Downloaded 19 times








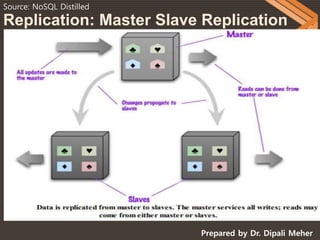






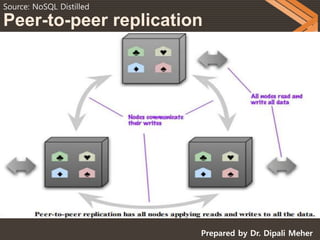









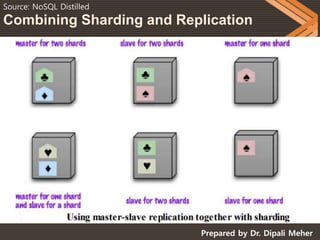




NOSQL databases can scale horizontally by distributing data across multiple servers through techniques like replication and sharding. Replication copies data across servers so each piece can be found in multiple places, while sharding partitions data and stores different parts on different servers. There are two main types of replication: master-slave, where one server is the master and others are slaves that copy from the master; and peer-to-peer, where all servers can accept writes. Sharding improves performance by ensuring frequently accessed data is on the same server. Replication provides redundancy and availability, while sharding allows scaling write and read operations.















































































