Download as PDF, PPTX





![Why NoSQL
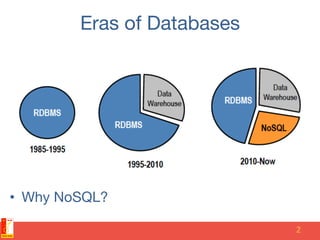
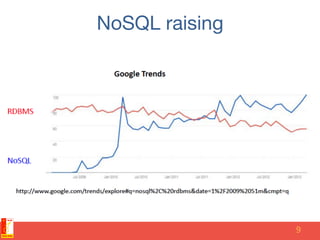
• “The whole point of seeking alternatives [to
RDBMS systems] is that you need to solve a
problem that relational databases are a bad
fit for.” Eric Evans - Rackspace
11](https://image.slidesharecdn.com/nosql-data-models-150216094551-conversion-gate01/85/Nosql-data-models-11-320.jpg)
![Why NoSQL [cont'd]
• ACID does not scale
• Web applications have different needs
– Scalability
– Elasticity
– Flexible schema/ semi-structured data
– Geographically distributed
• Web applications do not always need
– Transaction
– Strong consistency
– Complex queries
12](https://image.slidesharecdn.com/nosql-data-models-150216094551-conversion-gate01/85/Nosql-data-models-12-320.jpg)



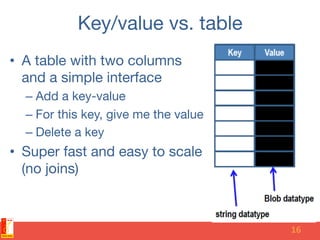

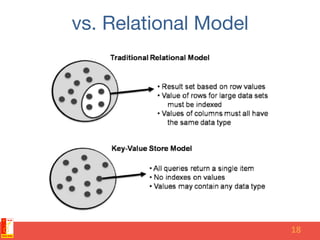





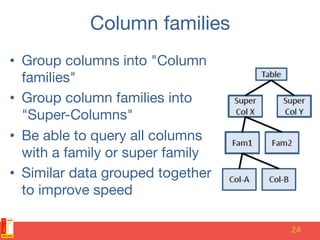
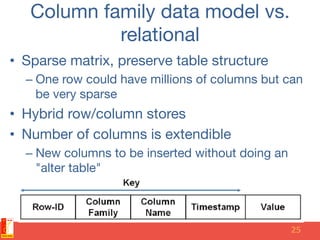




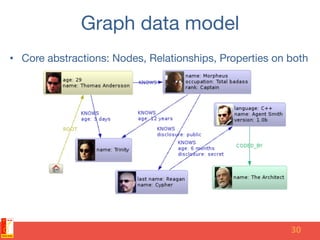








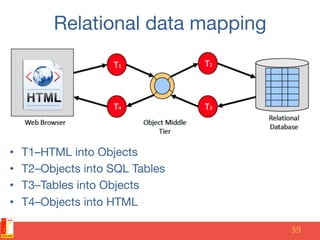
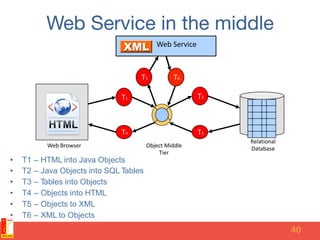

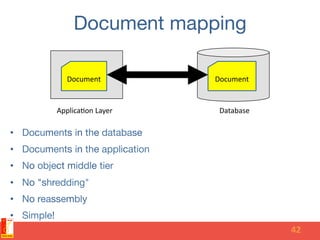



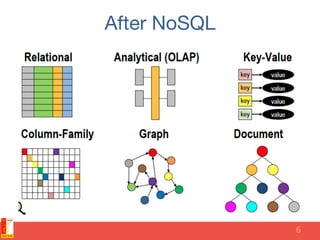
The document discusses different NoSQL data models including key-value, document, column family, and graph models. It provides examples of popular NoSQL databases that implement each model such as Redis, MongoDB, Cassandra, and Neo4j. The document argues that these NoSQL databases address limitations of relational databases in supporting modern web applications with requirements for scalability, flexibility, and high performance.











































































































