Downloaded 15 times














![Document-oriented databases
• The central concept of a document store is the notion of a
"document". While each document-oriented database
implementation differs on the details of this definition, in general,
they all assume that documents encapsulate and encode data (or
information) in some standard formats or encodings. Encodings in
use include XML, JSON as well as binary forms like BSON.
• The most widely used solutions in no-sql are MongoDB and
CouchBase and both of them are document-oriented databases.
• Here is a sample document:
{
'_id' : '5897g42s0245afo4o473ai1e7',
'firstname': 'John',
'lastname': 'Doe',
'age': 26,
'sex': 'M',
'interests': [ 'Reading', 'Running', 'Hacking' ]
}](https://image.slidesharecdn.com/couchbase-150509081351-lva1-app6892/85/CouchBase-The-Complete-NoSql-Solution-for-Big-Data-15-320.jpg)
















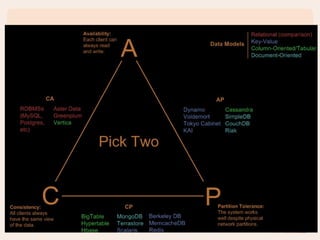
Couchbase is a complete NoSQL database solution for big data. It provides a distributed database that can scale horizontally. Couchbase uses a document-oriented data model and supports the CAP theorem. It sacrifices consistency to achieve high availability and partition tolerance. Couchbase is used by many large companies for applications that involve large, complex datasets with high user volumes and real-time requirements.



































































