

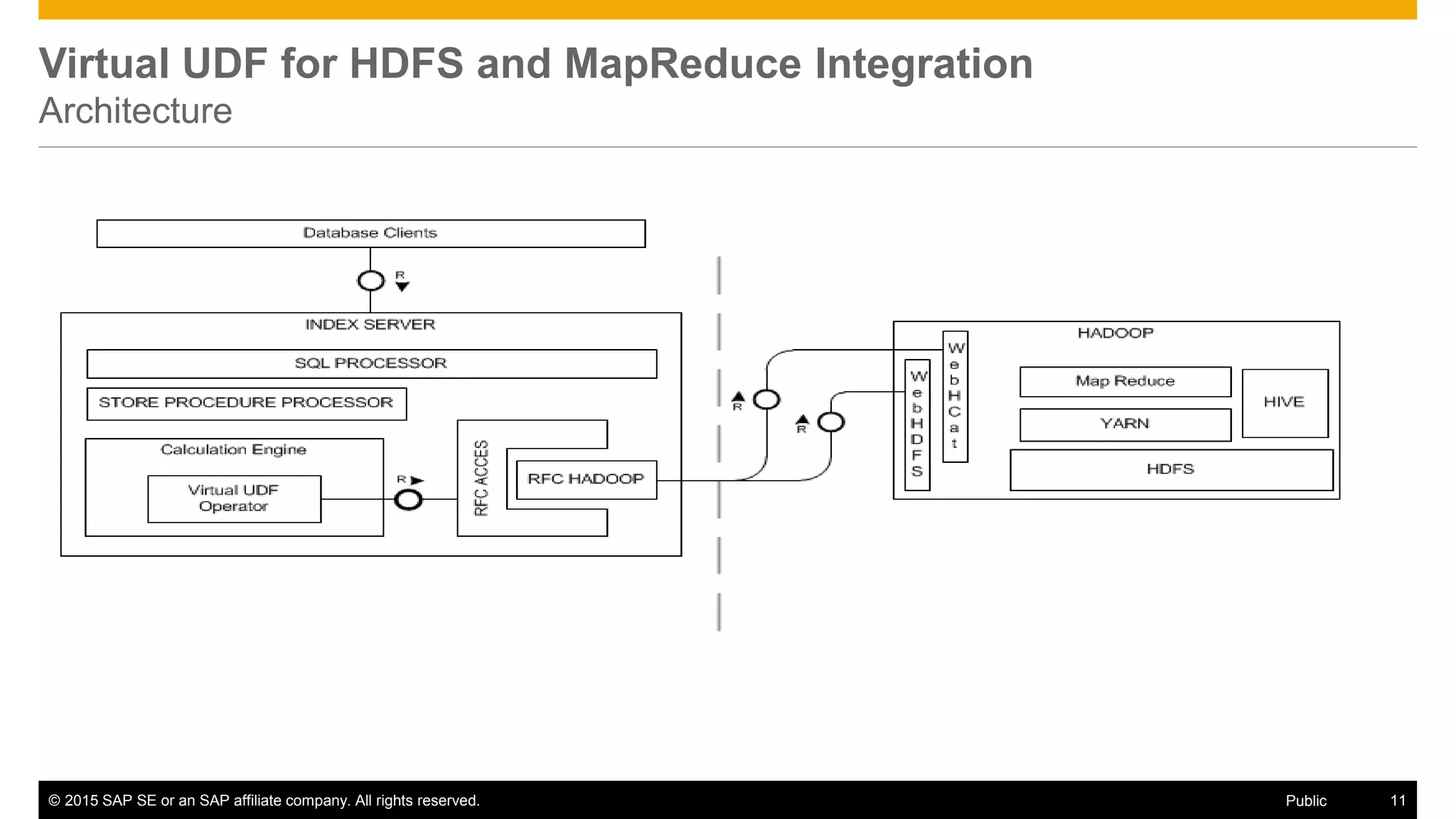
![© 2015 SAP SE or an SAP affiliate company. All rights reserved. 12Public
Virtual UDF for HDFS and MapReduce Integration
Syntax
Highlights
Syntax:
CREATE VIRTUAL FUNCTION <func_name> [(<parameter_clause>)]
RETURNS <return_table_type>
[SQL SECURITY <mode>]
[<package_clause>]
CONFIGURATION <remote_proc_properties>
AT <remote_source_name>;
Virtual Function Properties
– Can be used in-place of a table or derived table where the return clause represents the result-set
– Many configuration parameters depending on HDFS or MapReduce Job Call
– Points to a remote Hadoop cluster defined by the CREATE REMOTE SOURCE DDL](https://image.slidesharecdn.com/thurs1240sapjaviercuerva-150427180328-conversion-gate02/75/Leveraging-SAP-Hadoop-and-Big-Data-to-Redefine-Business-12-2048.jpg)









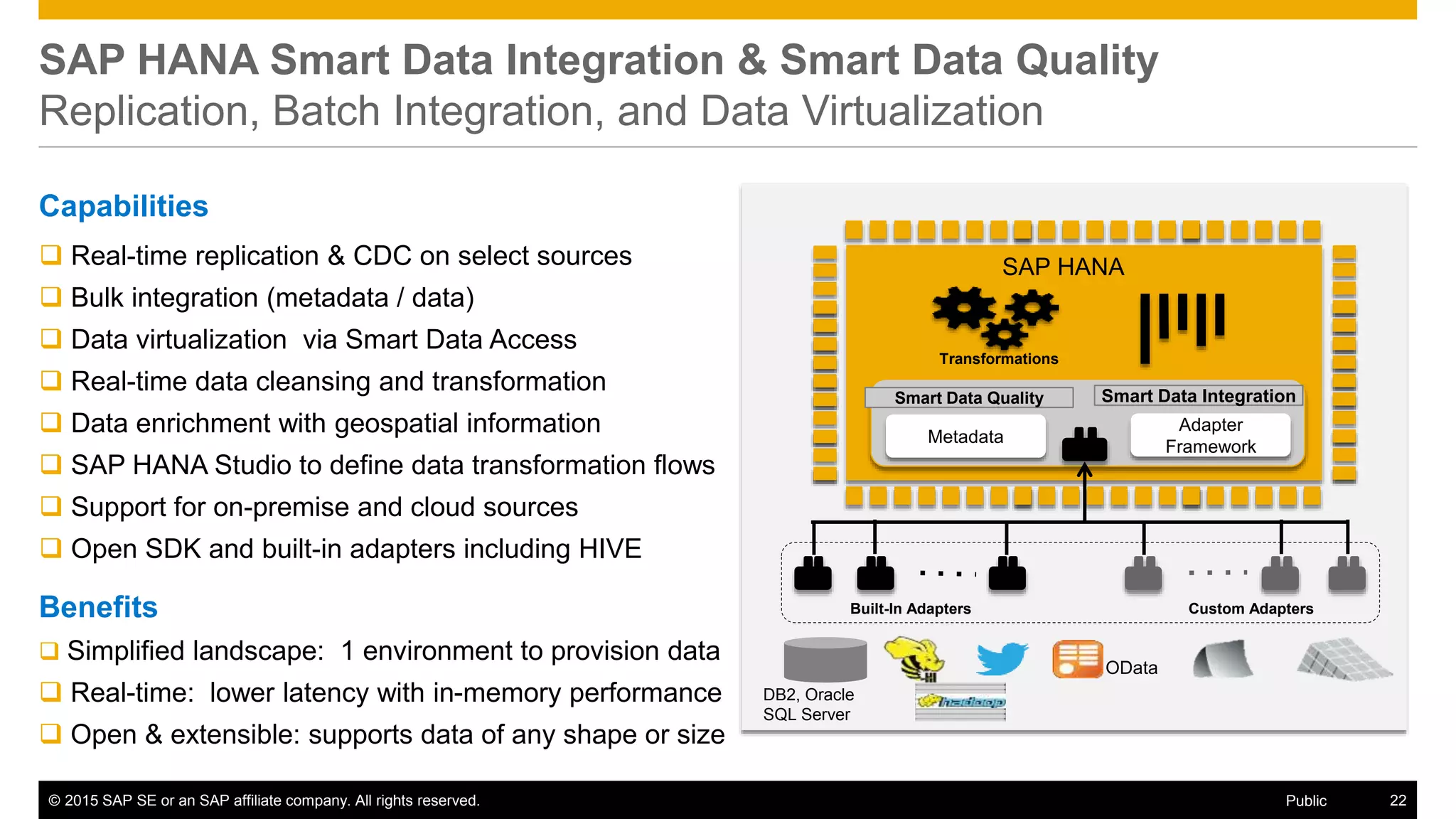
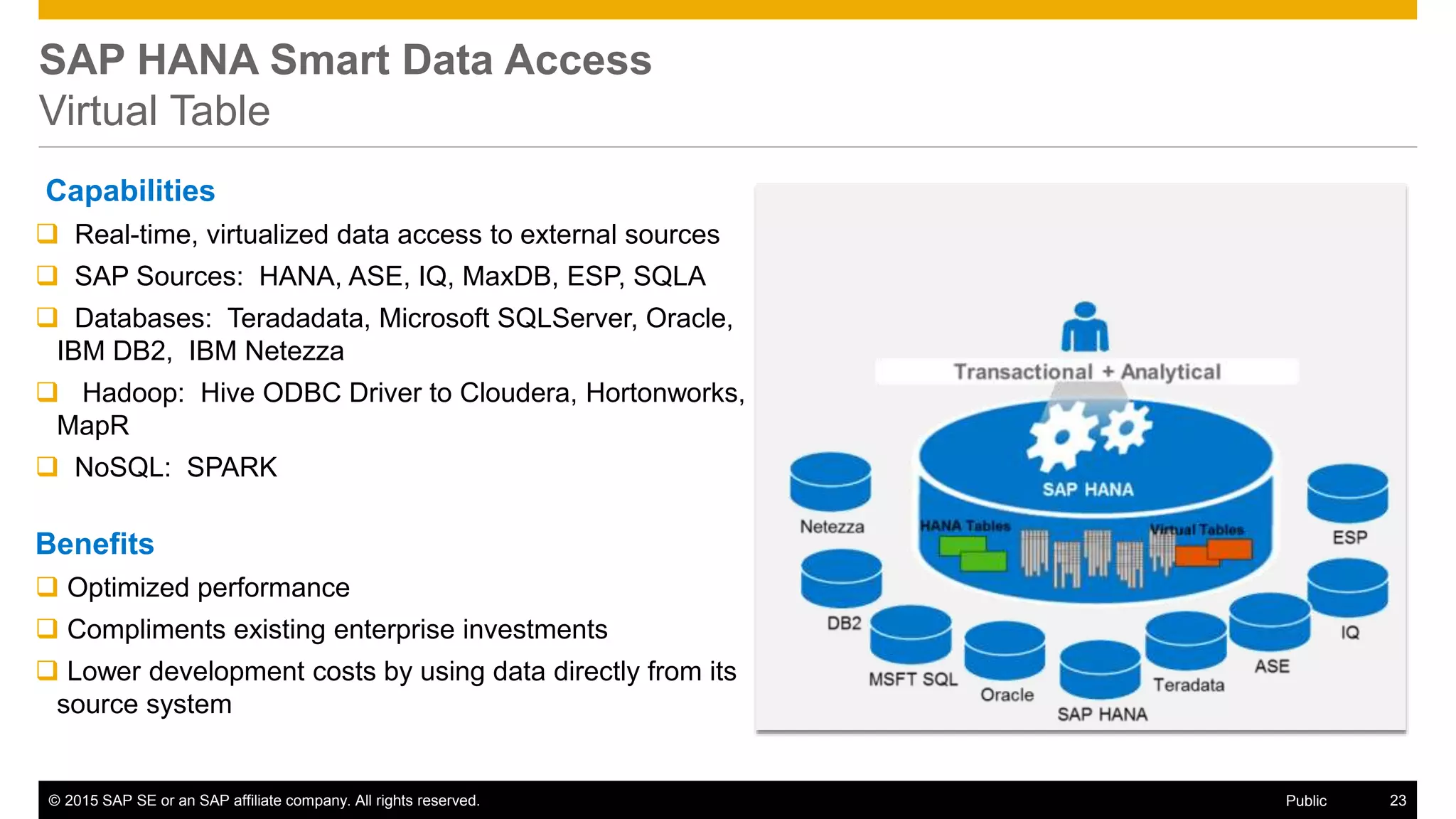

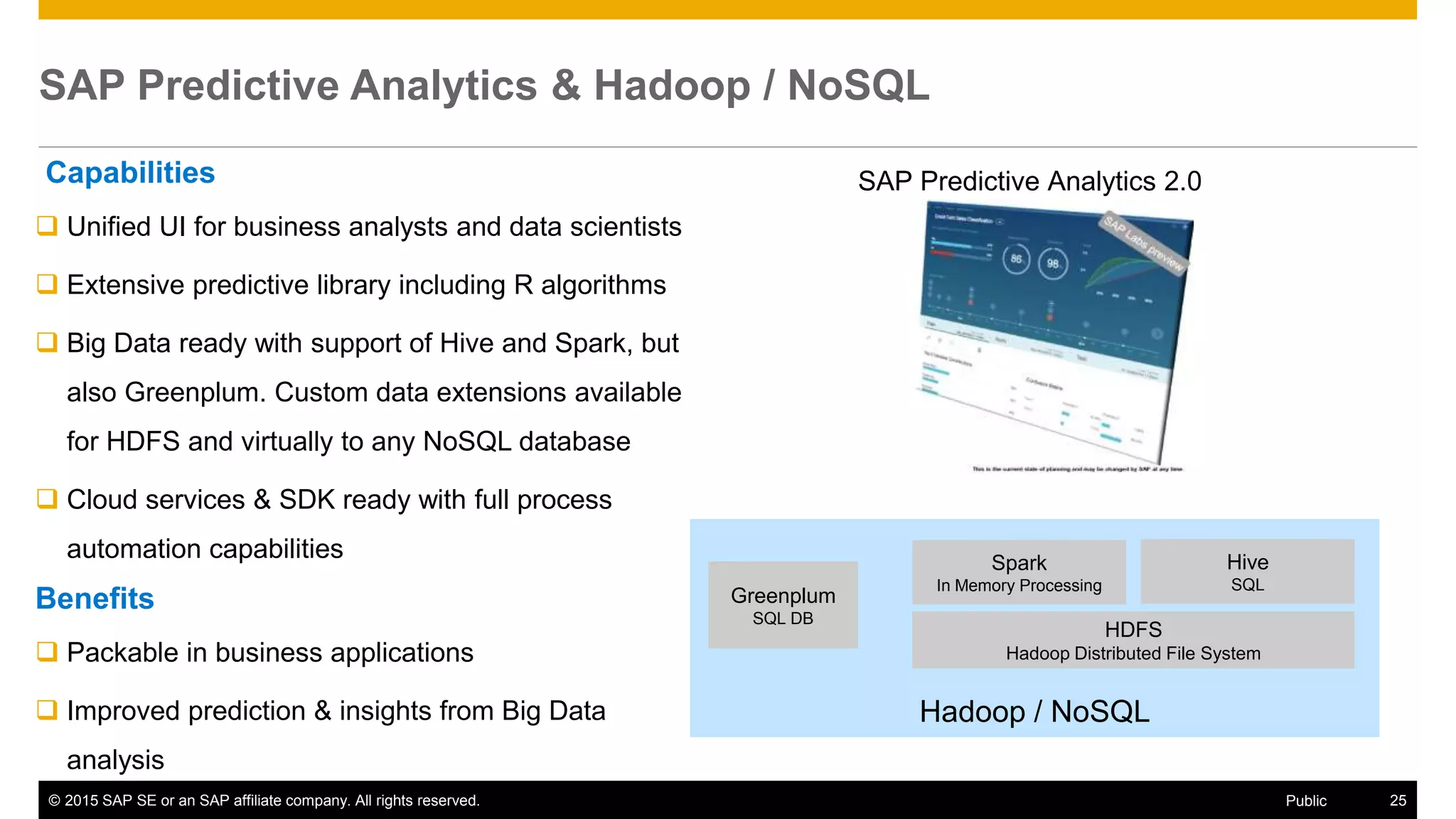

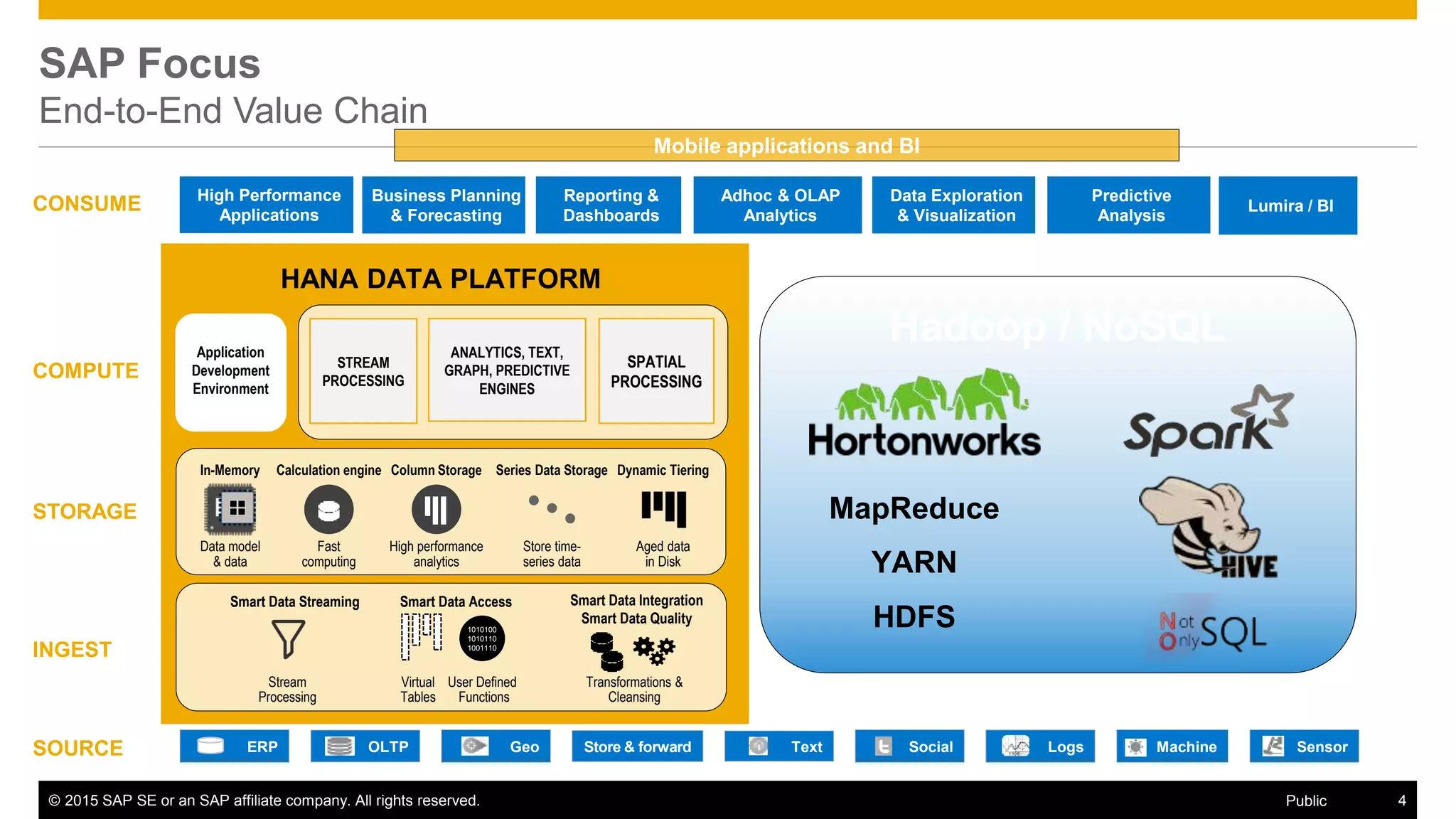
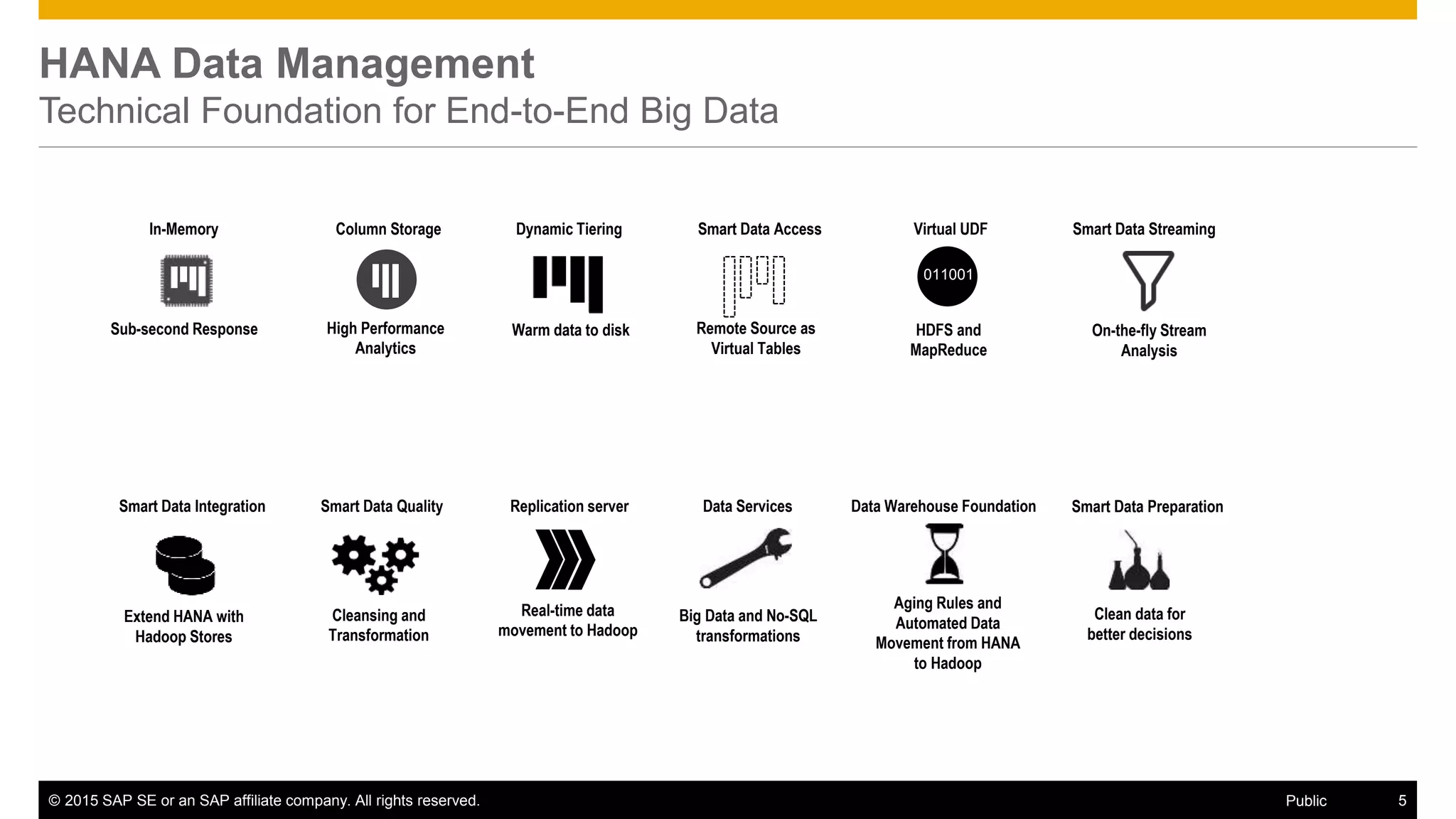
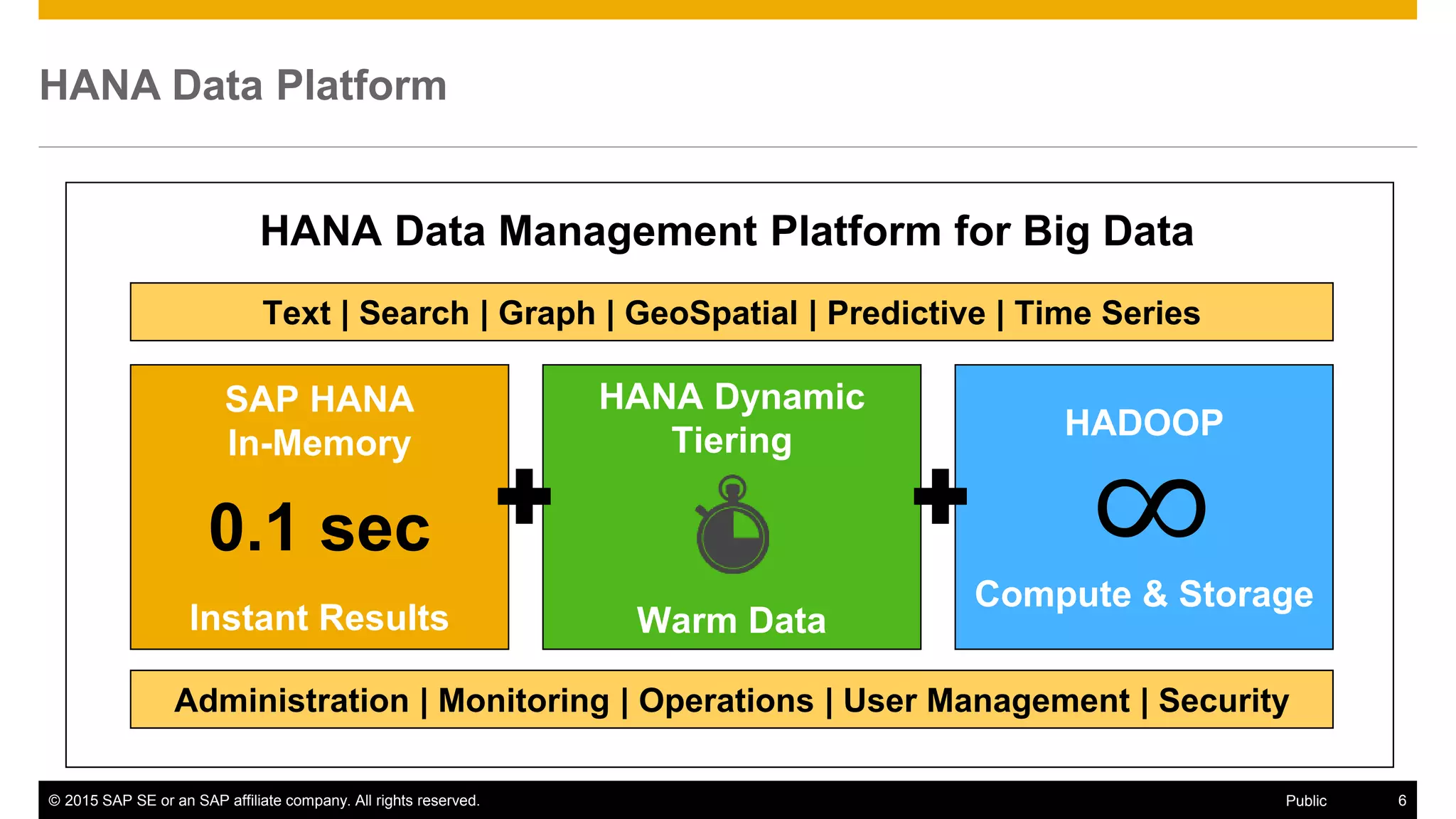
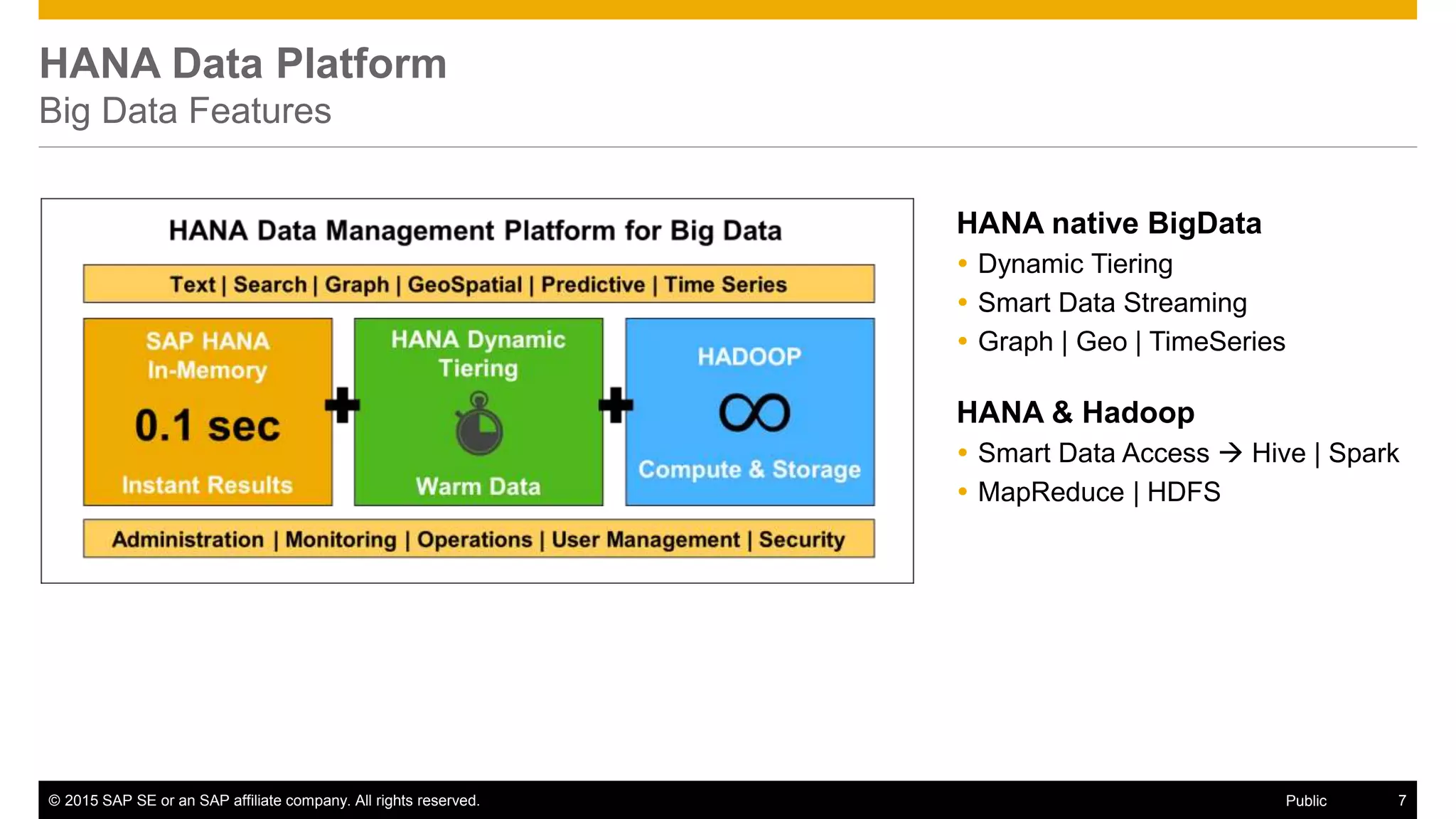
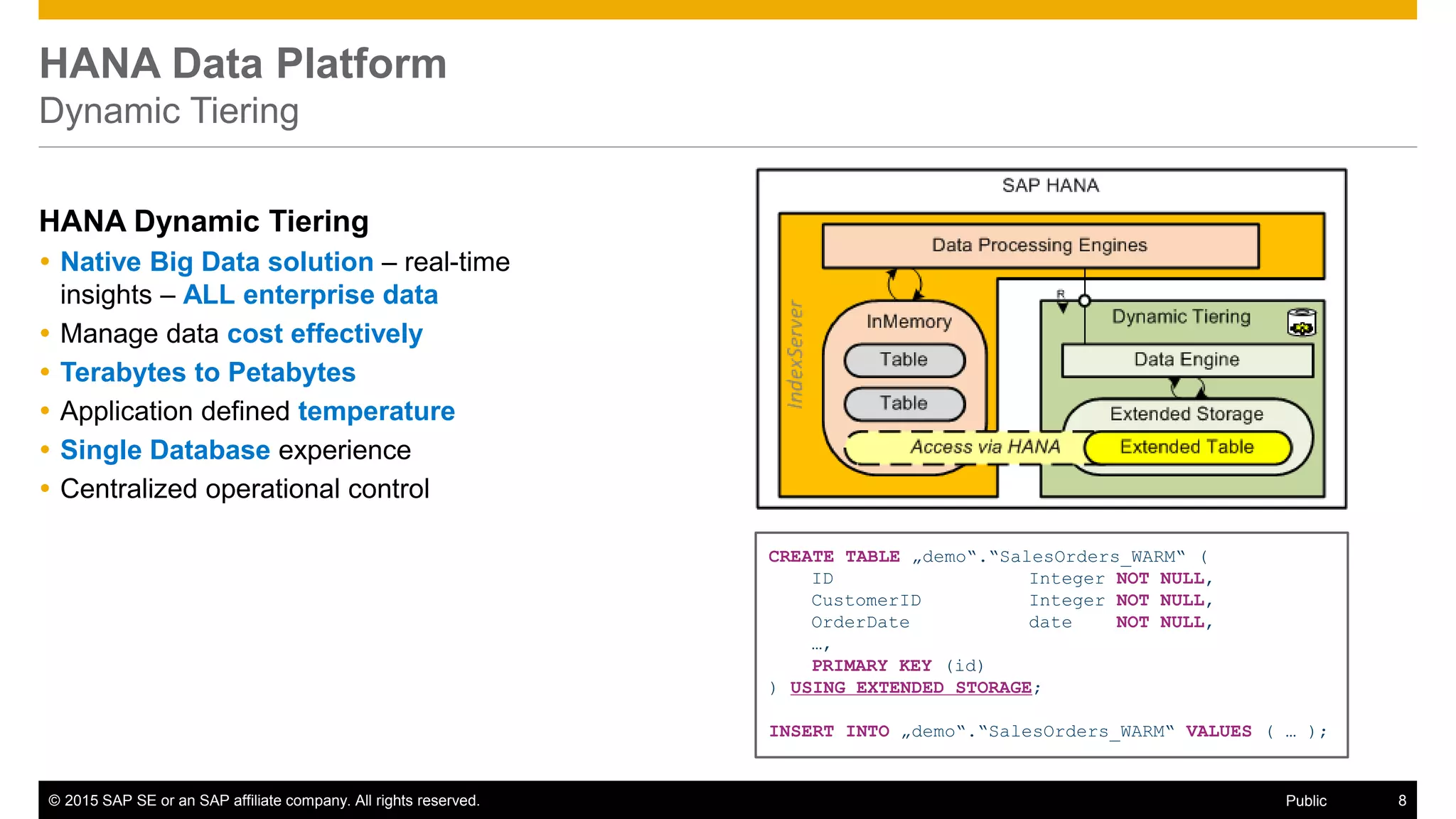
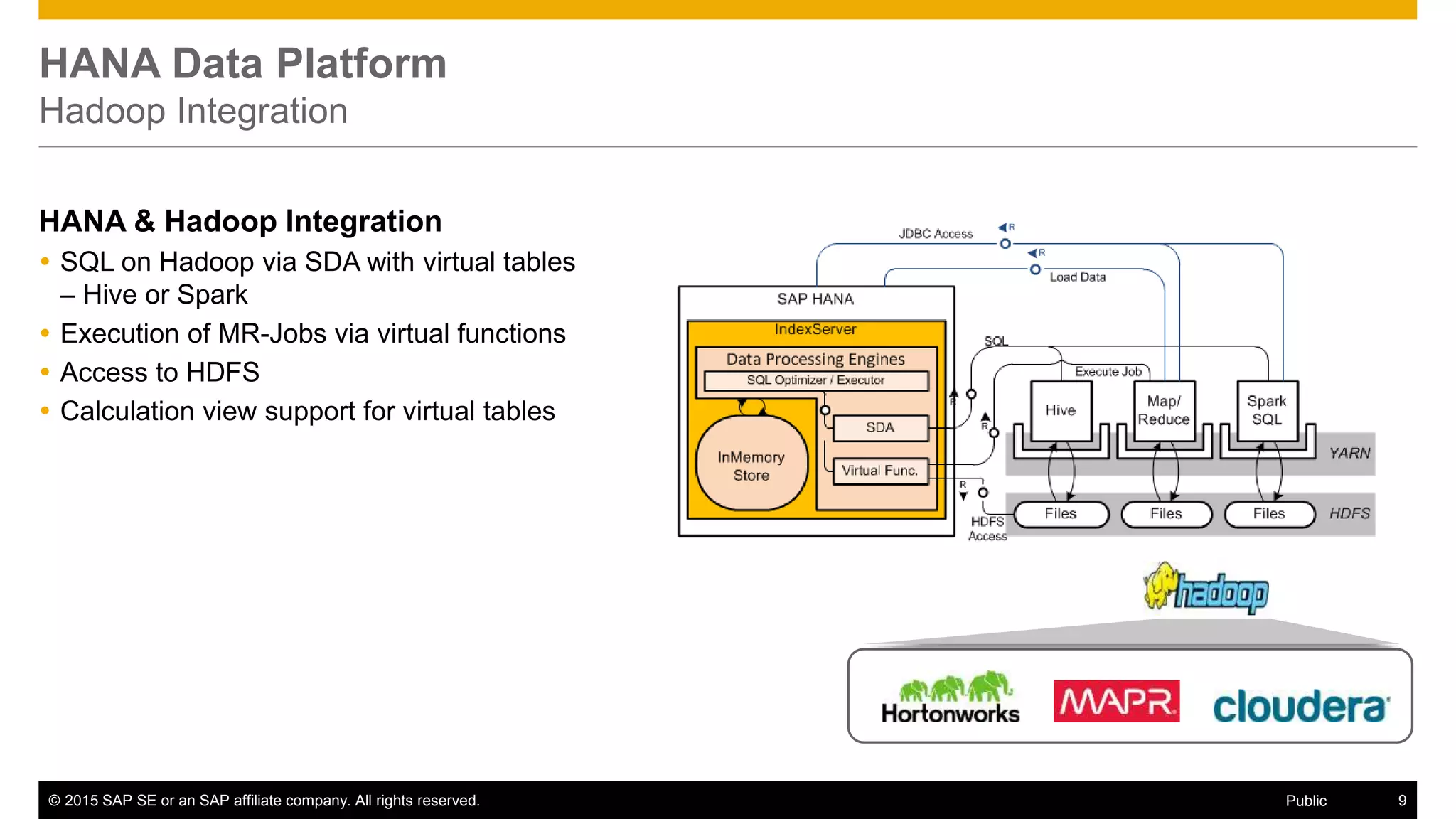
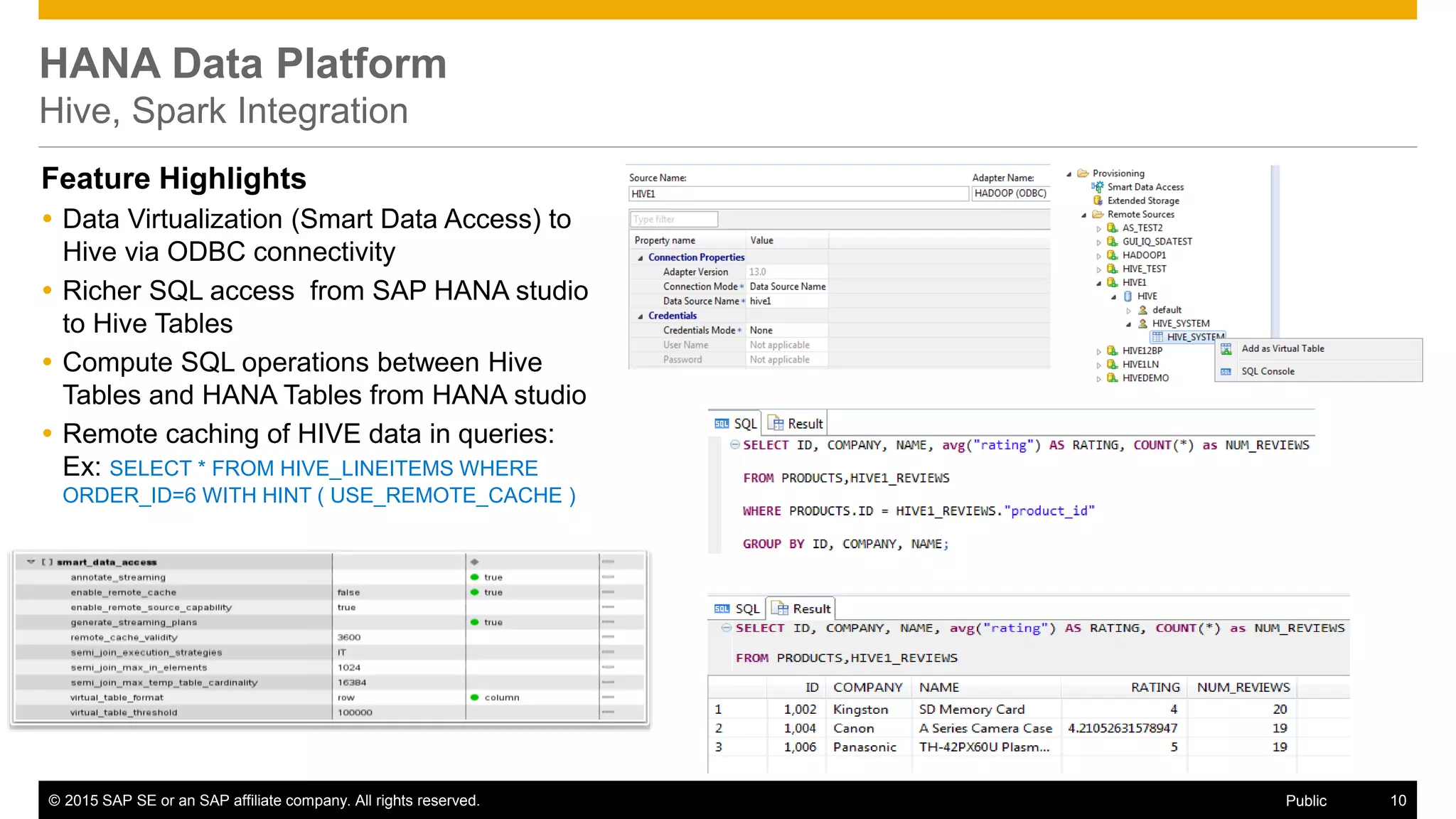
The document discusses leveraging SAP, Hadoop, and big data technologies to redefine businesses. It describes how the volume of digital data is exploding and includes both relational and non-relational machine-generated data. The document outlines how SAP focuses on providing an end-to-end value chain through its HANA data platform, which provides in-memory analytics, dynamic data tiering between HANA and Hadoop, smart data integration and quality features, and the ability to consume, compute and store data. Key features of HANA's integration with Hadoop include smart data access to Hive and Spark, support for MapReduce jobs, and access to HDFS.


















































































