








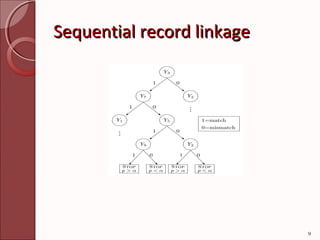











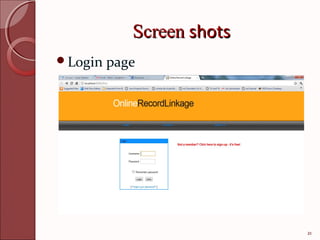
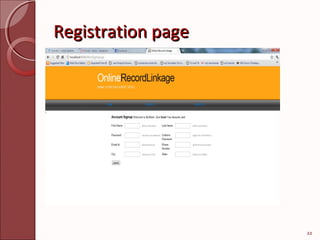
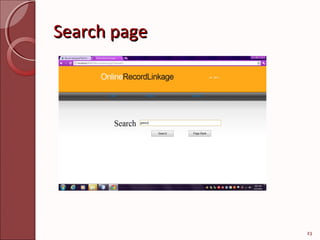





This document describes techniques for efficient online record linkage across heterogeneous databases. It discusses building a matching tree offline to reduce communication overhead during online linkage. The matching tree partitions records sequentially or concurrently to identify matching records between a local query and remote databases with minimal data transfer. Modules for handling multiple data sources, detecting overhead using the matching tree, and eliminating overhead are presented. Screenshots of sample login, registration, search and results pages are also included.






















































![[Evaldas Taroza - Master thesis] Schema Matching and Automatic Web Data Extra...](https://cdn.slidesharecdn.com/ss_thumbnails/5c1568bc-753d-44dc-88ac-dcf114742b88-150313043325-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



























