Downloaded 463 times



![Map Function
Has one document as input
Can emit all JSON-Types as key and value:
- Special Values: null, true, false
- Numbers: 1e-17, 1.5, 200
- Strings : “+“, “1“, “Ab“, “Audi“
- Arrays: [1], [1,2], [1,“Audi“,true]
- Objects: {“price“:1300,“sold“:true}
Results are ordered by key ( or revers)
(order with mixed types: see above)
In CouchDB: Each result has also the doc._id
{"total_rows":5,"offset":0,
"rows":[
{"id":"1","key":"Audi","value":1}, {"id":"
2","key":"Audi","value":1}, {"id":"3","key":
"VW","value":1}, {"id":"4","key":"VW","va
lue":1}, {"id":"5","key":"VW","value":1} ]}
Oliver Kurowski, @okurow](https://image.slidesharecdn.com/couchdbmapreduce-120614041014-phpapp01/85/CouchDB-Map-Reduce-5-320.jpg)




![Array-Key Map/Reduce Example
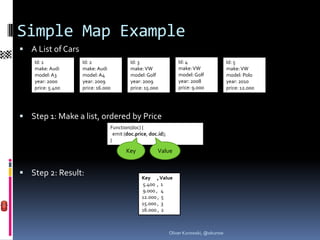
A List of cars (again)
Id: 1 Id: 2 Id: 3 Id: 4 Id: 5
make: Audi make: Audi make: VW make: VW make: VW
model: A3 model: A4 model: Golf model: Golf model: Polo
year: 2000 year: 2009 year: 2009 year: 2008 year: 2010
price: 5.400 price: 16.000 price: 15.000 price: 9.000 price: 12.000
Step 1: Make a map, with array as key
Function(doc) {
emit ([doc.make,doc.model,doc.year], 1);
}
Result (with group=true):
Key , Value
[Audi, A3, 2000] , 1
[Audi, A4, 2009] , 1
[VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1
[VW, Polo, 2010] , 1
Oliver Kurowski, @okurow](https://image.slidesharecdn.com/couchdbmapreduce-120614041014-phpapp01/85/CouchDB-Map-Reduce-10-320.jpg)
![Array-Key Map/Reduce Querying
startkey=[“Audi“] Key , Value
[Audi, A3, 2000] , 1
( &group=true) [Audi, A4, 2009] , 1
[VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1
[VW, Polo, 2010] , 1
startkey=[“VW“] Key , Value
[Audi, A3, 2000] , 1
( &group=true) [Audi, A4, 2009] , 1
[VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1
[VW, Polo, 2010] , 1
Key , Value
endkey=[“VW“] [Audi, A3, 2000] , 1
Remember:
Endkey is
(&group=true) [Audi, A4, 2009] , 1
not in
[VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1 resultlist
[VW, Polo, 2010] , 1
Oliver Kurowski, @okurow](https://image.slidesharecdn.com/couchdbmapreduce-120614041014-phpapp01/85/CouchDB-Map-Reduce-11-320.jpg)
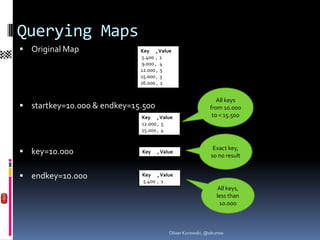
![Array-Key Map/Reduce Ranges
Step 4: Range queries: Key , Value
- startkey=[“VW“,“Golf“] [Audi, A3, 2000] , 1
[Audi, A4, 2009] , 1
- endkey= [“VW“,“Polo“] [VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1
- (&group=true) [VW, Polo, 2010] , 1
What, if we do not know the next model after Golf ?
- startkey=[“VW“,“Golf“] Key , Value
[Audi, A3, 2000] , 1
- endkey=[“VW“,“Golf“,99999] [Audi, A4, 2009] , 1
- (&group=true) [VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1
[VW, Polo, 2010] , 1
- better: endkey=[“VW“,“Golf“,{}]
Oliver Kurowski, @okurow](https://image.slidesharecdn.com/couchdbmapreduce-120614041014-phpapp01/85/CouchDB-Map-Reduce-12-320.jpg)
![Grouping with group_level
group=true Key , Value
[Audi, A3, 2000] , 1
(aka group_level=exact) [Audi, A4, 2009] , 1
[VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1
[VW, Polo, 2010] , 1
group_level=1 Key , Value
(no group=true needed) [Audi] , 2
[VW] , 3
group_level=2 Key , Value
[Audi, A3] , 1
(no group=true needed) [Audi, A4] , 1
[VW, Golf] , 2
[VW, Polo] , 1
group_level=3 -> group_level=exact -> group=true
Oliver Kurowski, @okurow](https://image.slidesharecdn.com/couchdbmapreduce-120614041014-phpapp01/85/CouchDB-Map-Reduce-13-320.jpg)
![Examples:
Get all car makes: Key , Value
[Audi] , 2
- group_level=1 [VW] , 3
Get all models from VW:
- startkey=[“VW“]&endkey=[“VW“,{}]&group_level=2
Key , Value
[VW, Golf] , 2
[VW, Polo] , 1
Get all years of VW Golf:
- startkey=[“VW“,“Golf“]&endkey=[“VW“,“Golf“,{}]&group_level=3
Key , Value
[VW, Golf, 2008] , 1
[VW, Golf, 2009] , 1
Oliver Kurowski, @okurow](https://image.slidesharecdn.com/couchdbmapreduce-120614041014-phpapp01/85/CouchDB-Map-Reduce-14-320.jpg)


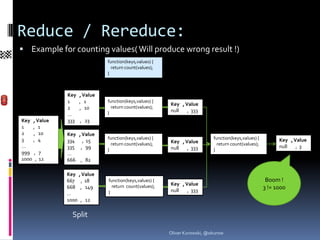

![Input of a reduce function:
The map: Doc._id , Key , Value
4 , “Audi“ , 12.000
2 , “BMW“ , 20.000
1 , “Citroen“ , 9.000
3 , “Dacia“ , 6.500
The function: function(keys ,values, rereduce) {
return sum(values);
}
Input Values 1 (rereduce=false):
- keys: [ [“Audi“,4],[“BMW“,2],[“Citroen“,1],[“Dacia“,3] ]
- values: [ 12.000,20.000,9.000,6.500]
- rereduce: false
Input Values 2 (rereduce=true):
- keys: null
- values: [47.500]
- rereduce: true
Oliver Kurowski, @okurow](https://image.slidesharecdn.com/couchdbmapreduce-120614041014-phpapp01/85/CouchDB-Map-Reduce-19-320.jpg)





Map/Reduce is a programming paradigm for parallel processing of large datasets. In CouchDB, Map/Reduce is implemented using JavaScript functions. The map function emits key-value pairs from input documents, and the reduce function combines these to produce final output. The map phase produces an intermediate result that can be optionally passed through the reduce phase or returned as-is. The reduce function may be rerun on partitioned results to produce the final output.
































































