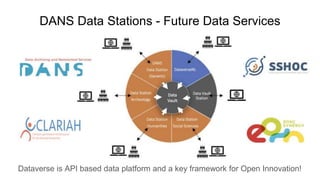
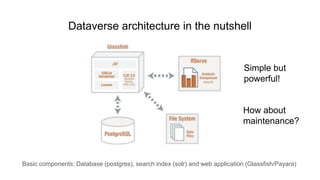
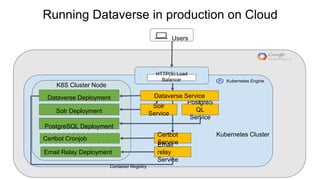
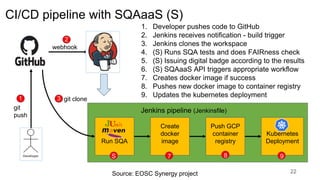
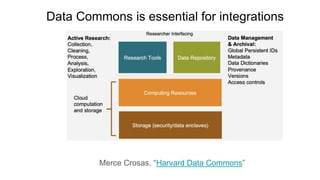
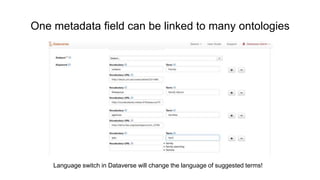
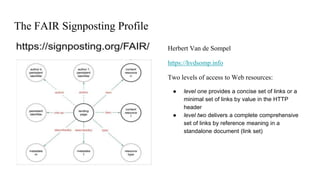
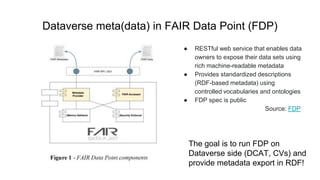
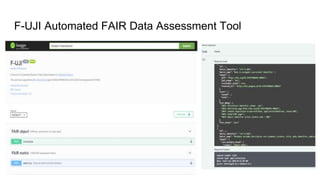
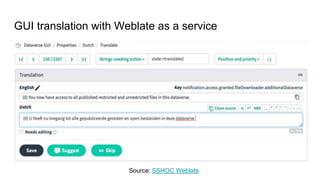
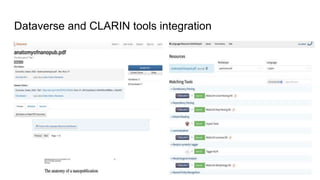
This document discusses the 5 year evolution of Dataverse, an open source data repository platform. It began as a tool for collaborative data curation and sharing within research teams. Over time, features were added like dataset version control, APIs, and integration with other systems. The document outlines challenges around maintenance and sustainability. It also covers efforts to improve Dataverse's interoperability, such as integrating metadata standards and controlled vocabularies, and making datasets FAIR compliant. The goal is to establish Dataverse as a core component of the European Open Science Cloud by improving areas like software quality, integration with tools, and standardization.