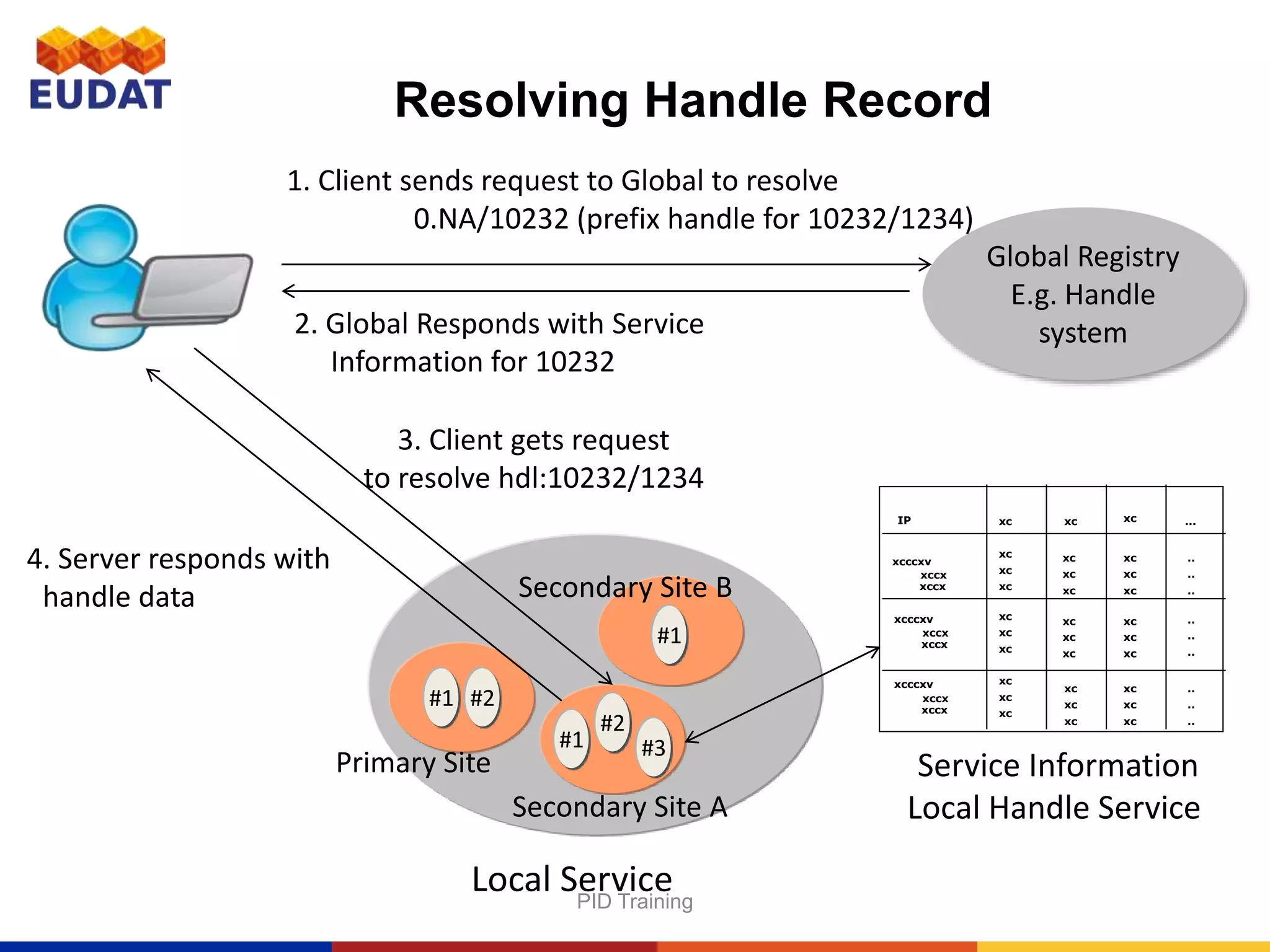



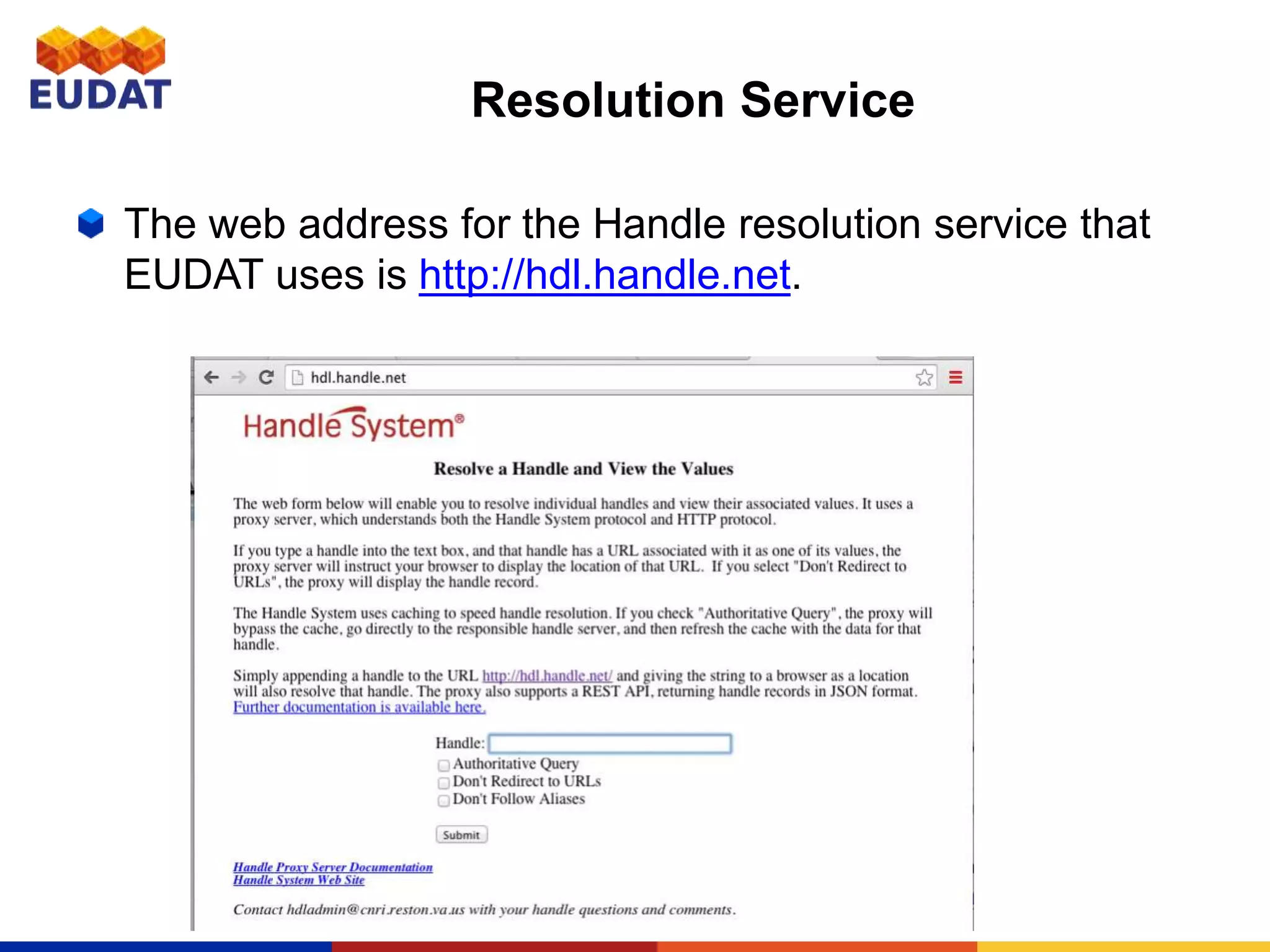













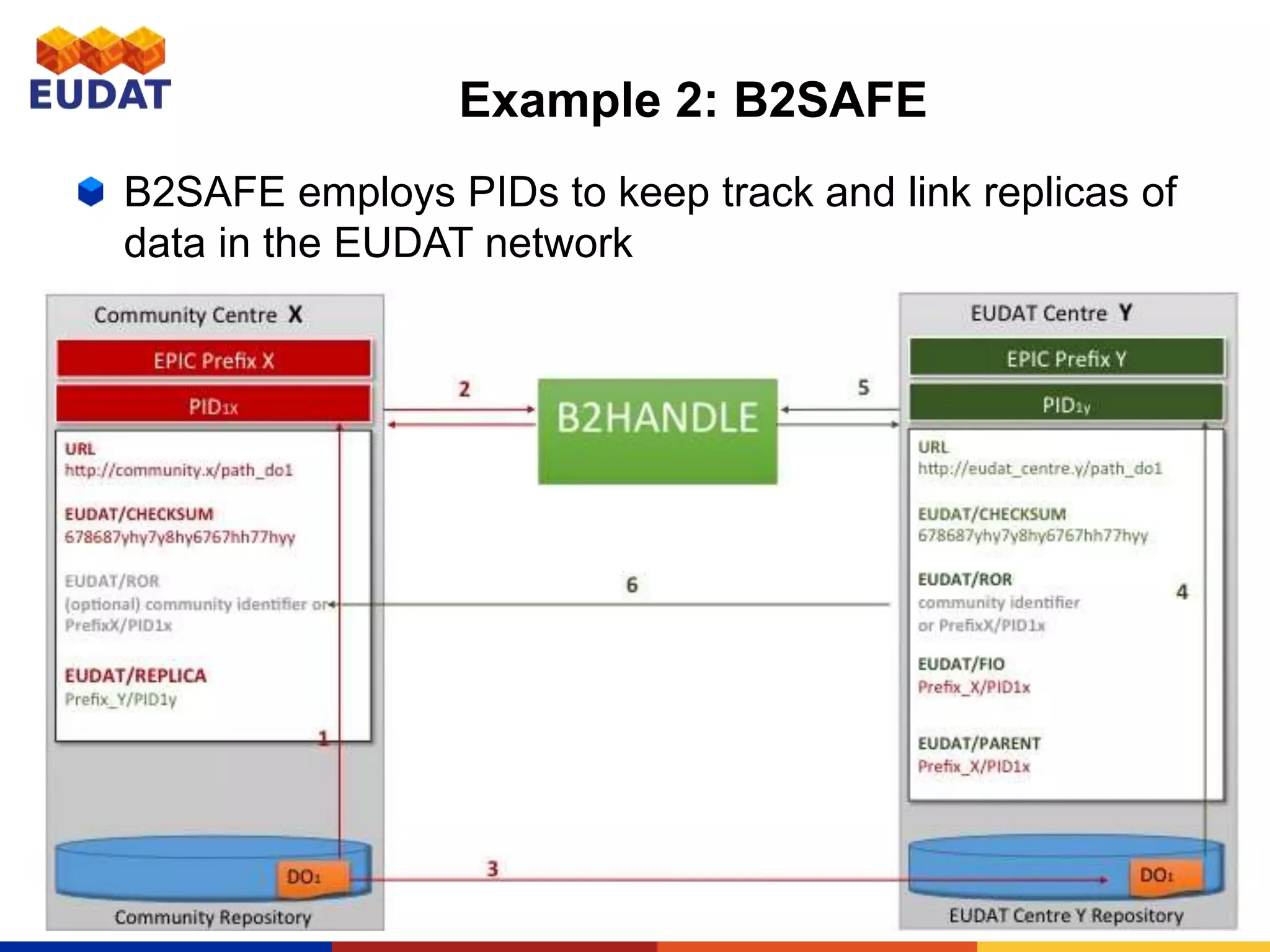





This document provides an introduction to persistent identifiers (PIDs) and their use in the EUDAT system. It defines PIDs as globally unique identifiers that can be used to persistently identify digital objects. The document discusses why PIDs are useful, describing problems with URLs like link rot. It then covers different PID systems like Handle and DOI, as well as EUDAT's use of Handle through the B2HANDLE service. The document also discusses PID policies, use cases, and the B2HANDLE Python library for programmatic PID management.










































































































